ControlNet - Adding control to Stable Diffusion's image generation
ControlNet is a cutting-edge neural network designed to supercharge the capabilities of image generation models, particularly those based on diffusion processes like Stable Diffusion.


At its core, ControlNet acts as a guiding hand for diffusion-based text-to-image generation models. While traditional image generation models can produce stunning visuals, they often lack guidance, and therefore the ability to generate images subject to user-desired image composition. ControlNet changes the game by allowing an additional image input that can be used for conditioning (influencing) the final image generation. This could be anything from simple scribbles to detailed depth maps or edge maps. By conditioning on these input images, ControlNet directs the Stable Diffusion model to generate images that align closely with the user's intent.
Imagine being able to sketch a rough outline or provide a basic depth map and then letting the AI fill in the details, producing a high-quality, coherent image. The applications are vast, from digital artistry and video game design to advanced simulations and virtual reality. With ControlNet, the power to guide and refine the image generation process is now in the hands of the user, bridging the gap between human creativity and machine precision.
As we continue to push the boundaries of what AI can achieve, tools like ControlNet remind us that the future of content creation is not just about automation, but collaboration between humans and machines.
Technical Architechture
ControlNet is an iteration of the Stable Diffusion model. For those familiar with the intricacies of neural network designs, the U-Net model embedded within ControlNet might seem deceptively familiar. That's because it's a direct descendant of the original Stable Diffusion model. It locks the original Stable Diffusion model and creates a trainable copy of the original model along with zero convolution layers that take in a conditioning vector c as input.
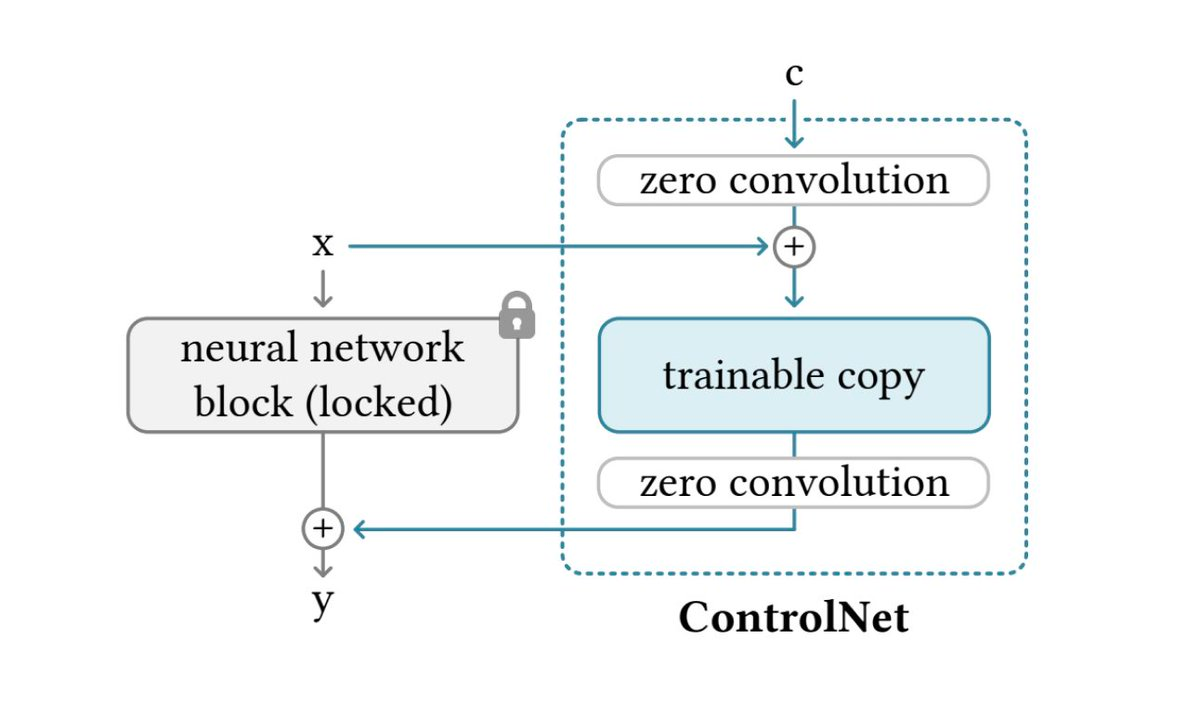
But where ControlNet truly shines is in its innovative additions. Among these is the inclusion of a trainable encoder, which is, in essence, a doppelgänger of the U-Net Stable Diffusion encoder. However, this twin isn't just for the show. It's been engineered to be fully trainable, granting it the remarkable capability to spatially influence the outcome of the output image. This is achieved by feeding this encoder with noise and edges. For the uninitiated, edges in this context are representations of the target image's contours, providing a framework or scaffold on which the image is built. In essence, ControlNet clones the weights of a diffusion model, it then trains the cloned weights to control the original model with the task from the input condition.
