Scaling Down for Speed: Introducing SD-Small and SD-Tiny Stable Diffusion Models
In the Segmind Distilled Stable Diffusion series, we're excited to open-source the Knowledge Distillation Code and Weights of our new compact models: SD-Small and SD-Tiny.


The Need for Speed: Knowledge Distillation
In recent months, we've witnessed a surge in the development of increasingly larger language models, such as GPT-4, Falcon 40B, LLaMa-2 70B, and others. This trend towards larger, more intelligent, and generalized models has increased the complexity and computational power required to run them.
At Segmind, we're committed to making generative AI models faster and more affordable. Last year, we open-sourced our accelerated SD-WebUI library, voltaML. This AITemplate/TensorRT-based inference acceleration library has delivered a 4-6X increase in inference speed.
Continuing our mission, we're now open-sourcing the weights and training code of our compact SD models: SD-Small and SD-Tiny. You can find the pre-trained checkpoints on Huggingface.

Drawing Inspiration from Architectural Compression Research
Our work on the SD-Small and SD-Tiny models is inspired by the groundbreaking research presented in the paper "On Architectural Compression of Text-to-Image Diffusion Models." This study underscores the potential of architectural compression in text-to-image synthesis using Stable Diffusion models. The researchers introduced block-removed knowledge-distilled SDMs (BK-SDMs), achieving over a 30% reduction in parameters, MACs per sampling step, and latency. Despite being trained with limited resources, their compact models demonstrated competitive performance against larger models in the zero-shot MS-COCO benchmark. They also successfully applied their pre-trained models in a personalized generation. We acknowledge and appreciate the significant contributions of this research, which has been instrumental in guiding our own work. Our efforts to further optimize and enhance these models are a testament to the transformative potential of their foundational research.
Knowledge Distillation: A Closer Look
Our new compact models leverage Knowledge-Distillation (KD) techniques. In a nutshell, KD is like a teacher guiding a student step-by-step. A large teacher model is pre-trained on a large amount of data. Then, a smaller model is trained on a smaller dataset, aiming to imitate the outputs of the larger model while also learning from the dataset.
We've trained two compact models using the Huggingface Diffusers library: Small and Tiny. These models have 35% and 55% fewer parameters than the base model, respectively, while maintaining comparable image fidelity. You can find our open-sourced distillation code in this repo and pre-trained checkpoints on Huggingface.
In this particular type of knowledge distillation, the student model is trained to do the normal diffusion task of recovering an image from pure noise, but at the same time, the model is made to match the output of the larger teacher model. The matching of outputs happens at every block of the U-nets, hence the model quality is mostly preserved. So, using the previous analogy, we can say that during this kind of distillation, the student will not only try to learn from the Questions and Answers but also from the Teacher’s answers, as well as the step-by-step method of getting to the answer. We have 3 components in the loss function to achieve this, firstly the traditional loss between latents of the target image and latents of the generated image. Secondly, the loss between latents of the image generated by the teacher and latents of the image generated by the student. And lastly, and the most important component, is the feature level loss, which is the loss between the outputs of each of the blocks of the teacher and the student.
Combining all of this makes up Knowledge-Distillation training. Below is an architecture of the Block Removed UNet used in the KD as described in the paper.
