A Beginner's Guide to ControlNets in Stable Diffusion Image Generation
ControlNets enhance Stable Diffusion models by adding advanced conditioning beyond text prompts. This allows for more precise and nuanced control over image generation, significantly expanding the capabilities and customization potential of Stable Diffusion models.


In today's ever-evolving tech landscape, striking a balance between human creativity and machine precision has become increasingly important. That's where ControlNet comes in—functioning as a "guiding hand" for diffusion-based text-to-image synthesis models, addressing common limitations found in traditional image generation models.
Although standard visual creation models have made remarkable strides, they often fall short when it comes to adhering to user-defined visual organization. ControlNet steps in to bridge this gap by offering an additional pictorial input channel, which influences the final image generation process. From simple sketches to detailed depth maps or edge maps, this handy tool accommodates a wide range of input types, ultimately helping you bring your vision to life.
Say goodbye to frustrations stemming from misaligned expectations and hello to a fruitful collaboration between human artists and intelligent machines. Let's explore the exciting realm of AI-enhanced image creation with ControlNet leading the way!
Under the Hood
ControlNet undergoes training utilizing a previously trained Stable Diffusion model that was initially trained on extensive image databases consisting of billions of images.
Two copies are derived from the Stable Diffusion model—one remains a static, non-trainable version with fixed weights (the locked copy), while the second copy possesses adjustable weights subjected to training processes (the trainable copy).
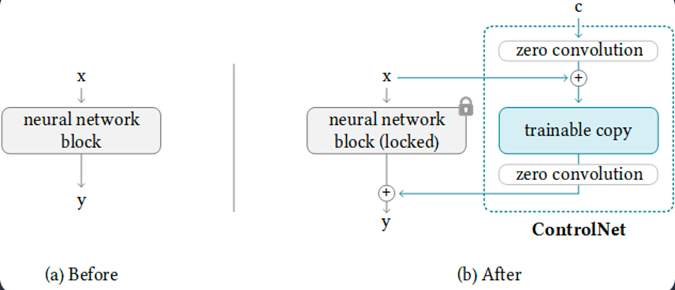
During the early stages of training, neither the locked nor trainable copies exhibit considerable differences in parameter values compared to instances when no ControlNet exists. The trainable copy subsequently learns specific conditions guided by the conditioning vector denoted as 'c', empowering ControlNet to govern the general conduct of the neural network throughout the training phase. Crucially, the locked copy's parameters remain constant and unaffected by alterations throughout the training period.
By maintaining consistency between the locked and trainable copies' parameter values during the initial training steps, ControlNet ensures minimal disruption to the established characteristics inherited from the pre-trained Stable Diffusion model. Gradually introducing modifications via fine-tuning the trainable copy alongside the evolution of zero convolution layers leads to a smoother, faster optimization process comparable to conventional fine-tuning methods rather than retraining the entire ControlNet setup from scratch.
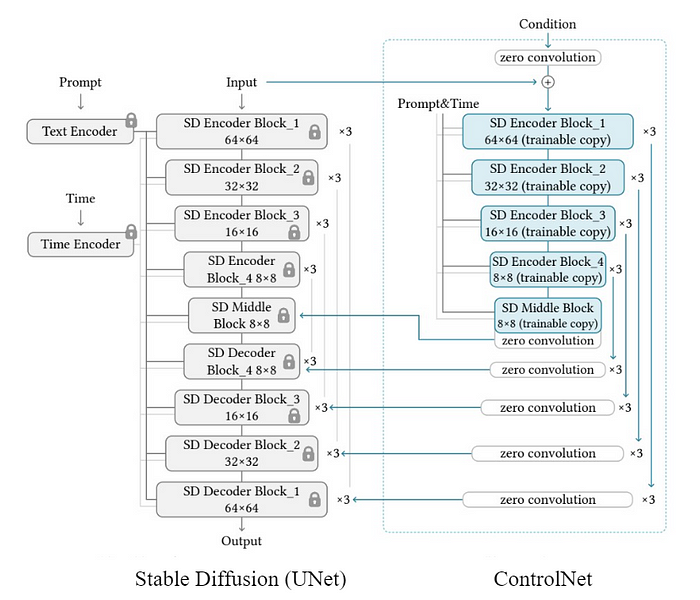
In summary, ControlNet captures complex conditional controls using a novel technique called "zero convolutions," allowing for seamless integration of spatial conditioning controls into the main model structure. Functioning as a whole neural network system, ControlNet manages significant image diffusion models such as Stable Diffusion, understanding task-specific input conditions.
