IP Adapter Openpose: Model Deep Dive
A comprehensive guide to maximizing the potential of the IP Adapter Openpose model in image transformation.


In this blog, we will dive deep into Segmind's new model, the IP Adapter XL Openpose Model, which offers enhanced capabilities to transform images seamlessly. It is built on the SDXL framework and incorporates two types of preprocessors that provide control and guidance in the image transformation process. One type is the IP Adapter, and the other includes the Openpose preprocessor.
Understanding the IP Adapter Openpose XL Model
At the core of this model, lies the innovative IP Adapter, a crucial component that sets them apart from their counterparts. The IP Adapter XL empowers the model to seamlessly integrate image prompts with text prompts, offering a unique approach to image transformation. It processes both the image prompt (or IP image) and the text prompt, harmonizing features from both sources to craft a modified image. This novel capability allows the IP Adapter XL models to transcend the limitations of conventional models, providing users with unprecedented control over the transformation process.
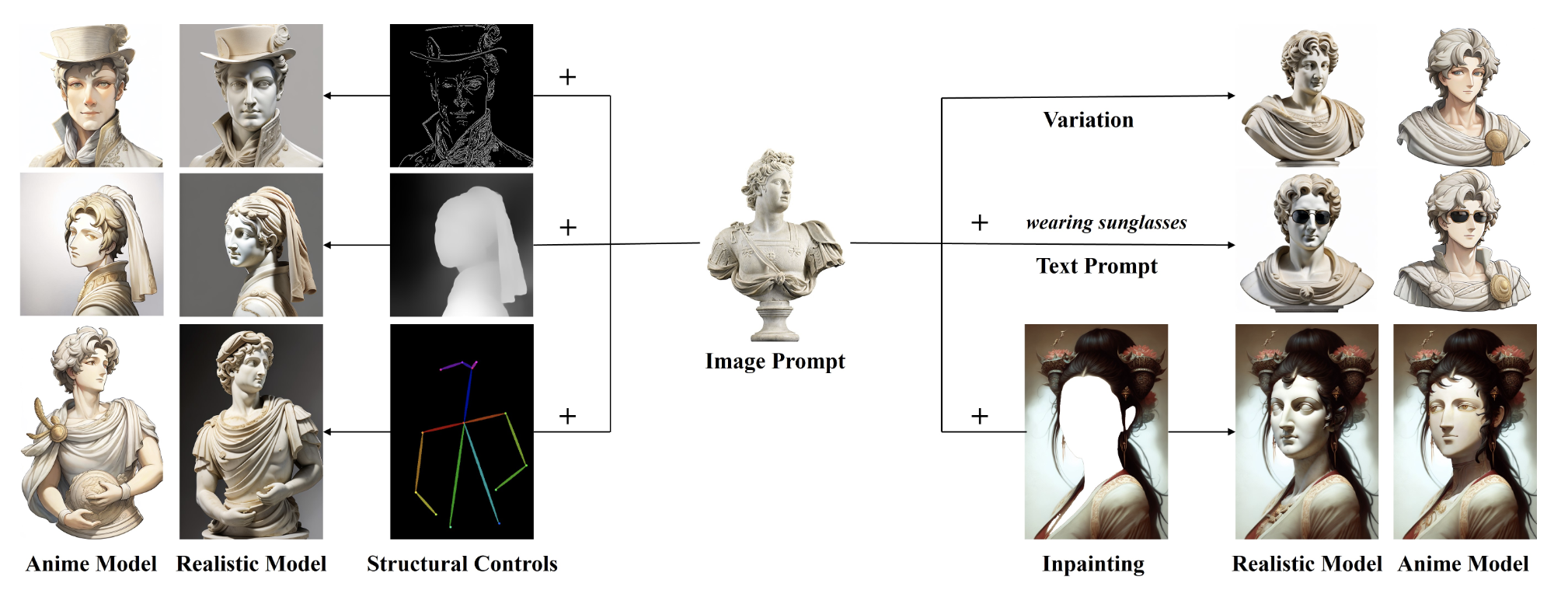
Within the IP Adapter Openpose XL model, the Openpose preprocessor stands out as a specialized tool for analyzing and identifying human poses and gestures within images. This preprocessor plays a pivotal role in accurately interpreting the intricate nuances of human figures and movements, contributing to the overall fidelity of the transformed images. With a keen focus on human-centric scenarios, the Openpose preprocessor enriches the SDXL model's ability to generate visually compelling and contextually detailed images. As an integral part of the IP Adapter Openpose XL model, the Openpose preprocessor ensures that the human subjects in the input image are authentically represented and seamlessly integrated into the transformed output, aligning with the guidance provided by the text prompt.
Under The Hood
