Beginner's Guide to Getting Started With Stable Diffusion
This beginner's guide to Stable Diffusion is an extensive resource, designed to provide a comprehensive overview of the model's various aspects. Ideal for beginners, it serves as an invaluable starting point for understanding the key terms and concepts underlying Stable Diffusion.


This is a comprehensive guide to Stable Diffusion, aimed at absolute beginners. The blog covers an extensive range of topics related to Stable Diffusion. It serves as a one-stop resource for anyone starting out or looking to gain a holistic understanding of the model.
This blog post tackles the issue of scattered information, recognizing that there hasn't been a single, consolidated source for all things related to Stable Diffusion. Having said that, we will continue to update this blog post to ensure it reflects the most current information available. To aid in deeper exploration, the blog also includes backlinks to additional resources, allowing readers to delve into specific topics or concepts for more detailed study.
How Does Stable Diffusion Work?
Forward Diffusion
In this phase, an original image is subjected to a process where a calculated amount of random noise is incrementally added to it. This step-by-step addition of noise gradually degrades the image, moving it away from its initial state and towards a state of randomness.
Reverse Diffusion
This phase involves the reverse operation. The aim is to methodically remove the noise that was added in the Forward Diffusion phase. Through this denoising process, the model works to reconstruct the original content of the image. It's a meticulous process of restoring the image from its noise-induced state back to its clear, original form.
Stable Diffusion Architecture Overview
Autoencoder (VAE)
The Variational Autoencoder (VAE) is like a sophisticated resizing tool for images. It consists of two parts: the encoder, which compresses a standard image (like a 512x512 pixel photo) into a smaller, compact form called a "latent," and the decoder, which reverses this process, expanding the latent back to the original image size. This process is highly efficient, as working with smaller versions of images requires less memory and computing power, making it faster and more practical, especially for computers with limited resources. Essentially, the VAE makes complex image processing tasks more manageable by temporarily reducing image sizes.
U-Net
The U-Net works by modifying images by either adding or removing details. It works with the compact versions of images created by the autoencoder, and during the training phase, it either introduces noise (random visual information) to these images or cleans them by removing this noise. This ability to alter images is crucial for the system's learning process, enabling it to generate new, detailed images based on its training.
Text Encoder
The text encoder works as a translator that transforms words into images. When provided with text or descriptions, it interprets these words into a format that the system can utilize to either create new images or modify existing ones. This process enables the model to produce images that closely align with the given textual descriptions.
Schedulers
Schedulers, also commonly known as samplers, are integral algorithms in the denoising aspect of the Stable Diffusion workflow. These algorithms function by consistently executing denoising actions on the input, methodically introducing and eliminating random noise in each cycle. This process steadily enhances the image quality, ultimately yielding images that are noticeably refined and more distinct.
Stable Diffusion Base Models
Stable Diffusion 1.5
Released in the middle of 2022, the 1.5 model feature a resolution of 512x512 with 860 million parameters. It relies on OpenAI’s CLIP ViT-L/14 for interpreting prompts and is trained on the LAION 5B dataset. SD 1.5 is known for being beginner-friendly and excels in creating portraits. However, it tends to struggle with longer prompts and is limited by their lower resolution.
Stable Diffusion 2.1
The SD 2.1 model was introduced towards the end of 2022. It offer's an improved resolution of 768x768 and with 860 million parameters. The SD 2.1 use's LAION’s OpenCLIP-ViT/H for prompt interpretation and require more detailed negative prompts. It was trained on the LAION 5B dataset, supplemented with the LAION-NSFW classifier. Its's strengths include handling shorter prompts more effectively and producing images with richer colors. However, SD 2.1 generates images of medium-level resolution.
Stable Diffusion XL (SDXL 1.0 )
Launched in July 2023, the SDXL 1.0 represents a significant leap with a resolution of 1024x1024 and a massive 3.5 billion parameters. This model utilizes both OpenCLIP-ViT/G and CLIP-ViT/L for a more nuanced inference of prompts. The training data specifics are not mentioned. The SDXL 1.0 is known for its ability to work with shorter prompts and deliver high-resolution images. However, it is resource-intensive and requires a GPU, making it less accessible for users with limited hardware capabilities.
