IP Adapter XL Canny: Unveiling the Technical Edge
A comprehensive guide to maximizing the potential of the IP Adapter XL Canny model in image transformation.


In this blog, we delve into the intricacies of Segmind's new model, the IP Adapter XL Canny Model. By seamlessly integrating the IP Adapter with the Canny Preprocessor, this model introduces a groundbreaking combination of enhanced edge detection and contextual understanding in the realm of image creation.
The synergy between these components significantly elevates the functionality of the SDXL framework, promising a distinctive approach to image transformation with edge detailing and nuanced contextual insights.
Under the hood
Text-to-image models are cool, but what if they could understand pictures too? Enter IP-Adapter, the secret weapon that unlocks their bilingual potential! Think of it as a whisperer, translating images' hidden stories – how light plays, elements connect – into a language the model craves.
But remember, the saying goes: 'an image is worth a thousand words'. Don't just whisper, scream your vision through an image prompt too!
Here's the breakdown of how this magic works:
1. Image Encoder: This is like a neural network detective, scrutinizing the image prompt pixel by pixel. It extracts key features like shapes, textures, and color palettes, essentially learning the visual story within the image.
2. Adapted Modules: Think of these as translator bots, converting the extracted image features into a language the diffusion model understands. They use linear layers and non-linearities to encode the visual information in a way the model can digest.
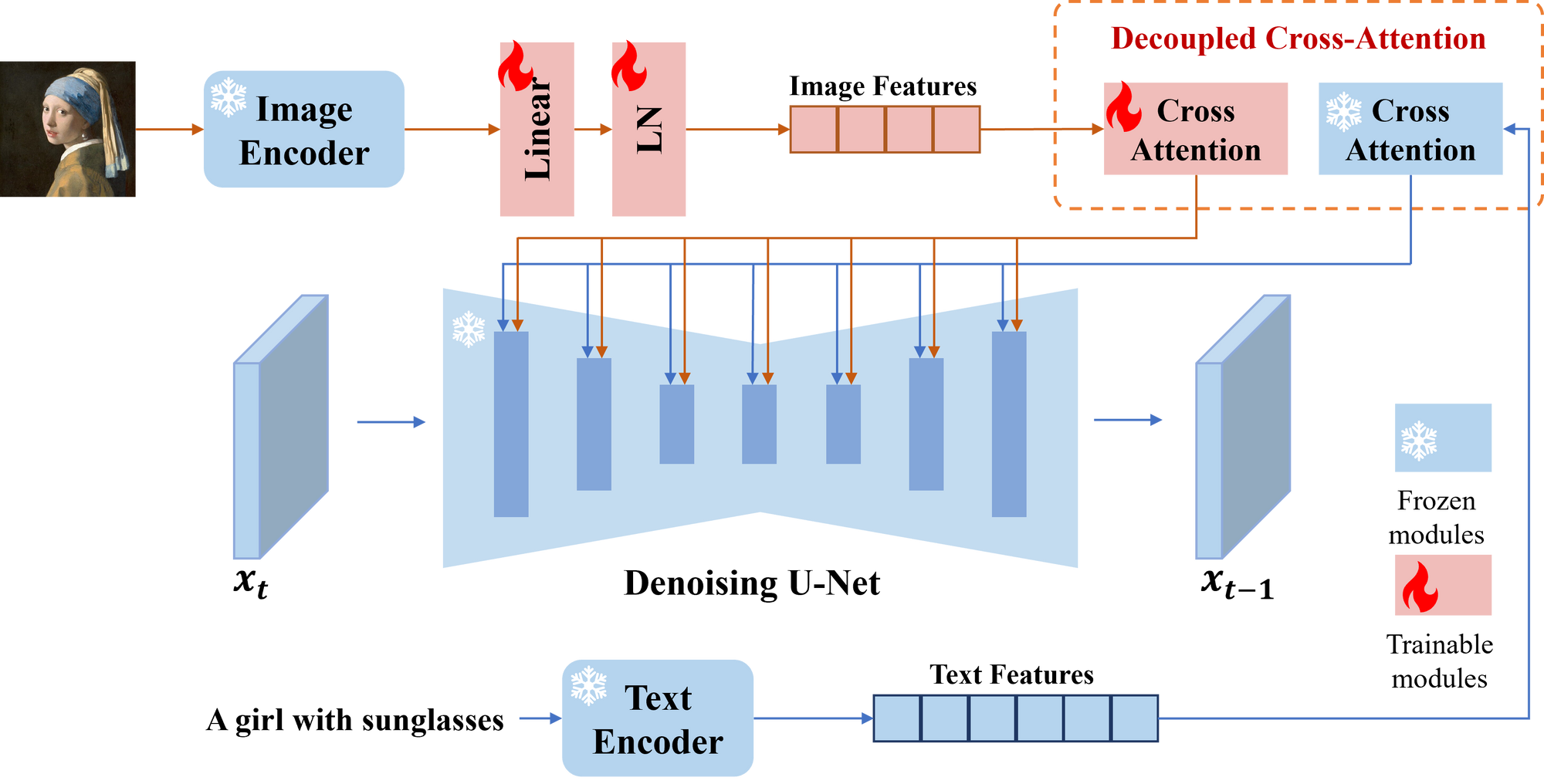
3. Decoupled Cross-Attention: This is the magic sauce! Instead of a single, mashed-up attention layer, IP-Adapter has separate cross-attention mechanisms for text and image features. This means the model attends to both prompts independently, then carefully blends their insights in a weighted fashion.
Now, enter the Canny Preprocessor, a meticulous artist who joins the team:
4. Sharp Edge Sketch: This artist outlines the image's key edges, creating a "skeleton" for the final artwork. Think of it as providing a map of the image's structure.