But what about those mysterious 'zero convolution' layers? These layers serve as vital conduits between the controlling encoder and the stable diffusion U-Net. "Zero convolutions" in the context of ControlNet refer specifically to 1D convolutional layers where both weights and biases are initialized to zeros. Now, in the grand scheme of neural network architectures, weight initialization is paramount. Typically, weights and biases are set with small random values. This randomness is strategic, ensuring that during training, neurons don't just evolve in lockstep but diverge, each learning different features and patterns.
But ControlNet deviates from this convention for a reason. Initializing these 1D convolutional layers to zero serves a unique and deliberate purpose. Since zero convolutions do not add noise to the network, the model should always be able to generate high-quality images.
Use Cases
Let's discuss a few interesting use cases of ControlNet across various domains.
Fashion
With ControlNet, fashion designers can sketch rough ideas or outlines of clothing items, and the system can generate realistic depictions of those designs, complete with intricate patterns, textures, and colors. This quick visualization can help designers make swift decisions on styles, cuts, and overall design aesthetics.
Check out our detailed blog focused on this workflow

Architecture and Renovation
Architects can feed rough sketches or basic outlines of building designs into ControlNet. The system can then provide detailed visualizations, filling in textures, materials, and potential lighting scenarios, offering a more comprehensive view of the final structure.