Stable Diffusion Model Types
Txt2Img (Text-to-Image)
Txt2Img Stable Diffusion models generates images from textual descriptions. The user provides a text prompt, and the model interprets this prompt to create a corresponding image.
Img2Img (Image-to-Image)
The Img2Img Stable Diffusion models, on the other hand, starts with an existing image and modifies or transforms it based on additional input. This could involve style transfer, where the artistic style of one image is applied to another, or it could involve modifying certain aspects of the image according to specified parameters or prompts
Stable Diffusion API
The Stable Diffusion API's allows developers to easily integrate the image generation capabilities of the Stable Diffusion models into their own software applications. It enables the automation of creating images based on text prompts, offering customizable options like image resolution and style. The API's simplifies accessing Stable Diffusion Models for image generation and is designed to handle multiple requests, making it scalable for various applications.
Stable Diffusion Model Formats
Checkpoints
These are the larger models responsible for the core image generation. They have been trained on extensive datasets, enabling them to generate a wide variety of images independently. Think of them as the main engine in image creation, capable of understanding and interpreting a range of inputs to produce diverse visual outputs.
LoRA's
These are smaller, more specialized models that work in conjunction with the checkpoints. They are designed to modify or enhance the outputs of the checkpoints. Their primary role is to introduce specific styles, characters, or concepts that the main checkpoint model might not know or might not render as effectively on its own. By integrating with a checkpoint, they allow for more nuanced and specialized image generation.
Distilled Stable Diffusion models
SSD-1B
Segmind Stable Diffusion-1B, a diffusion-based text-to-image model, is part of a Segmind's distillation series, setting a new benchmark in image generation speed, especially for high-resolution images of 1024x1024 pixels. Compared to its predecessor, the SDXL 1.0 model, SSD-1B boasts significant improvements: it's 50% smaller in size and 60% faster. This increase in speed and reduction in size is achieved with only a minimal compromise on image quality, maintaining a high standard close to that of the SDXL 1.0.
Segmind Vega
The Segmind Vega Model is a distilled version of the Stable Diffusion XL (SDXL), tailored for enhanced efficiency and speed. This model is a remarkable 70% reduction in size compared to SDXL, making it much more compact. Additionally, it boasts an impressive 100% increase in speed, effectively doubling the image generation speed. Despite these substantial improvements in size and speed, the Segmind Vega Model retains a high level of quality in text-to-image generation, demonstrating its capability to efficiently produce detailed and high-quality images.
How to generate images in Real-time with Stable Diffusion?
Segmind VegaRT
The Segmind VegaRT (Real-time) excels at efficient and fast AI image generation. This model is a distilled version of the LCM-LoRA adapter specifically designed for the Vega model. Its key innovation lies in the significant reduction of the number of inference steps needed to produce a high-quality image. Typically, AI image generation models require multiple steps to gradually build up the image detail and quality. However, with the Segmind VegaRT, this process is streamlined to require only between 2 to 8 steps. This reduction in steps allows the model to generate images at an exceptionally fast pace, essentially keeping up with the speed of inputing a text prompt. This advancement marks a substantial leap in real-time image generation capabilities, offering both speed and quality.
What is Stable Diffusion Fine-tuning?
Checkpoint Training
Checkpoint training expands a base Stable Diffusion model's capabilities by incorporating a new dataset focused on a specific theme or style. This method enhances the model's proficiency in areas like anime or realism, equipping it to produce content with a distinct thematic emphasis. It's particularly effective for instilling a desired bias in the model.
Dreambooth
Dreambooth training significantly improves a model's proficiency in generating images of a specific subject. It achieves this by utilizing a small set images, associating them with a unique token. This allows the model to render the subject in various styles and settings. An example of Dreambooth's application is integrating personal photos into the model, thus enabling it to create images featuring these specific subjects. Models trained via Dreambooth use a distinct keyword to navigate the image generation process.