5. Whispering Context: The IP Adapter, armed with the Canny-derived edge map, delves deeper, deciphering the image's hidden language – how light plays with shapes, how elements connect. This whispered understanding becomes the image's secret sauce.
With all the pieces in place, the enhanced diffusion model takes the stage:
6. Text-Guided Artist: Similar to a skilled painter, the model listens to your text describing the desired style. It then uses the edge map and whispered context to bring the image to life, seamlessly blending your vision with the image's inherent character.
IP-Adapter XL Canny Model is a game-changer, unlocking a world of detailed and nuanced artistic possibilities thanks to its powerful synergy between text, image, and edge awareness.
A Hands-On Guide to Getting Started
Segmind's IP Adadpter Canny model is now accessible at no cost. Head over to the platform and sign up to receive 100 free inferences every day! Let's go through the steps to get our hands on the model.
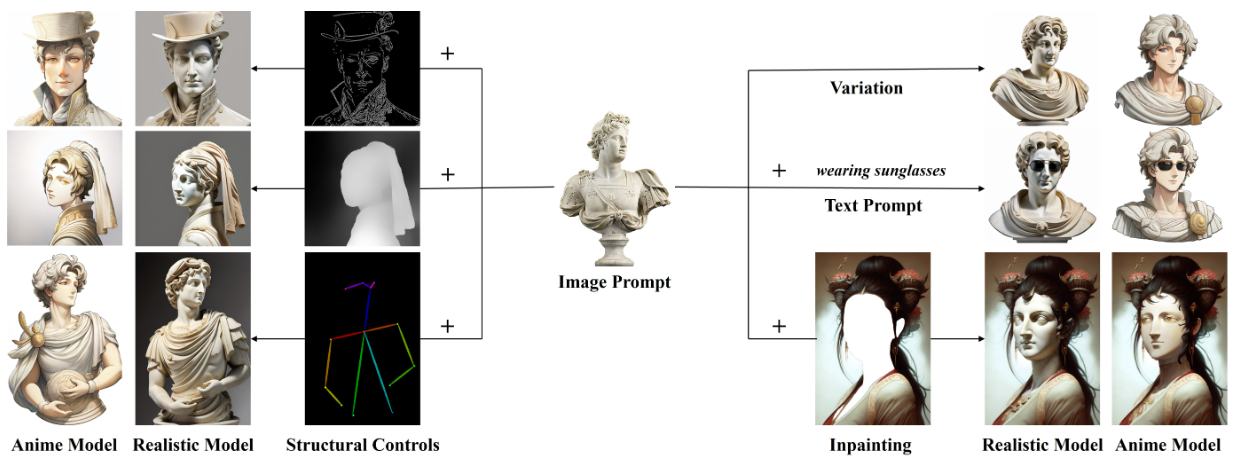
Prepare your Input Image
Your chosen image acts as a reference for the model to grasp the human body pose and generate features on top of it. In this guide, we'll use a picture of a beautiful lady as our input image.
Building the prompt
There are two prompts to create: the image prompt and the text prompt. The image prompt sets the scene for the final output image, while the text prompt refines and adds modifications to the base image.
Let's have a look at the results produced :