OpenPose

OpenPose is state-of-the-art technique designed to locate critical human body keypoints in images, such as the head, shoulders, arms, legs, hands, and other essential limbs. One of its primary applications involves accurately reproducing human poses while overlooking less relevant factors like clothing, hairstyles, and backgrounds. Consequently, OpenPose proves especially effective in scenarios where capturing precise postures holds higher importance than retaining unnecessary specifics.
To delve deeper into the intricacies of ControlNet OpenPose, you can check out this blog
Scribble
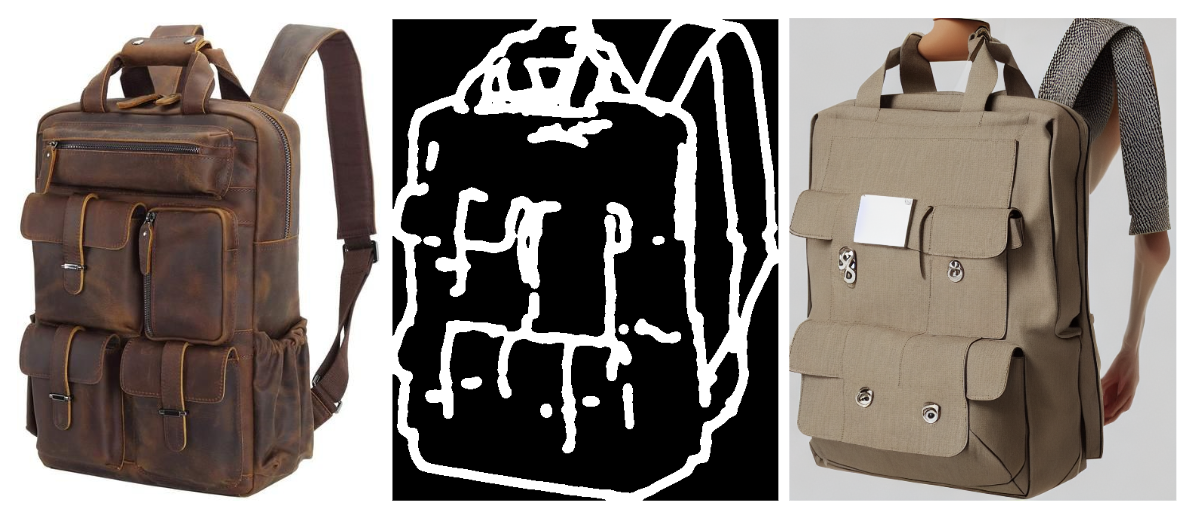
Scribble is a creative feature that imitates the aesthetic appeal of hand-drawn sketches using distinct lines and brushstrokes reminiscent of manual drawing. It generates artistic results, making it suitable for users who wish to apply stylized effects to their images.
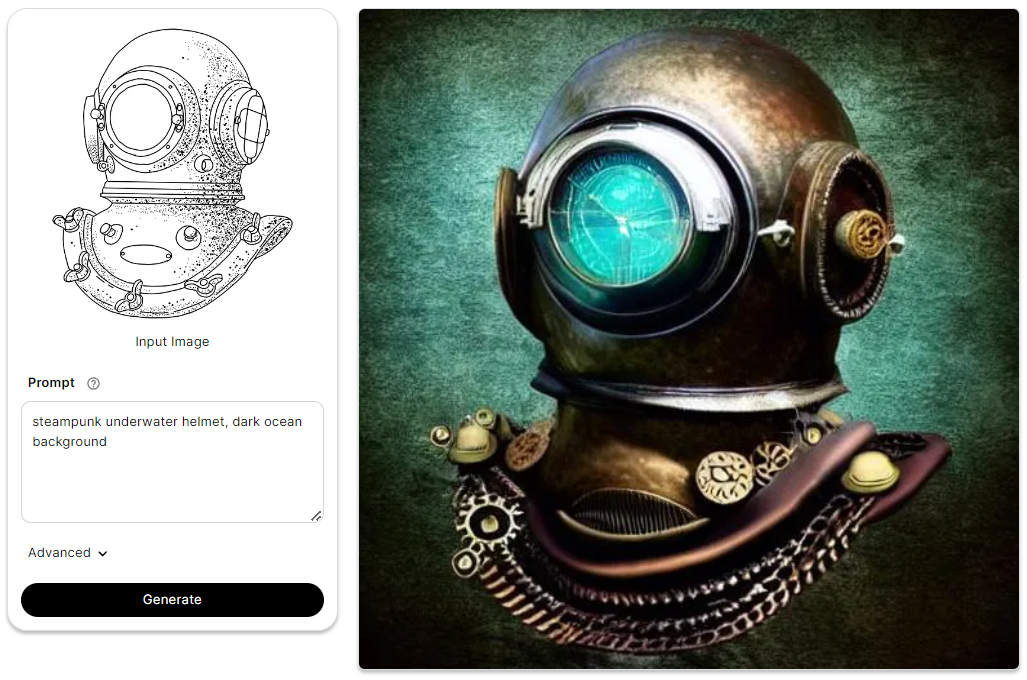
Depth

The ControlNet layer converts incoming checkpoints into a depth map, supplying it to the Depth model alongside a text prompt. During this process, the checkpoints tied to the ControlNet are linked to Depth estimation conditions. Ultimately, the model combines gathered depth information and specified features to yield a revised image. In essence, Depth modifies the Stable Diffusion model's behavior based on depth maps and textual instructions.
