IP Adapter SDXL Models: Canny, Depth & Openpose
IP Adapter XL models (Canny, Depth & Openpose), offer enhanced capabilities to transform images seamlessly. Learn more about these models in this blog post.


Segmind has introduced new models, IP Adapter XL models (Canny, Depth & Openpose), which offer enhanced capabilities to transform images seamlessly. These models are built on the SDXL framework and incorporate two types of preprocessors that provide control and guidance in the image transformation process. One type is the IP Adapter, and the other includes ControlNet preprocessors: Canny, Depth, and Openpose.
Unlike other models, IP Adapter XL models can use image prompts in conjunction with text prompts. The fundamental concept is that the IP adapter processes the image prompt (or IP image) and the text prompt, combining features from both to create a modified image. This image is then blended with the input image processed by a preprocessor (like Canny, Depth, or Openpose), resulting in an image that incorporates elements from each image, guided by the text prompt.

How do IP Adapter XL Models Transform Images?
Let's try to understand the inner workings of the IP Adapter XL model's workflow.
1.Input Image: The process begins with an input image, which will serve as the subject of the modifications.
2. Preprocessors on Input Image:
Canny Preprocessor: Applies edge detection to highlight edges and contours in the image, maintaining structural clarity for further processing. Depth Preprocessor: Analyzes depth information within the image to understand spatial relationships and dimensional aspects. OpenPose Preprocessor: Identifies human poses and figures, mapping positions and orientations of body parts if present.
3. Image Prompt (IP Image) and Text Prompt:
IP Image: A secondary image, such as a specific scene/background/person, etc, is provided as an image prompt, setting the context for the final composition. Text Prompt: A descriptive text accompanies the IP image, specifying desired transformations or integrations within the image prompt.
4. IP Adapter Processing with Prompt Image and Text Prompt:
The IP Adapter processes the prompt image and the text prompt, integrating contextual information from both. The image and text prompts are processed through separate encoders, converting the IP image into image features and the text prompt into text features. These features are then merged by the IP Adapter, aligning text-based modifications with the image. The IP Adapter uses the combined features to start creating a modified image, iteratively refining it based on the text description.
5. Feature Integration and Synthesis:
The detailed information from the preprocessors (Canny, Depth, OpenPose) is integrated with the processed prompt image and text features. The synthesis stage combines these elements, integrating the subject into the new scene with considerations for edges, depth, and human poses.
6. Output Image:
The final output is an image that creatively blends the subject into the new scene as dictated by the text prompt. The subject retains its clarity and detail, ensuring it looks naturally placed in the new environment, in alignment with the specific instructions of the text prompt.
IP Adapter Canny XL
The IP Adapter and the Canny edge preprocessor enhance the capabilities of the SDXL model by providing additional control and guidance. The Canny edge preprocessor extracts the outlines of the input image, aiding in retaining the composition of the original image. The IP adapter enables the SDXL model to utilize an image prompt in conjunction with a text prompt, combines both features in creating a modified image, and iteratively refining it based on the text prompt. This combination results in the creation of intricate and context-rich images, skillfully merging aspects from both the input image and the image prompt guided by the text prompt.

