SSD Depth: Diving Deep into the Model
A comprehensive guide to get the most out of the SSD-1B Depth model in image generation.


Segmind's Stable Diffusion 1B (SSD-1B) Depth Model goes beyond conventional image processing. It creates depth maps that transform two-dimensional visuals into immersive, three-dimensional experiences. The outcome isn't merely observed; it's experienced, providing a palpable depth that enhances the visual storytelling.
Now, you might be wondering about a couple of things right now:
- What exactly are depth maps?
- And how does all of this differ from SSD-1B Img2Img?
Under the hood
Let's break it down and understand each of the piece of the puzzle

- How it starts: First, it adds random fuzziness/noise to a clear picture. Slowly, this turns the image into a blurry mess—that's called the starting phase.
- Getting Back the Original Picture: Then comes the cool part—getting the original picture back. It does this by repeatedly taking away the fuzziness/noise - this is called denoising. To do this right, it has a special model (think of it like a smart helper) that figures out how much fuzziness/noise was added in the first place. After a few tries, you end up with a picture that looks like the original and sometimes even better.
- Adding Depth to Images: Now, picture enhancing your images with a 3D touch—that's precisely what depth maps achieve. They introduce layers to a flat image, creating a more realistic sensation. During each denoising step, the depth map, coupled with the text prompt, plays a crucial role in the process.
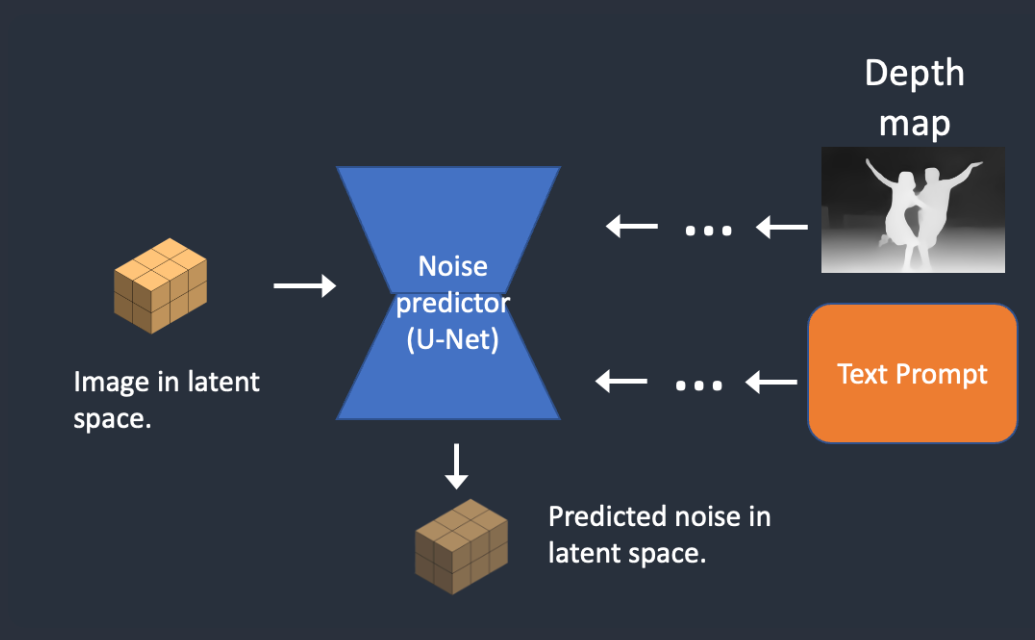

A depth map is a straightforward grayscale image, matching the size of the original. It encodes depth information, where complete white indicates the object is closest to you, and as it gets more black, it means the object is further away.
How does it work?


Examining the image-to-image generation using SSD-1B Img2Img in the bottom row reveals an issue: When the denoising strength was low, the image didn't undergo sufficient changes. On the other hand, at high denoising strength, Bruce Lee is still visible, but the original composition was compromised.
Depth-to-image using SSD Depth effectively addresses this challenge. With this approach, you can increase the denoising strength up to its maximum value of 1 without sacrificing the original composition.
You likely understand what issue it resolves, but now you might be curious about the precise method it employs to address the problem?
Let's delve deeper and examine it from a more technical perspective:
- In the image-to-image process, it utilizes both an input image and a textual prompt for generating images. The output closely mimics the original image's color and shapes.
- In the depth-to-image scenario, it works a bit differently. It still needs a picture and a prompt, but it adds a depth map. This map is estimated using MIDaS, an AI model for monocular depth perception developed in 2019. This depth map is like a guide that helps the model understand the 3D layout of the scene.
- In essence, the depth-to-image process incorporates three conditions for image generation: a textual prompt, the original image, and the depth map. Armed with this information, the model gains insights into the three-dimensional structure of the scene, allowing it to generate distinct images for foreground objects and the background.