The IP Adapter comprises two essential components that work in tandem to facilitate the generation of images guided by both textual and visual cues. Firstly, the image encoder serves as a critical element in the process, extracting pertinent features from the provided image prompt. This extraction is pivotal for capturing the nuanced details and characteristics embedded in the visual prompt. Secondly, the adapted modules with decoupled cross-attention mechanisms come into play, enabling the seamless embedding of these extracted image features into the pre-trained text-to-image diffusion model.
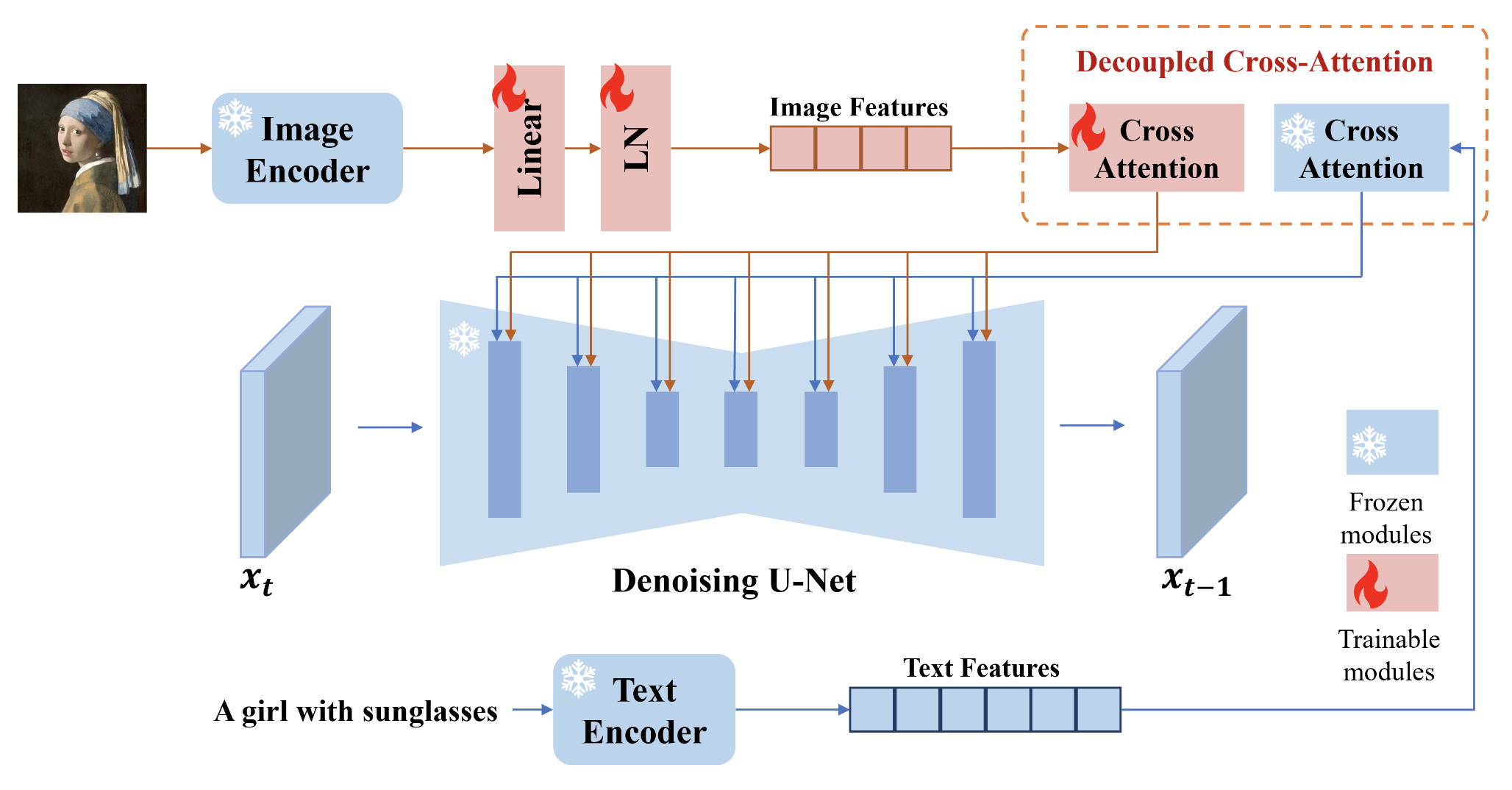
The image encoder acts as a bridge between the textual and visual realms, converting the image prompt into a format conducive to further processing within the model. Its role in feature extraction ensures that relevant information from the image prompt is effectively communicated to the subsequent stages of image generation. The adapted modules, equipped with decoupled cross-attention, play a pivotal role in integrating these image features into the pre-trained text-to-image diffusion model. This decoupling mechanism allows for a nuanced fusion of textual and visual information, ensuring that both sources contribute meaningfully to the generation process.
A Hands-On Guide to Getting Started
Segmind's IP Adapter Openpose model is available here for absolutely free. Head over to the platform and register yourself to get 100 free inferences daily! Let's go through the steps to get our hands on the model.
Prepare your Input Image
Your input image will serve as a reference for the model to understand the human body pose and generate on top of the features of the images. For this guide, let's take the picture of a ballerina dancing as our input image.
Building the prompt
We will have to build two prompts in this case: the image prompt and the text prompt. The image prompt would set the scene of our final output image. The text prompt is used to further refine and add modifications to the base image.
Let's have a look at the results produced :