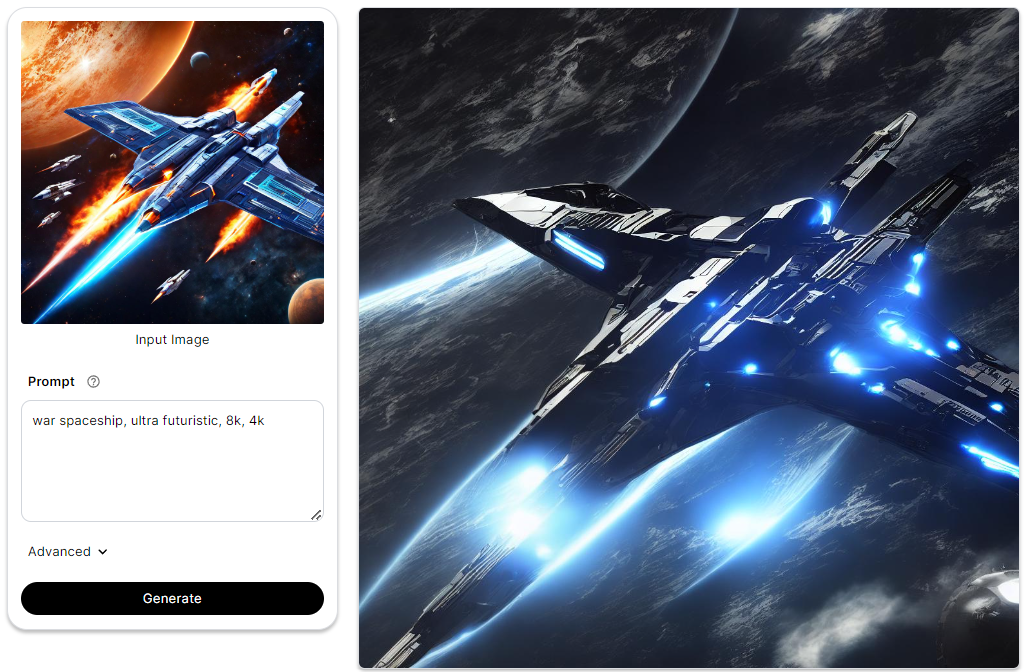
To delve deeper into the intricacies of ControlNet Depth, you can check out this blog
Canny
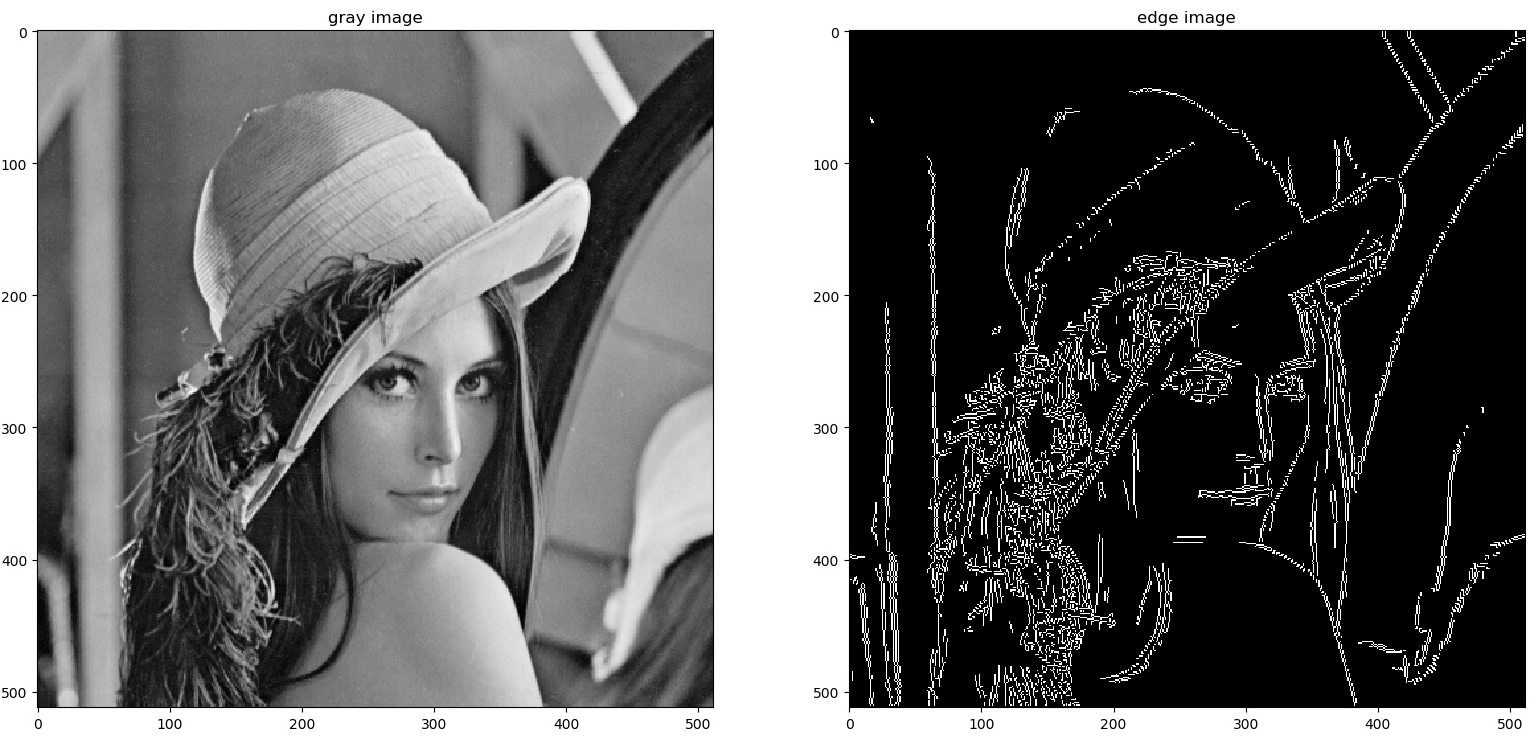
Canny edge detection operates by pinpointing edges in an image through the identification of sudden shifts in intensity. Renowned for its prowess in accurately detecting edges while minimizing noise and erroneous edges, the method becomes even more potent when the preprocessor enhances its discernment by lowering the thresholds. Granting users an extraordinary level of control over image transformation parameters, the ControlNet Canny model is revolutionizing image editing and computer vision tasks, providing a customizable experience that caters to both subtle and dramatic image enhancements.