IP Adapter Depth XL
The IP Adapter, when combined with the Depth Preprocessor, significantly boosts the SDXL model's functionality. The IP adapter y enables SDXL to utilize image prompts in conjunction with text prompts. On the other hand, the Depth Preprocessor plays a crucial role by analyzing and extracting depth cues from images, which contributes to a better understanding of the spatial dimensions in the original scene. Together, these tools are instrumental in generating images that are not only detailed but also rich in contextual depth, blending elements seamlessly from the provided original image and the image prompt as refined by the accompanying text prompt.
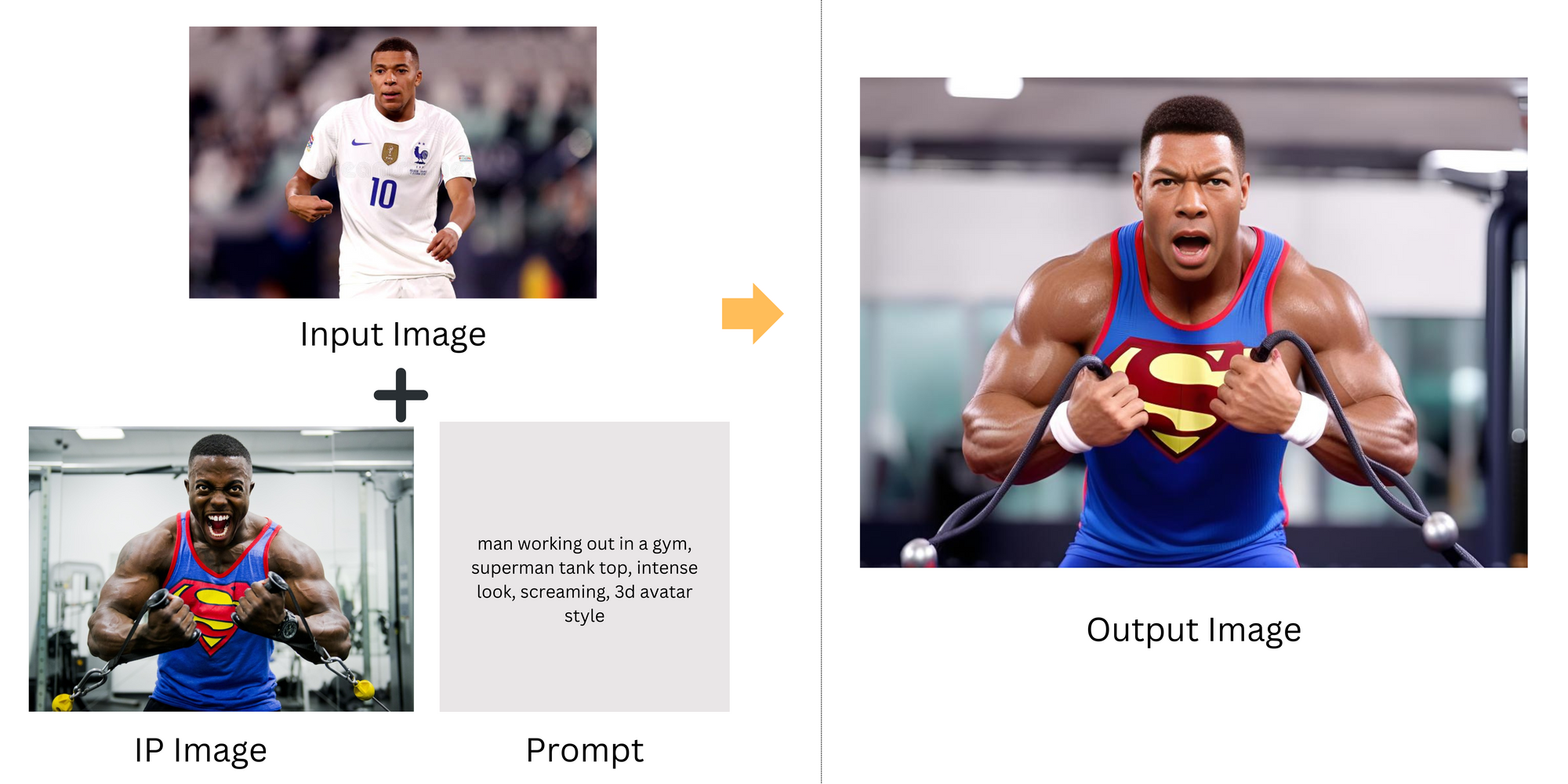
IP Adapter Openpose XL
The combination of the IP Adapter and the Open Pose Preprocessor significantly enhances the SDXL model's capabilities. The IP adapter enables SDXL to utilize image prompts in conjunction with text prompts. The Openpose Preprocessor specializes in analyzing and identifying human poses and gestures within images. This is essential for accurately interpreting human figures and their movements in the original image. Together, these components enable the creation of visually rich and contextually detailed images, harmoniously blending the elements from the original image with nuanced interpretations guided by the text prompt, especially in scenarios involving human subjects.

Use cases of IP Adapter XL models
We explored the functionalities of different IP Adapter models with Canny, Depth, and OpenPose preprocessors.
- The IP Adapter Canny XL model is ideal for scenarios requiring precise edge and contour definition in images.
- The IP Adapter Depth XL model is best suited for applications needing realistic depth and spatial representation.
- The IP Adapter OpenPose XL model excels in accurately rendering human poses and is ideal for images involving human figures.
Each of these models has unique applications depending on their specific strengths in edge detection, depth perception, or pose estimation.
Conclusion
In this blog post, we delved into the advanced capabilities of the IP Adapter, focusing on the Canny, Depth, and OpenPose preprocessors for image generation using the SDXL model. We explored practical examples demonstrating how these preprocessors work in tandem with the IP Adapter to transform images. This post highlights the versatility and effectiveness of IP Adapter models in creating intricate and contextually rich images, showcasing their potential in various applications.