Understanding the Advanced Settings
Let's explore advanced settings to enhance your experience, guiding you through the details for optimal results.
1. Negative Prompt
A negative prompt is like telling the AI what not to include in the picture it generates. It helps avoid weird or strange images and makes the output better by specifying things like "blurry" or "pixelated".
As evident, the background in the left image lacks clarity and exhibits low quality. This was solved via giving the negative prompt "low quality, ugly, painting"
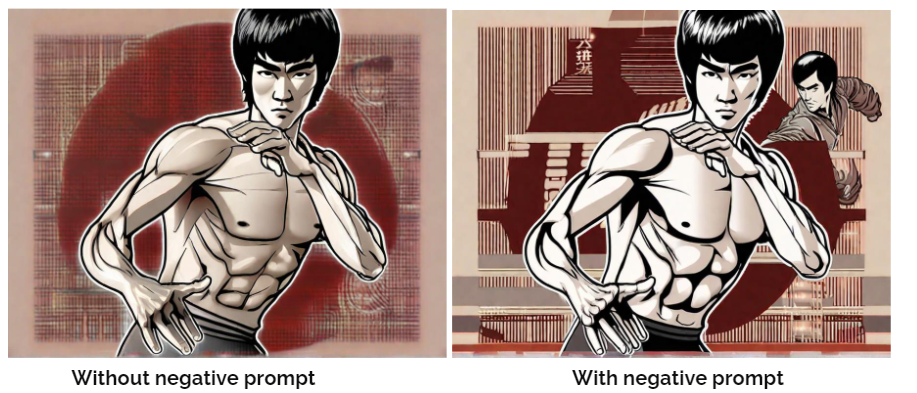
Given Prompt: Manga style Bruce Lee
2. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.

Given Prompt: Unreal Engine, Scene Conversion, Character Design, Game Development, 3D Models, Realistic Rendering, Unreal Engine Characters, Virtual Environments, Game Design, Animation, Game Assets
3. Guidance Scale
The CFG scale, also known as the classifier-free guidance scale, is a setting that manages how closely the image creation process follows the provided text prompt. If you increase the value, the image will adhere more closely to the given text input.