Adjusting the Advanced Settings
Let's explore advanced settings to enhance your experience, guiding you through the details for optimal results.
1. IP Adapter Scale
The IP Adapter Scale is crucial because it determines how strongly the prompt image influences the diffusion process in our original image. This parameter is like a specification that defines the scale at which visual information from the prompt image is mixed into the existing context. In simpler terms, it quantifies the level of influence the image prompt has on the final output, giving us precise control over how the diffusion process unfolds.

2. ControlNet Scale
The ControlNet Scale is like a volume knob that's super important. It decides how much the ControlNet preprocessors, like Depth, should affect the way the final image looks. In simple terms, it's like finding the right balance between the special effects added by ControlNet and the original image. Adjusting this scale helps control how strong or subtle those effects are in the end.

3. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.
Opting for more denoising steps also comes at the cost of slower and more expensive inference. While a larger number of denoising steps improves output quality, it's crucial to find a balance that meets specific needs.

4. Seed
The seed is like a kickstart for the random number generator, which sets up how the model begins its training or creating process. Picking a particular seed makes sure that every time you run it, the model starts in the same way, giving you results that are consistent and easy to predict.
Code Unleashed
Segmind offers serverless API to leverage its models. Obtain your unique API key from the Segmind console for integration into various workflows using languages such as Bash, Python, and JavaScript. To explore the docs, head over to IP Adapter Canny API.
First, let's define the libraries that will assist us in interacting with the API and processing the images.
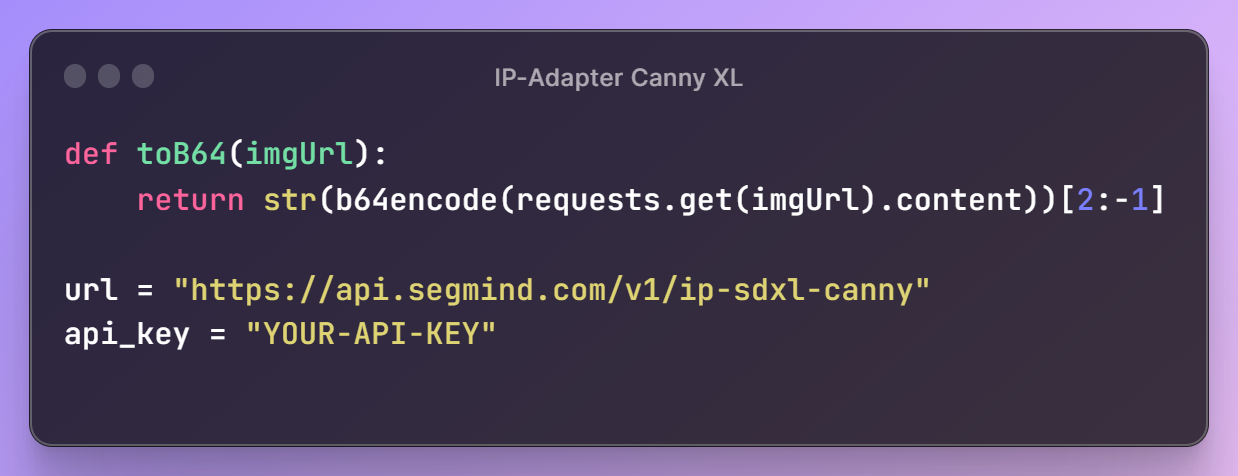
Next, we'll set up our IP Adapter Depth URL and API key, granting access to Segmind's models. Additionally, we'll define a utility function, toB64, to read image files and convert them into the appropriate format for building the request payload.
With these initial steps in place, it's time to create a prompt for our image, specify the desired parameter configurations, and assemble the request payload for the API.
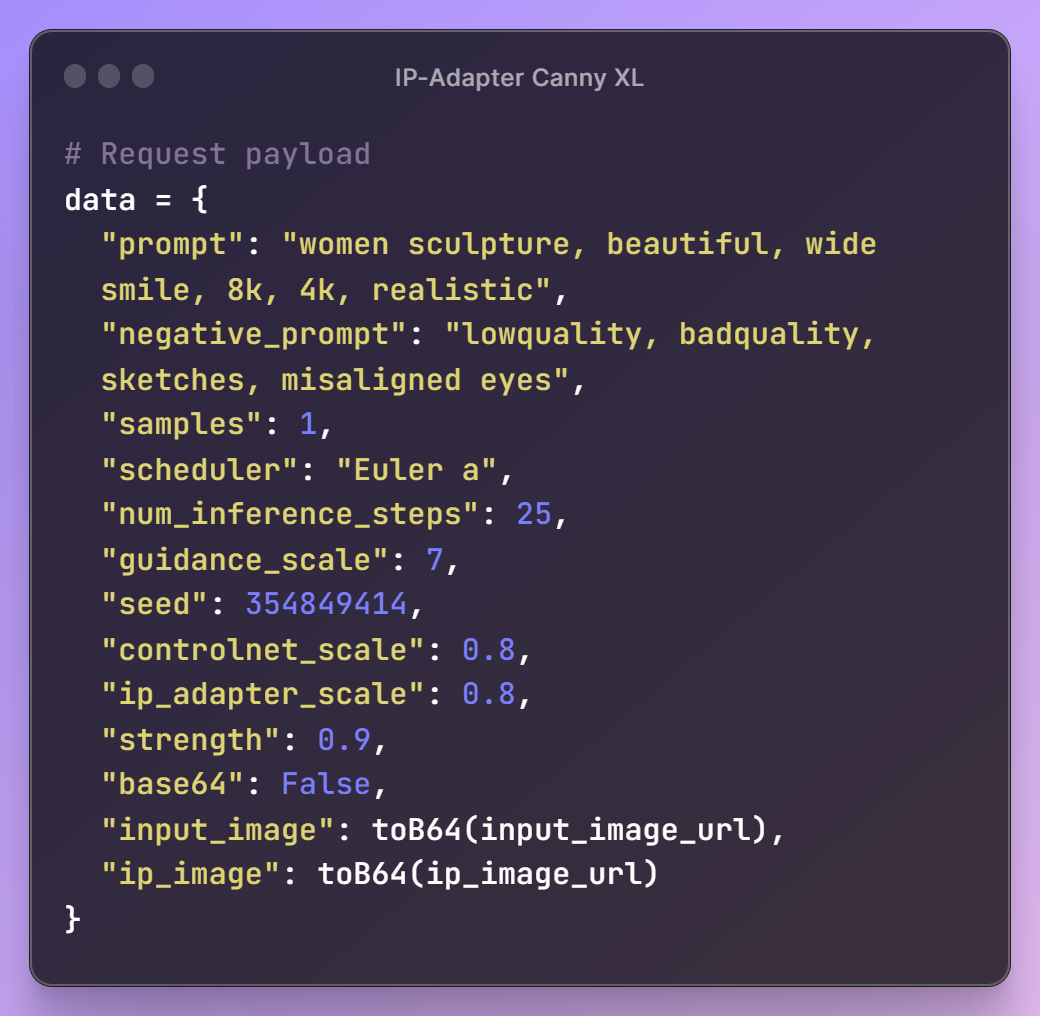
Once the request payload is ready, we'll send a request to the API endpoint to retrieve our generated image. To meet our workflow requirements, we'll also resize the image for seamless integration into our next steps.
Here's the final result! This module can be effortlessly integrated into your workflows in any language.

Summary
Segmind's IP Adapter Canny XL Model revolutionizes text-to-image conversion. Acting like a skilled artist, it decodes both words and visual nuances. The Canny Preprocessor sketches the image's structure, while the IP Adapter interprets context, enhancing the diffusion model.
Ready to experience this model's magic firsthand? Segmind's platform invites you to explore its capabilities directly. Experiment with different parameters and witness how they influence your creations. For those who prefer a structured workflow, a Colab file is available, providing a guided path to unleash your creativity.