Renovators and Interior designers can let their clients visualize how the output would look after remodeling their home or home interiors with the help of ControlNet.

City planners can use ControlNet to visualize urban layouts or park designs. By simply feeding it with basic depth maps or doodles, planners can get a clear picture of what entire city blocks or green spaces might look like after development. These visualizations would aid in more informed planning decisions and also bring stakeholders and the local community onto the same ground.
Marketing
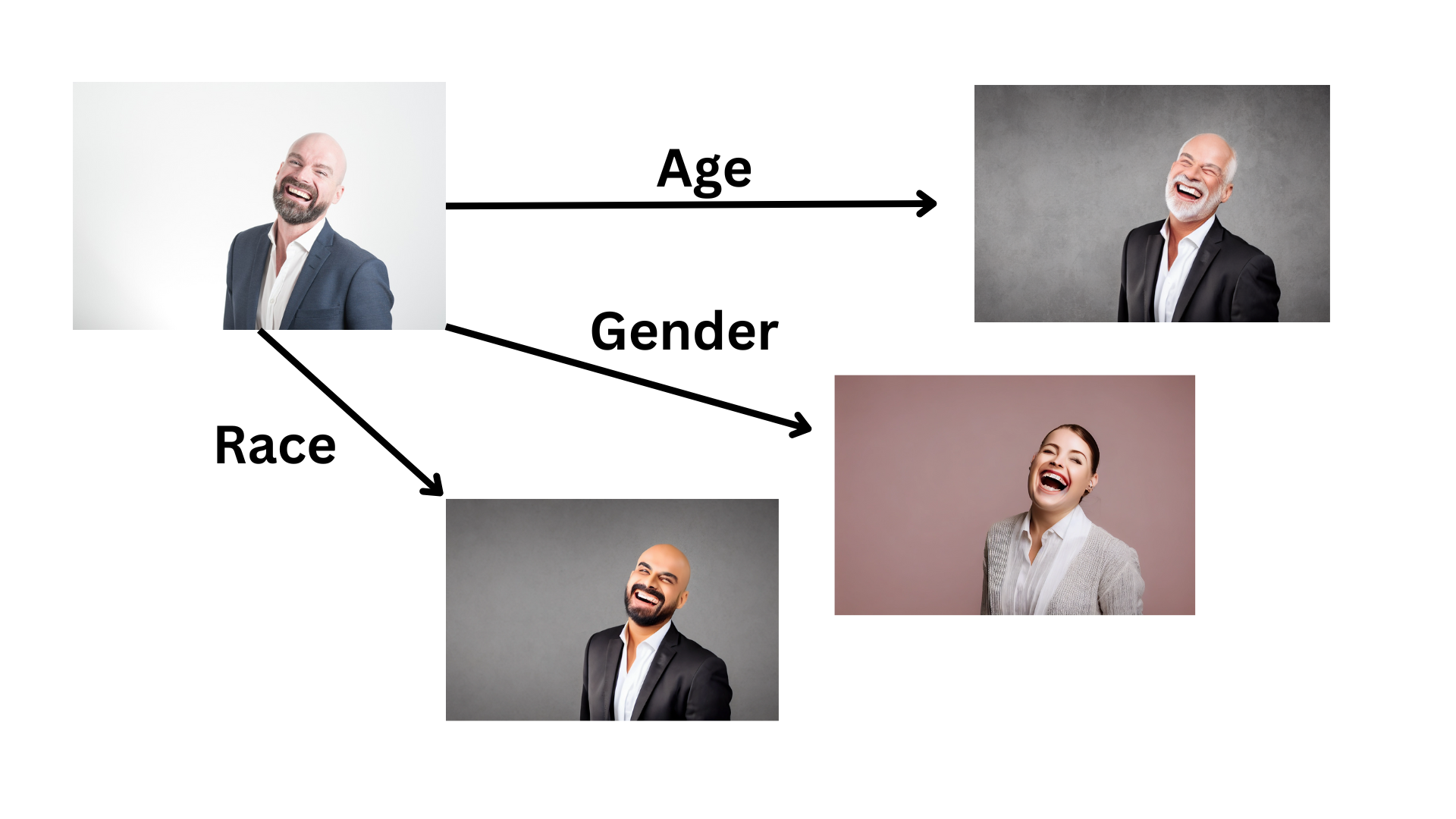
ControlNet can aid marketers to personalize and adapt visual content seamlessly, ensuring that diverse audiences across different regions and cultures feel represented and catered to.
By integrating textual prompts with input images, ControlNet can modify visual elements such as race, gender, age, colors, and patterns to align with local aesthetics and cultural norms, streamlining the localization process.
This flexibility and precision in generating personally and culturally resonant marketing materials enable businesses to connect more deeply with their target demographics, ensuring more effective and engaging campaigns.
Popular Control Mechanisms for ControlNet
Control mechanisms cater to diverse needs and offer users a wide array of options to guide and customize their image-generation processes with ControlNet. Let's look at a few popular controls used with the Stable Diffusion ControlNet and its use cases:
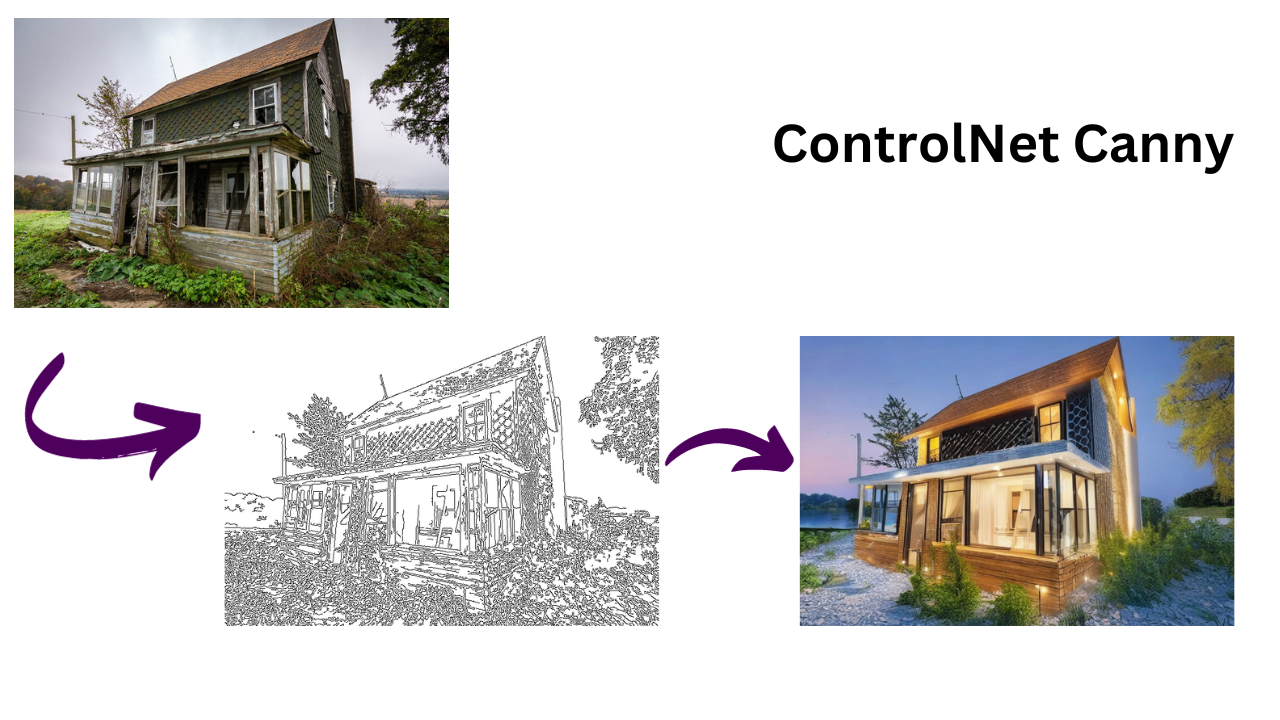
1. ControlNet Canny
The Canny method is one of the most popular edge detection techniques in the field of computer vision. Named after its creator, it is designed to detect a wide range of edges in images.