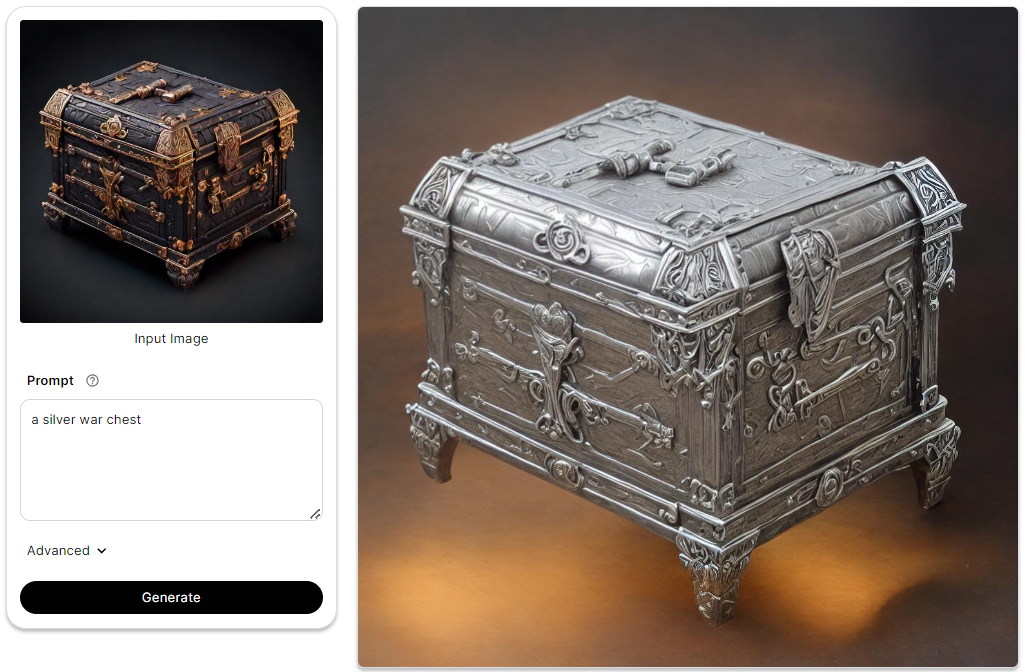
To delve deeper into the intricacies of ControlNet Canny, you can check out this blog
Soft Edge
The ControlNet SoftEdge model updates diffusion models with supplementary conditions, focusing on elegant soft-edge processing instead of standard outlines. Preserving vital features and decreasing noticeable brushwork results in alluring, profound representations.
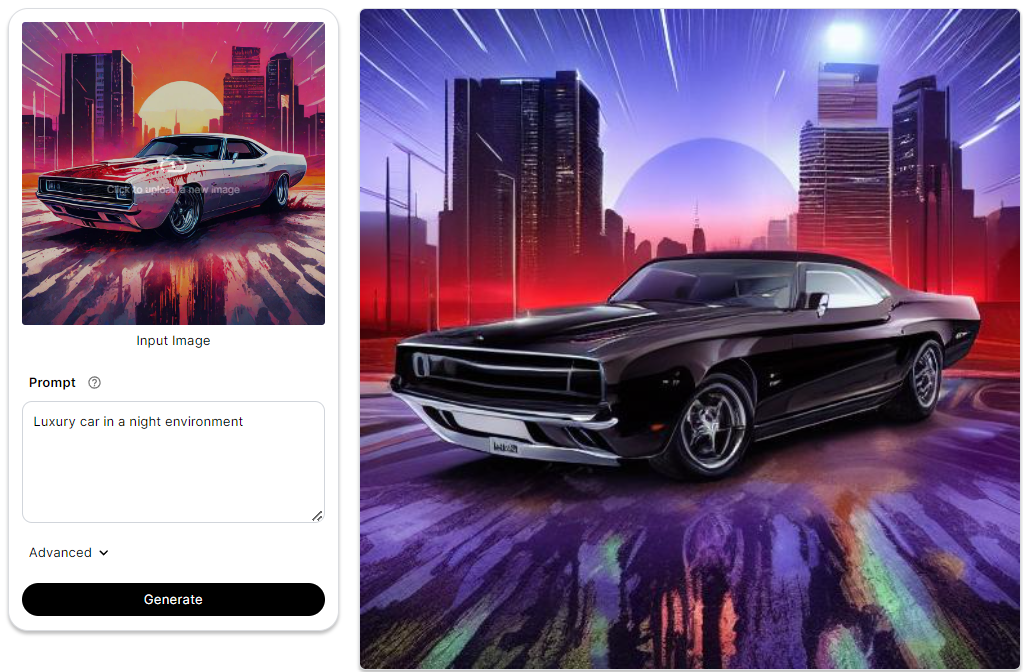
Built on a carefully engineered neural network architecture, it expertly manages the balance between conserving central image attributes and smoothening transitions at soft edges, preventing jarring impressions caused by stark divisions. To sum up, it adds graceful soft-focus touches to diffusion models, skillfully harmonizing essential features and subtle edge differences.