LoRA
LoRA stands for Low-Rank Adaptation. LoRA models are streamlined adaptations of Stable Diffusion that implement minor but effective changes to the standard models. These models are considerably smaller, often many times less in size than full checkpoint models, making them suitable for handling numerous models. LoRA training balances efficiency and effectiveness, offering relatively smaller file sizes without significantly sacrificing training quality. Requiring a small set of images, LoRA training is a more efficient fine-tuning approach, modifying only a portion of the weights.
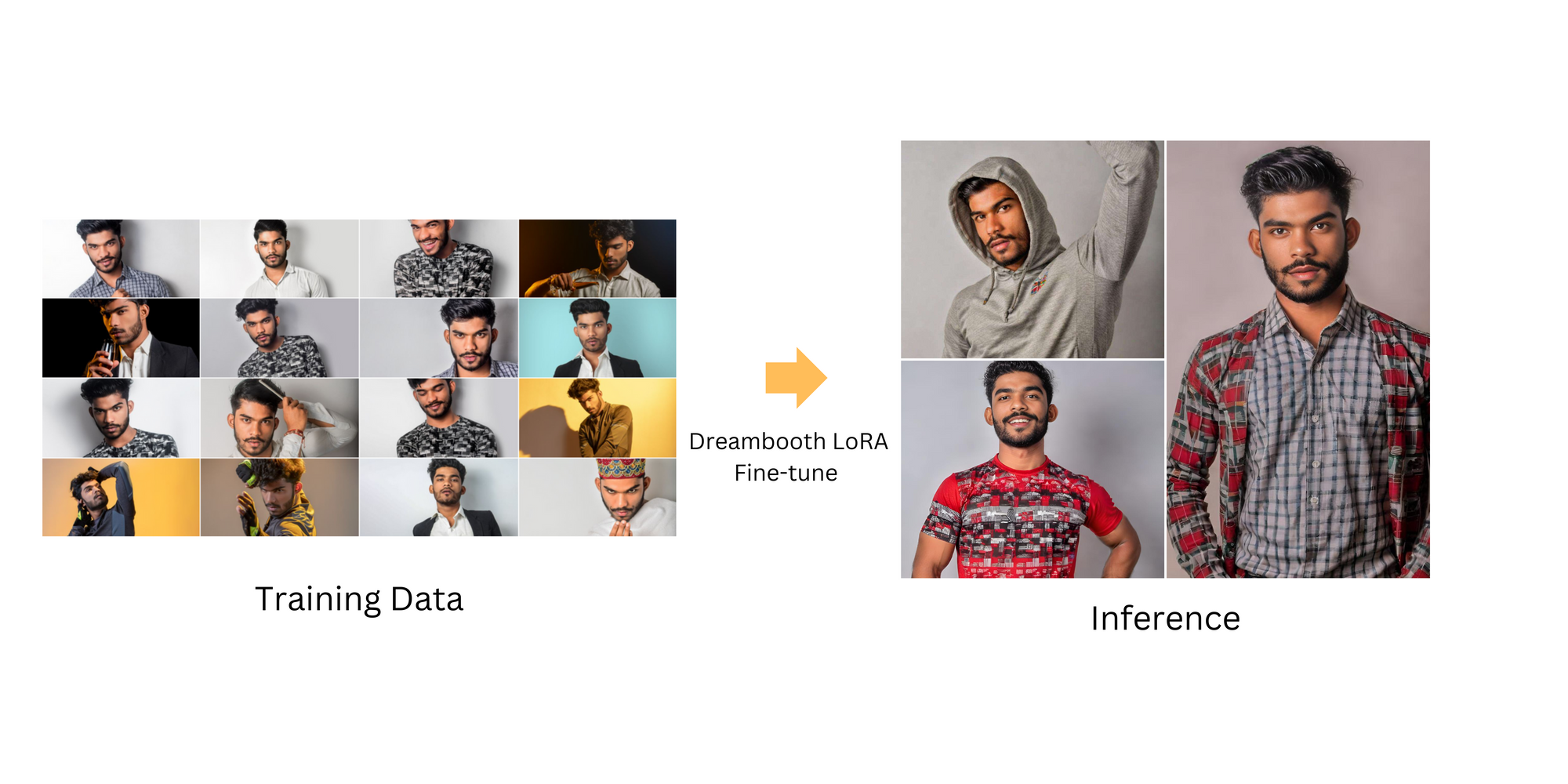
Dreambooth LoRA
Dreambooth LoRA, which combines Dreambooth fine-tuning on the base Stable Diffusion model with the subsequent extraction of the LoRA component. Initially, the base SD model is fine-tuned using a select set of images through Dreambooth, enhancing its ability to generate highly personalized and style-specific content. This is followed by extracting LoRA from the Dreambooth-trained checkpoint. The integration of Dreambooth and LoRA enables capability to efficiently produce high-quality, customized images, blending personalization with advanced rendering architecture.