Adjusting the Advanced Settings
IP Adapter Scale
The IP Adapter Scale plays a pivotal role in determining the extent to which the prompt image influences the diffusion process within our original image. This parameter serves as a crucial specification, defining the scale at which the visual information from the prompt image is blended into the existing context. Essentially, it quantifies the degree of influence the image prompt exerts on the final output, allowing for precise control over the diffusion process.

ControlNet Scale
The ControlNet Scale is a critical parameter that defines the magnitude of influence exerted by ControlNet preprocessors in the image transformation process. Specifically, this scale determines the degree to which the features extracted by ControlNet, such as Openpose, impact the final composition of the output image. In essence, it serves as a control mechanism for balancing the contribution of ControlNet preprocessors with the original image.

Steps
The parameter "steps" determines the number of iterations or cycles the model will go through. Opting for more denoising steps generally yields a higher-quality image, but this comes at the cost of slower and more expensive inference. While a larger number of denoising steps improves output quality, it's crucial to find a balance that meets specific needs.

Code Unleashed
Segmind offers serverless API to leverage its models. Obtain your unique API key from the Segmind console for integration into various workflows using languages such as Bash, Python, and JavaScript. To explore the docs, head over to IP Adapter Openpose API.
We will use Python for this guide. First, Let's define the libraries that will help us interact with the API and process the images.

Now, let's define our IP Adapter Openpose Url and API key, which will give access to Segmind's models. We will also define a toB64 utility function which will help us to read image files and convert them into proper format which we can use to build the request payload.