To delve deeper into the intricacies of ControlNet SoftEdge, you can check out this blog
SSD Variants
Segmind's Stable Diffusion Model (SSD-1B) excels in AI-driven image generation, boasting a 50% reduction in size and a 60% speed increase compared to Stable Diffusion XL (SDXL). Leveraging insights from models like SDXL, ZavyChromaXL, and JuggernautXL, and trained on datasets including Grit and Midjourney scrape data, SSD-1B delivers impressive visual outputs across diverse textual prompts. As a robust text-to-image tool, SSD-1B prioritizes both speed and visual excellence. SSD Variants integrate the SSD-1B model with ControlNet preprocessing techniques, including Depth, Canny, and OpenPose.
SSD Depth
SSD-1B Depth model surpasses conventional image processing by constructing depth charts, changing plain graphics into vivid, 3D sensory events. Such processed images deliver a lifelike sensation of depth, raising the bar for storytelling aesthetics. Simply stated, SSD-1B Depth model breathes life into static images by rendering realistic depth perspectives, taking viewer engagement to new heights.
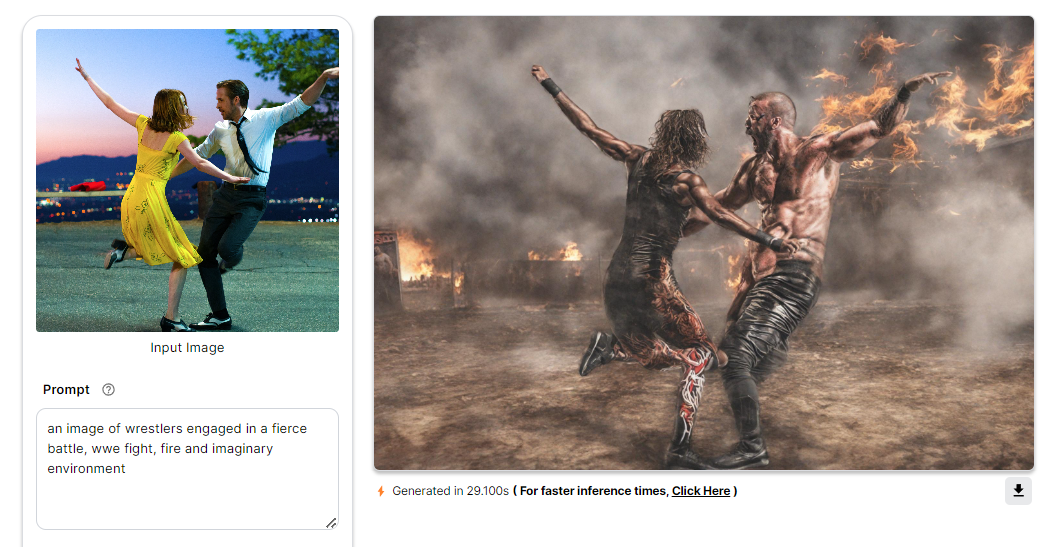
To delve deeper into the intricacies of SSD Depth, you can check out this blog
SSD Canny
SSD-1B Canny model is an advanced image processing tool that excels at detecting edges with high precision and flexibility. It is built upon the established Canny edge detection algorithm but provides additional features to fine-tune the results according to user needs. This combination of accurate outline tracing and adjustable parameters enables users to create refined, personalized edits efficiently.