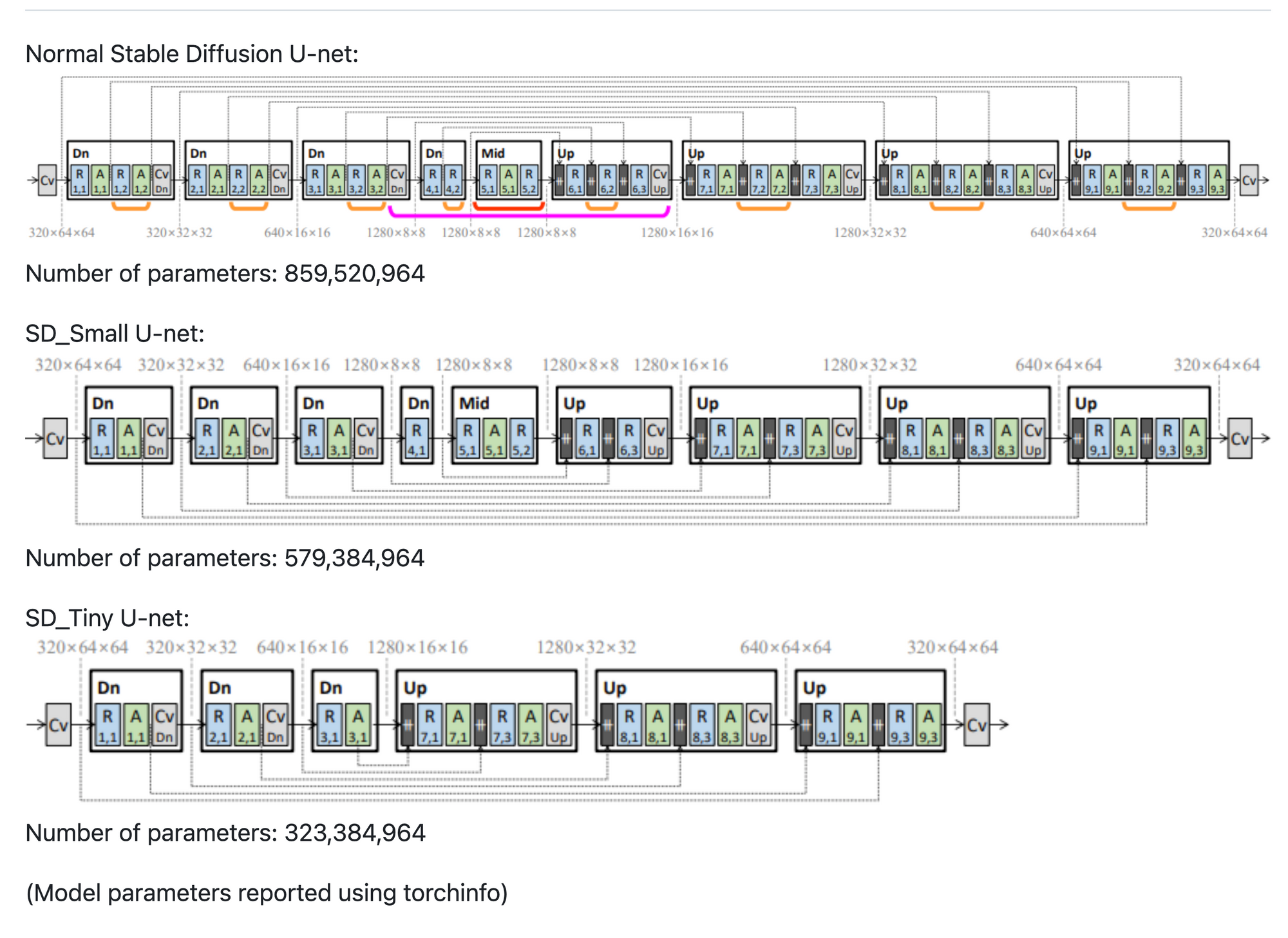
We have taken Realistic-Vision 4.0 as our base teacher model and have trained on the LAION Art Aesthetic dataset with image scores above 7.5, because of their high quality image descriptions. Unlike the paper, we have chosen to train the two models on 1M images for 100K steps for the Small and 125K steps for the Tiny mode respectively. The code for the distillation training can be found here.
Speed Matters: Inference Latency
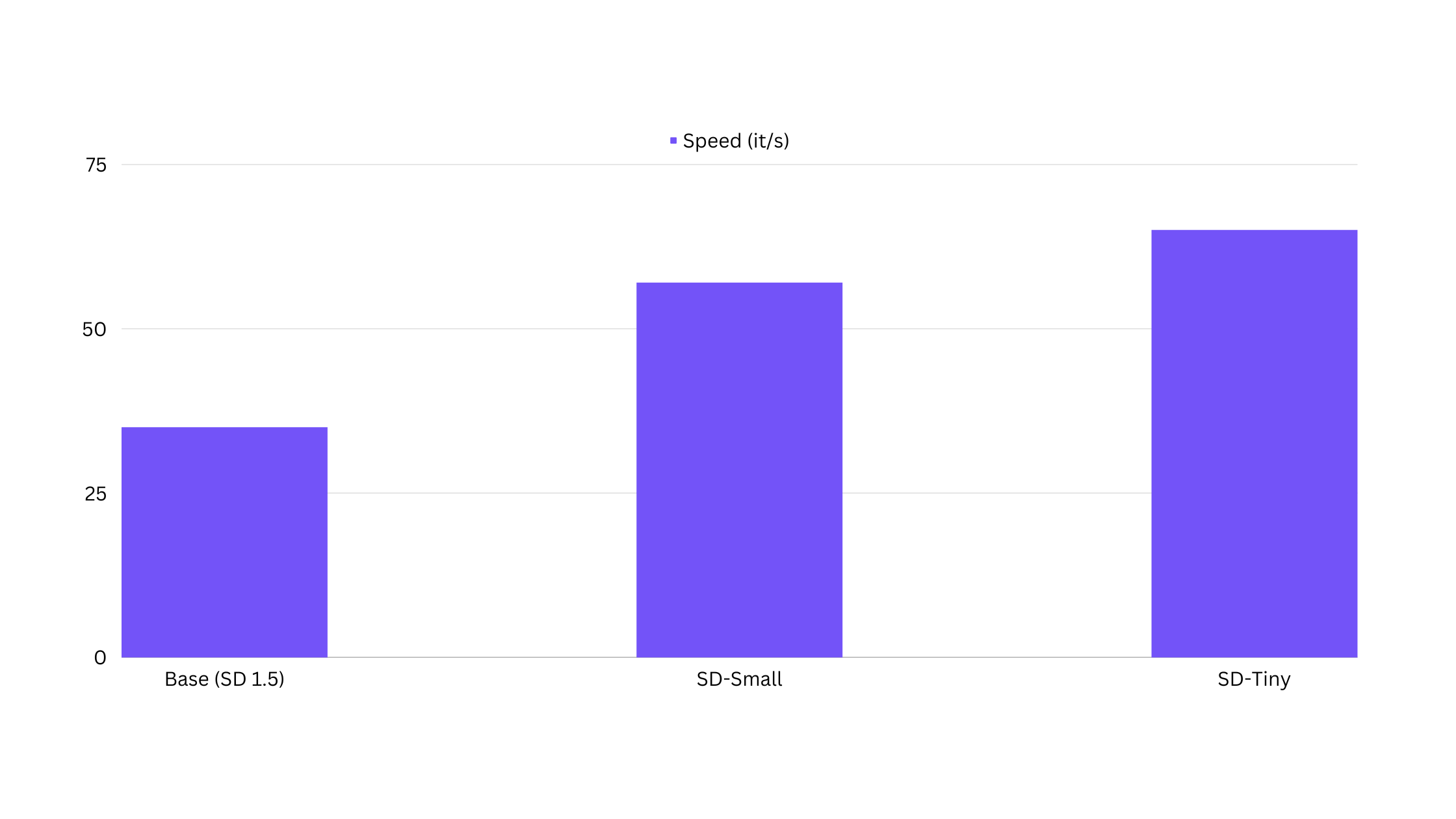
One of the most notable benefits is the speed of inferences. Our models are designed to deliver inferences that are 85% faster, which can drastically reduce the time it takes to generate results. We tested the models on NVIDIA A100 (80GB) GPUs for this benchmarking.
In addition, these models have a VRAM footprint that is up to 30% lower. This reduction in memory usage makes our models more efficient and accessible, especially for systems with limited resources. Furthermore, our distilled models facilitate faster DreamBooth and LoRA training. This means you can fine-tune these models or train them on specific concepts or styles more quickly, saving valuable time and resources. These advantages underscore our commitment to developing AI models that are not only powerful and accurate but also efficient and user-friendly.
Fine-tuning the SD-Tiny Model
We've fine-tuned our SD-Tiny model on portrait images generated with the Realistic Vision v4.0 model. The fine-tuning parameters used are as follows:
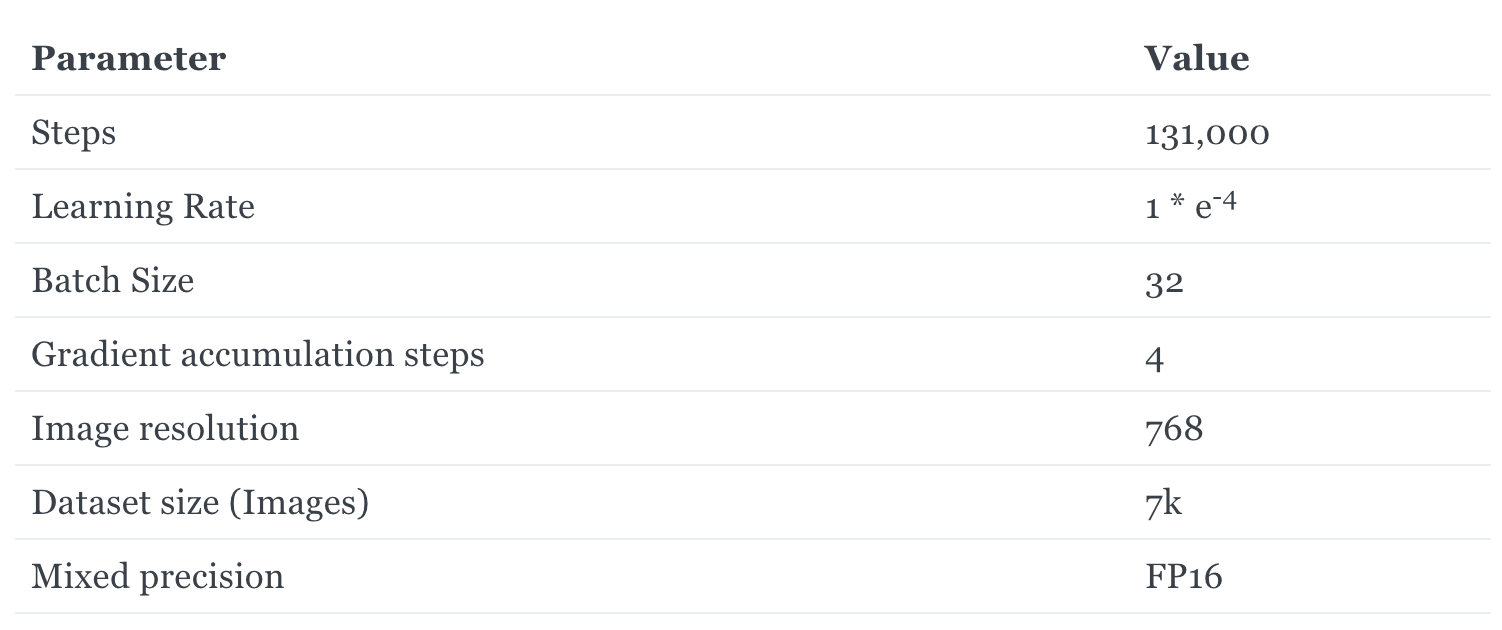
The results are impressive, with image quality close to the original model, but with almost 40% fewer parameters. You can find the code for fine-tuning the base models here.

LoRA Training