Textual Inversion
Textual Inversion is a technique used in diffusion models like Stable Diffusion to teach the AI new associations between text and images. In this process, a pre-trained model is further trained by introducing a very small set of images along with their corresponding textual descriptions. This enables the model to establish new embeddings that link the provided text with the images. Essentially, it's a method of expanding the model's vocabulary and understanding, allowing it to generate images that are aligned with newly introduced concepts or terms. The training mimics the model's original reverse process of diffusion, where it learned to reconstruct images from noise, but in this case, it's learning to associate new text with specific images.
What are Different Stable Diffusion File Formats?
CKPT
CKPT stands for "checkpoint". A checkpoint file typically contains all the information about a trained model — this includes the model's weights, its architecture, and the state of the optimizer. These files are crucial for resuming training, transferring learning, or deploying the model for inference. CKPT files are directly used by the model for training or generating images. They are integral in various stages of model development and deployment. While CKPT files are versatile, there's a theoretical risk that they could contain malicious code, particularly if they are obtained from untrusted sources. This is because they can store custom operations or layers that might execute unwanted code.
Safetensors
Safetensors is a file format developed to address some of the potential security concerns associated with CKPT files. As the name suggests, it aims to ensure safety in tensor operations. CKPT files can be converted into Safetensors. This process involves extracting the essential information (like weights) from the CKPT files and storing them in a safer, more restricted format.The primary advantage of Safetensors is the increased security. By design, they are less likely to harbor malicious code, making them a safer option when using models from less verified sources. There are claims that models loaded from Safetensors may perform faster than those loaded from CKPT files. This could be due to optimizations in how the data is stored and accessed, though the actual performance gain can vary based on the specific implementation and use case.
Stable Diffusion Utility Models
Upscaling
Upscaling refers to the process of increasing the resolution of generated images to make them clearer and more detailed. This is particularly important because generative models like Stable Diffusion often produce images at lower resolutions due to computational constraints. Two popular upscaling techniques used in conjunction with Stable Diffusion are ESRGAN and Codeformer.


Segmentation
The "Segment Anything" model, as its name suggests, is designed for versatile and robust image segmentation tasks. Image segmentation is a crucial process in computer vision where an image is divided into different segments to simplify or change the representation of an image into something more meaningful and easier to analyze.

What are ControlNets in Stable Diffusion?
The fundamental usage of Stable Diffusion models is in the text-to-image format. Text prompts are used as the primary conditioning factor. These prompts guide the image generation process, ensuring that the produced images align with the text's description.
ControlNet introduces an additional layer of conditioning to this process, extending beyond just text prompts. This extra layer of conditioning in ControlNet can manifest in various forms. It allows for more nuanced and precise control over the image generation, giving users the ability to influence and direct the outcome in more specific ways than with text alone. This multi-conditioning approach significantly broadens the scope and capabilities of Stable Diffusion models in creating tailored and detailed images.
ControlNet Canny
Canny preprocessor extract the outlines of an image, effectively capturing its essential composition and structure. This feature is particularly useful for preserving the fundamental composition of the original image. By focusing on outlines, key shapes and forms, ensuring that the core visual elements are maintained
ControlNet Depth
Depth preprocessor estimates depth information from a given reference image. This conditioning is particularly adept at analyzing the visual cues within a two-dimensional image to deduce how far objects are from the viewer, effectively creating a depth map
ControlNet Open Pose
Open Pose conditioning detects human key points such as the positions of the head, shoulders, hands, and other body parts. It is particularly valuable for replicating human poses in images while omitting other specifics like outfits, hairstyles, and backgrounds, making it ideal for applications where the focus is on pose accuracy and not on other details
ControlNet Scribble
Scribble conditioning of Stable Diffusion, replicates the look and feel of a scribble drawing, achieving an artistic effect that mimics hand-drawn lines and strokes.