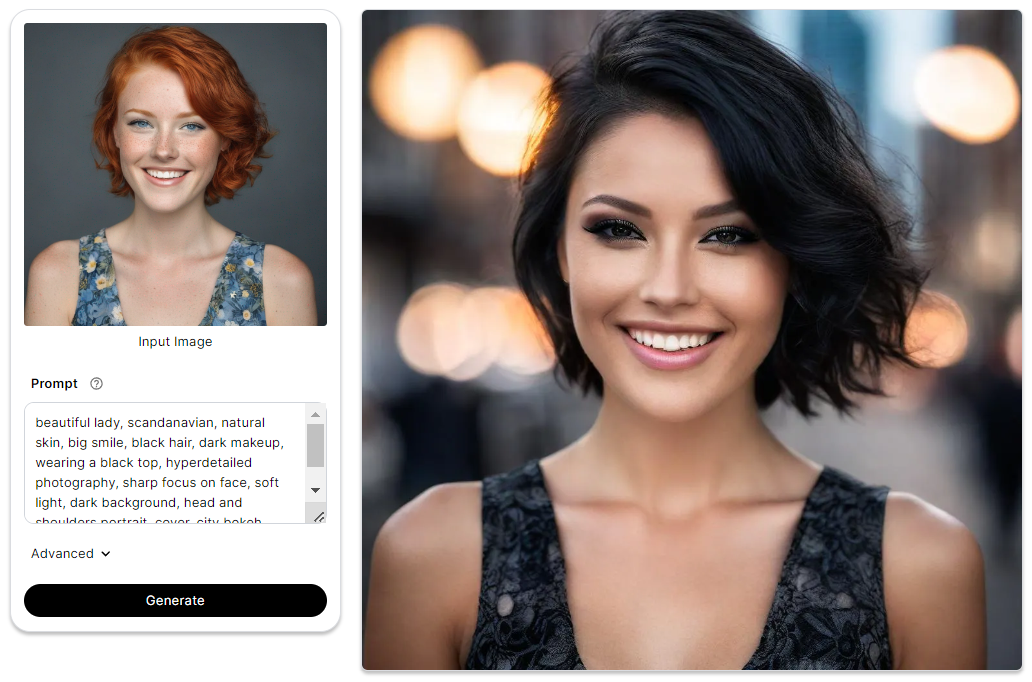
To delve deeper into the intricacies of SSD Canny, you can check out this blog
IP Adapter XL Variants
Unlike other models, IP Adapter XL models can use both image prompts and text prompts. The main idea is that the IP adapter processes both the image prompt (called IP image) and the text prompt, combining features from both to create a changed image.
This changed image is then mixed with the input image that went through ControlNet preprocessing with methods like Canny, Depth, or Openpose. The result is an image that blends elements from both original images, guided by the text prompt.
IP Adapter XL Depth
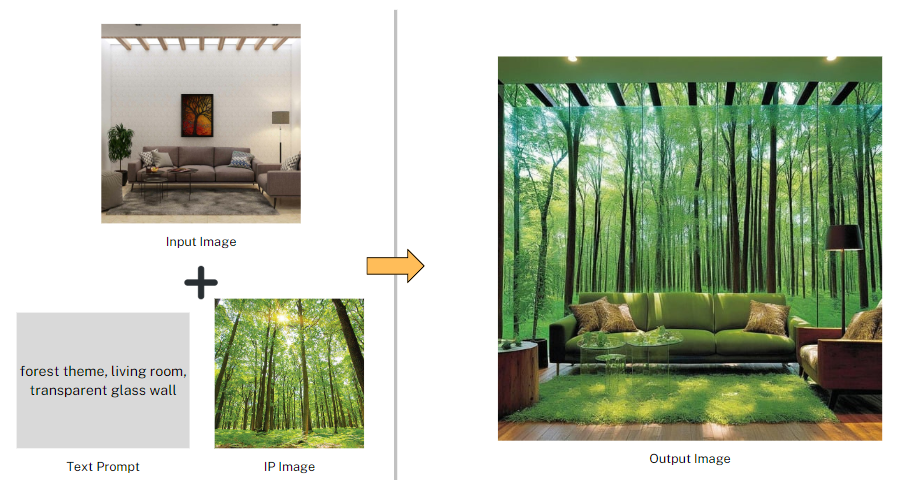
By seamlessly integrating the IP Adapter with the Depth Preprocessor, this model introduces a groundbreaking combination of depth perception and contextual understanding in the realm of image creation. The synergy between these components significantly elevates the functionality of the SDXL framework, promising a distinctive approach to image transformation with enhanced depth and nuanced contextual insights.
To delve deeper into the intricacies of IP Adapter XL Depth, you can check out this blog
IP Adapter XL Canny

The IP Adapter, in tandem with the Canny edge preprocessor, enhances the SDXL model by providing extra control. The Canny preprocessor preserves the original image's structure by extracting its outlines. The IP adapter enables the SDXL model to use both image and text prompts, creating refined images that blend features from both inputs guided by the text prompt.
To delve deeper into the intricacies of IP Adapter XL Canny, you can check out this blog
IP Adapter XL OpenPose

Crucial for accurate interpretation of humans in images, Openpose Preprocessor effectively extracts pose data. This leads to more detailed, visually-rich outcomes; seamlessly fusing base image elements with intricate text-guided understandings, particularly useful in depicting human subjects. Hence, integrating IP Adapter and OpenPose Preprocessor heightens precision and sophistication in produced images centered around human forms.
To delve deeper into the intricacies of IP Adapter XL OpenPose, you can check out this blog
Further Reading