One of the advantages of LoRA training on a distilled model is faster training. We've trained the first LoRA on the distilled model on some abstract concepts. You can find the code for the LoRA training here.

Limitations
While we are excited about the potential of our distilled models, it's important to acknowledge that they are still in the early stages of development. As such, the outputs may not yet meet production quality standards. Furthermore, these models are not designed to be the best general models. Instead, they excel when fine-tuned or LoRA trained on specific concepts or styles. This makes them highly adaptable and specialized, but it also means they may not perform as well in more generalized tasks. Additionally, our distilled models currently have limitations in terms of composability and handling multiple concepts. We are actively working on these areas for improvement, and we appreciate your understanding and patience as we continue to refine and enhance these models.
Use Tiny-SD and Small-SD with Segmind serverless APIs
The fastest way to get started with these models is through our serverless APIs. Sign up today to take advantage of the free 100 credits per day to try the models for free. Beyond the free limits, these API endpoints are priced per image generation and are significantly cheaper compared to many stable diffusion APIs. Our serverless APIs are a great option for quickly prototyping AI-Powered features.
Future work
As we continue to advance our work on the Segmind Distilled Stable Diffusion series, we have an exciting roadmap ahead. One of our key future endeavors includes working on the SDXL distilled models and code. We believe that distilling these larger models will allow us to maintain high performance while significantly reducing computational requirements, making these powerful tools more accessible for a wider range of applications.