Functionality with ControlNet: When incorporated into ControlNet, the Canny method can act as a guiding input to focus on the prominent edges and structures in an image. Given a raw image or sketch, Canny would extract the image's contours and edges, potentially suitable for image generation with architectural visualizations or fashion sketches.
2. ControlNet Depth
Depth maps represent the distance of objects in an image scene from a viewpoint, usually in grayscale where white signifies close objects and black indicates distant objects.
Functionality with ControlNet: ControlNet Depth would utilize these depth maps to guide the generation of images with a sense of three-dimensionality. This would be immensely useful in imagery generation for interactive technology like virtual reality or game design, where understanding and visualizing depth and spatial relationships is key.
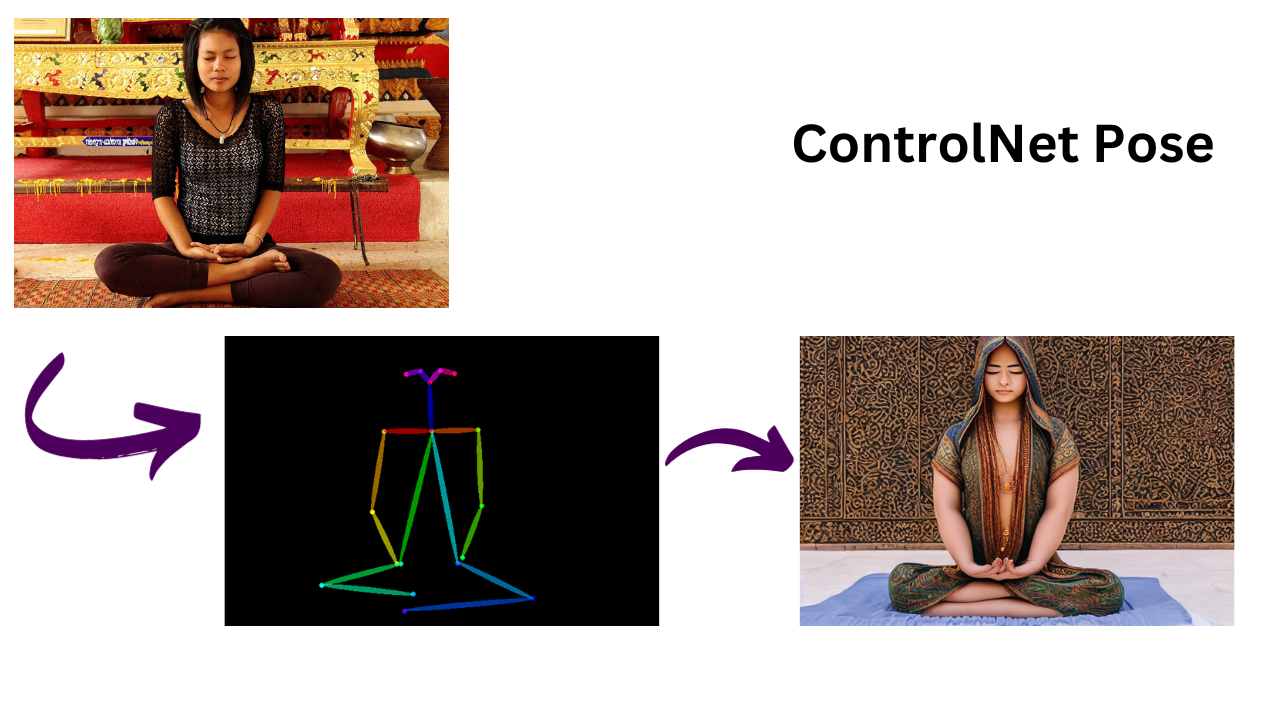
3. ControlNet OpenPose
OpenPose is a real-time multi-person system to jointly detect the human body, hand, and facial key points on single images.
Functionality with ControlNet: With ControlNet OpenPose, users can input images with human figures and guide the system for image generation in the exact pose/posture. This would be particularly advantageous for dance, yoga, fashion, and athletic design, where generating images mimicking the specifics of body posture and movement is crucial.