ControlNet Softedge
Soft Edge conditioning extract and highlight edges from images, creating sketch-like line drawings. It efficiently captures intricate details while filtering out noise, and then colorizes these extracted lines and contours to produce the final image.
MulticontrolNet
Multi-ControlNet, you use multiple conditioning's on Stable Diffusion at the same time. This means you can combine more than one of the above ControlNet conditionings to guide the creation of a single image. Essentially, it allows for more complex and layered instructions to be used in image generation, leveraging the strengths of multiple models simultaneously.
What is IP Adpater and how is it useful in Stable Diffusion?
Image Prompt
Image prompt (IP Image) is an image used as input to guide or influence the output of the model.
IP Adapter + Canny
Canny edge preprocessor, extracts outlines from images, aiding in maintaining the original composition. Combined with IP Adapter, merges elements from both prompts, with text providing further refinement. The outcome is complex, context-rich images that smoothly integrate visual aspects guided by the text prompt.

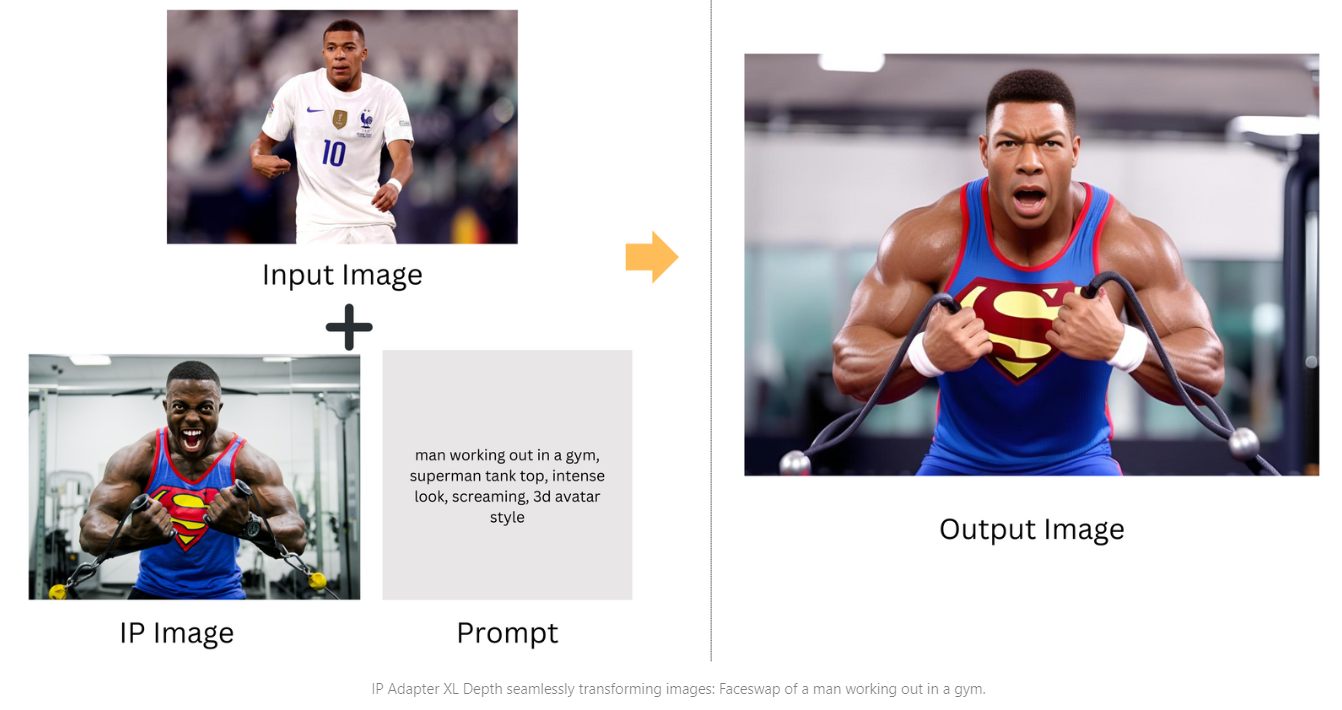
IP Adapter + Depth
Depth Preprocessor, extracts depth cues from images to grasp and recreate the scene's spatial dimensions. Combined with the IP adapter, it produces images that are detailed and have a rich sense of depth. This system merges elements from the original image and text prompts, with the text guiding the refinement process.