In addition, we plan to further fine-tune our SD-1.5 base models. Our goal is to enhance their composability and generalization capabilities, which will allow them to adapt to a broader array of tasks and datasets. We're also looking forward to applying Flash Attention-2, which we anticipate will expedite the training and fine-tuning processes. To further accelerate our models, we plan to implement TensorRT and/or AITemplate, which are known for their ability to boost inference speed.
Lastly, we're exploring the potential of Quantization-Aware-Training (QAT) during the distillation process. By simulating the effects of quantization during training, we hope to create models that are not only smaller and faster but also maintain high levels of accuracy when deployed in real-world, resource-constrained environments.
We're excited about the potential of these developments and look forward to sharing our progress with the community. Stay tuned for more updates as we continue to push the boundaries of what's possible with generative AI models. Sign up for a demo here. And stay tuned for many more models to come in our Distillation Series!
Open-source collaboration
We invite the open-source community to help us improve and achieve wider adoption of these distilled SD models. Join the Segmind Discord server for the latest updates, new checkpoints, and exciting new LoRAs. If you like our work, please give us a star on GitHub.
Customize Tiny-SD and Small-SD with Segmind Training
Tiny-SD, Small-SD, and the SDXL come with strong generation abilities out of the box. But for the best performance on your specific task, we recommend fine-tuning these models on your private data. This process can be done in hours for as little as a few hundred dollars. Contact us to learn more about fine-tuning stable diffusion for your use cases.