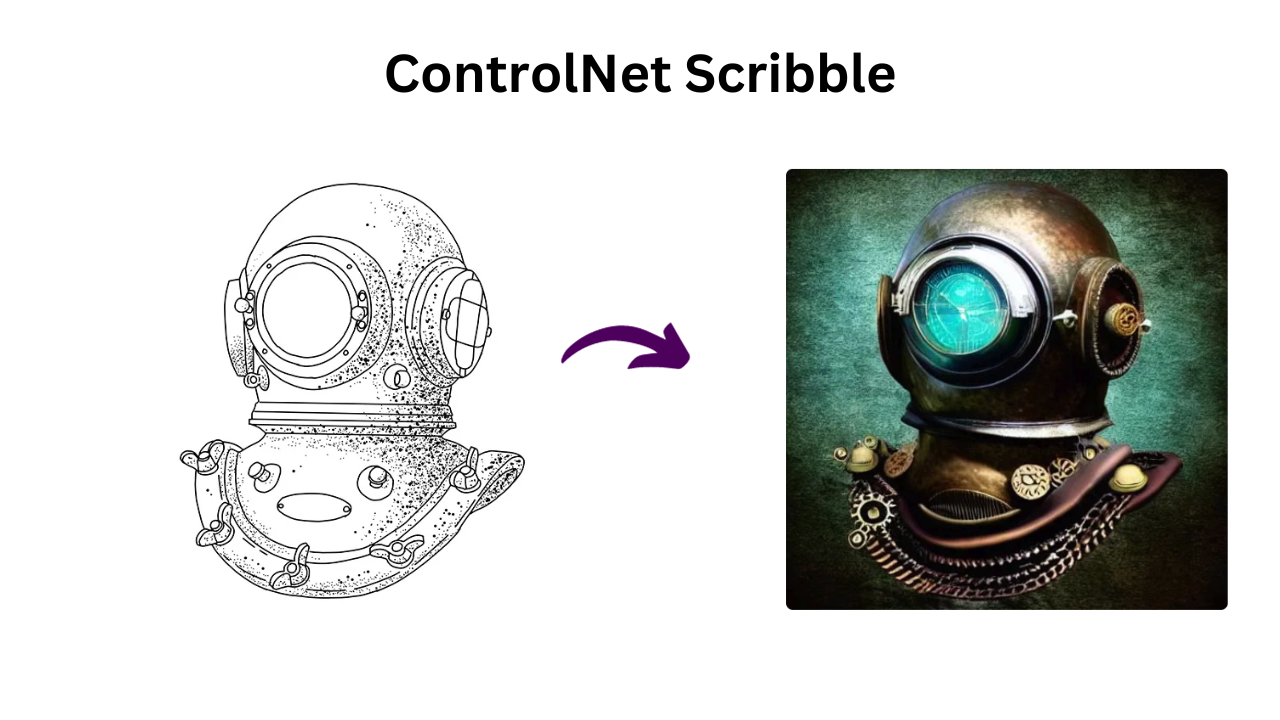
4. ControlNet Scribble
Scribbles are rough, freehand drawings or doodles.
Functionality with ControlNet: ControlNet Scribble would allow users to guide image generation through these freehand inputs. For example, a user might sketch a rough outline or doodle and ControlNet would fill in the details coherently. This method promotes a more interactive and hands-on approach, apt for artists and designers.
5. ControlNet M-LSD
The M-LSD algorithm's strength lies in its ability to extract and describe straight lines with high precision. By discerning these linear structures, it provides the AI with a clear framework, enabling it to render images with sharp, defined edges and straight lines. This intricate line recognition makes it highly reliable for delineating structural aspects of designs.
Functionality with ControlNet: The M-LSD ControlNet shines in architectural domains. It's especially invaluable for visualizing room interiors, where the distinction between walls, floors, and ceilings is crucial. Additionally, it's highly effective for isometric building designs where an accurate representation of structural lines ensures a faithful depiction of the architectural vision.
6. ControlNet SoftEdge
SoftEdge focuses on the softer transitions between objects and backgrounds in an image, as opposed to sharp edge detection.
Functionality with ControlNet: SoftEdge ControlNet would guide the image generation process to produce visuals with softer, more blended transitions. This would be especially beneficial for creating ambient, dreamy, or ethereal visuals, such as backgrounds or environmental art.
Conclusion
ControlNet has ushered in a new era of user-guided image generation, showcasing vast potential across various sectors. Now, more than ever, the reins of creative power are in the hands of the creators themselves. By allowing human creators to guide the generation process, it not only offers precision but also amplifies the collaborative aspect of creativity.