IP Adapter + Openpose
Open Pose Preprocessor, excels in detecting and analyzing human poses and gestures in images, crucial for accurately representing human figures and movements from the original scene. Working in conjunction with the IP Adapter, it enables the creation of visually striking images that are contextually rich, proving particularly effective in scenarios involving human subjects.

What is Stable Diffusion Inpainting ?
Inpainting involves four key components. The first is the Input Image, which is the original image subject to alteration or restoration. The quality and resolution of this image are crucial, as they significantly influence the final outcome. This image could vary from a photograph to a digital painting, or even a scan of a physical document. Next is the Mask Image, which is vital in the inpainting process. It acts as a guide, using a binary mask where white pixels indicate areas to be altered (the inpainting areas), and black pixels mark the regions to remain unchanged. Following this is the Prompt, comprising textual descriptions or instructions that direct the model on what to generate in the masked areas. For instance, a prompt like "a lush green forest" will lead the model to fill the masked area with imagery matching this description. The final component is the Output, which is the altered image where the masked areas are filled in or changed according to the prompt, ensuring a seamless blend with the unmasked parts of the original image.

What is Stable Diffusion Outpainting?

Inference
Prompt
A prompt is a set of textual instructions or descriptions provided to the model to guide the creation of an image. Prompts are crucial for steering the output of the model, as they define what the generated image should depict or represent. Some advanced models, such as those based on IP Adapter, allow for a combination of text and image prompts, enabling more complex and nuanced image generation.
Negative Prompt
Negative Prompt refers to any specific attributes or characteristics that you do not want to appear in the generated image. If you don't want the model to generate images with a certain feature, you can specify that in the negative prompt.
Steps
Steps is the number of inference steps the model will take to generate the output. Higher values can lead to more refined images, but it may take longer and consume more computational resources.
Guidance Scale
Guidance Scale is responsible for controlling the strength of the guidance from the input prompt. Higher values would result in a stronger emphasis on the input text prompt, possibly leading to a more accurate representation of the prompt in the output image.
Seed
Seed is a random seed number that is used to initialize the random number generator for the model. This seed number ensures that the model will generate the same output if it is run with the same inputs and parameters in the future. It's a useful tool for reproducibility.
Styles
In Stable Diffusion XL, you have a rich palette of diverse styles to choose from, allowing you to dictate the visual language of your output. Whether you're aiming for the sharp realism of photography, the playful and exaggerated features of a cartoon, the defined and minimalist strokes of line art, or the geometric simplicity of low poly, the choice is yours. Each style brings its own flavor, transforming the same prompt into vastly different visual experiences. It's like choosing between oil paints, watercolors, charcoal, or pastels for a piece of art. Your chosen style can dramatically influence the mood, tone, and impact of the final image.
{
"prompt": "cinematic film still, 4k, realistic, ((cinematic photo:1.3)) of panda wearing a blue spacesuit, sitting in a bar, Fujifilm XT3, long shot, ((low light:1.4)), ((looking straight at the camera:1.3)), upper body shot, somber, shallow depth of field, vignette, highly detailed, high budget Hollywood movie, bokeh, cinemascope, moody, epic, gorgeous, film grain, grainy",
"negative_prompt": "ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, signature, cut off, draft",
"style": "base",
"samples": 1,
"scheduler": "UniPC",
"num_inference_steps": 25,
"guidance_scale": 8,
"strength": 0.2,
"high_noise_fraction": 0.8,
"seed": 468685,
"img_width": 1024,
"img_height": 1024,
"refiner": true,
"base64": false
}
We will continue to update this blog post to ensure it reflects the most current information available. Feel free check various Stable Diffusion Models available on Segmind.