Now that we've got the initial steps sorted, it's time to create a prompt for our image, define the desired parameter configurations, and assemble the request payload for the API.
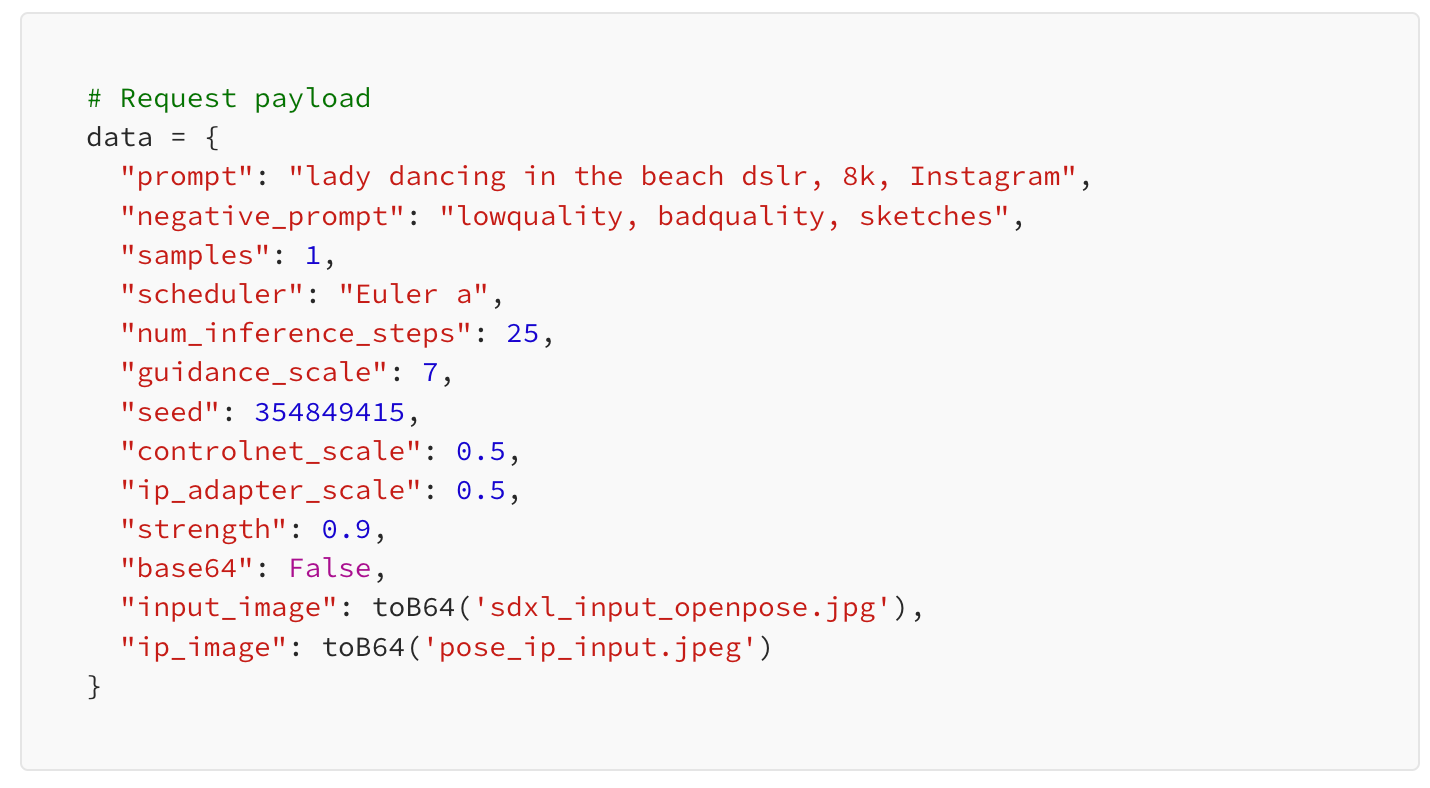
Now that our request payload is set, it's time to send a request to the API endpoint and retrieve our generated image. Additionally, we'll resize the image to suit our workflow requirements, ensuring it fits seamlessly into our next steps.

Here's our final result! This module can be easily integrated further in your workflows in any language.

Summary
This guide gives a deep dive into Segmind's IP Adapter XL Openpose Model. You can use the model and play around with the parameters on the Segmind platform. Plus, you can access this demonstrated workflow conveniently within a Colab file