Given Prompt: Same as above
4. Seed
The seed is like a kickstart for the random number generator, which sets up how the model begins its training or creating process. Picking a particular seed makes sure that every time you run it, the model starts in the same way, giving you results that are consistent and easy to predict.
Code Unleased
You also have the option to utilize the SSD-1B Depth through an API. This flexibility allows you to seamlessly integrate it into your workflow using languages like Bash, Python, and JavaScript. You can see the sample code at SSD-1B Depth Colab
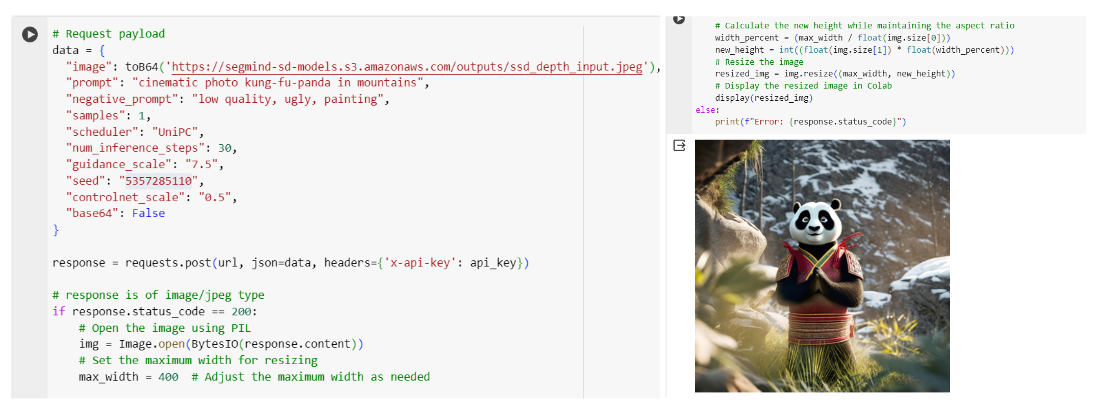
Unlocking More Examples
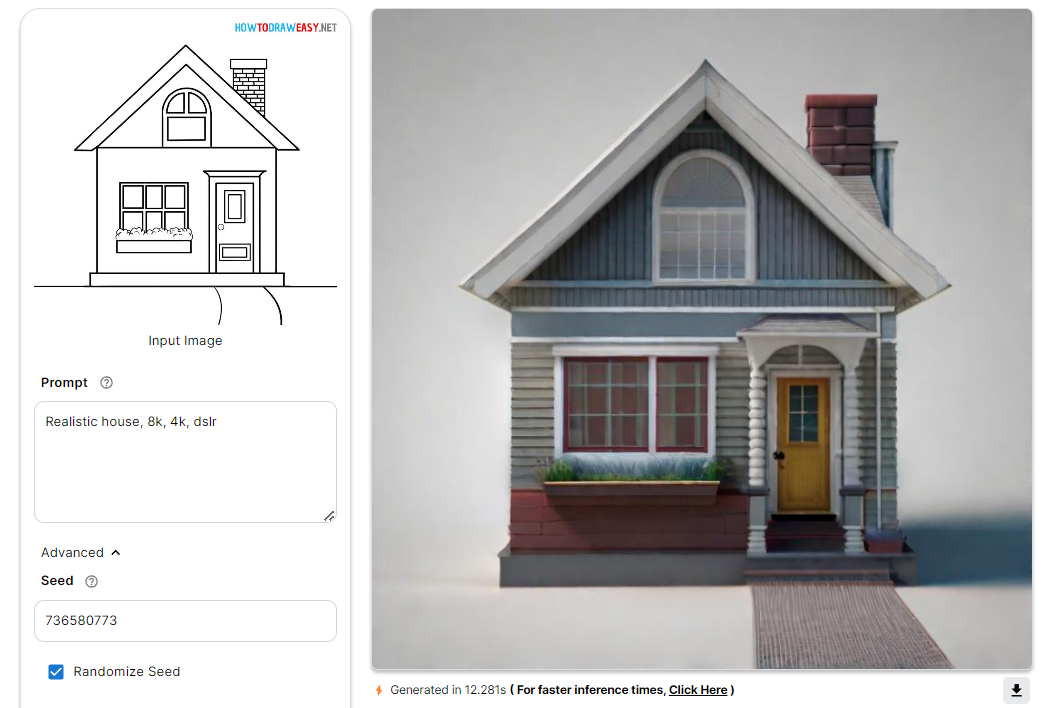
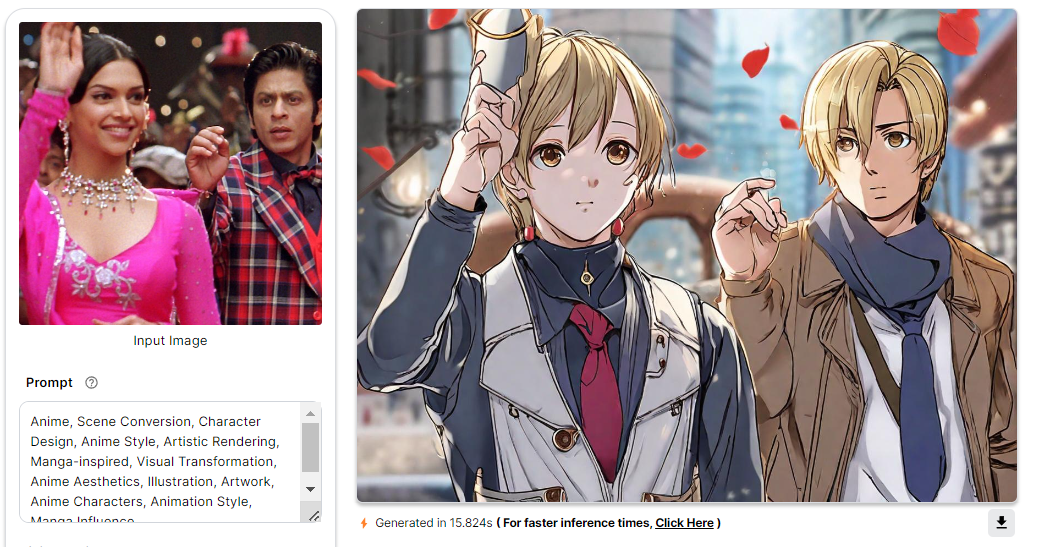

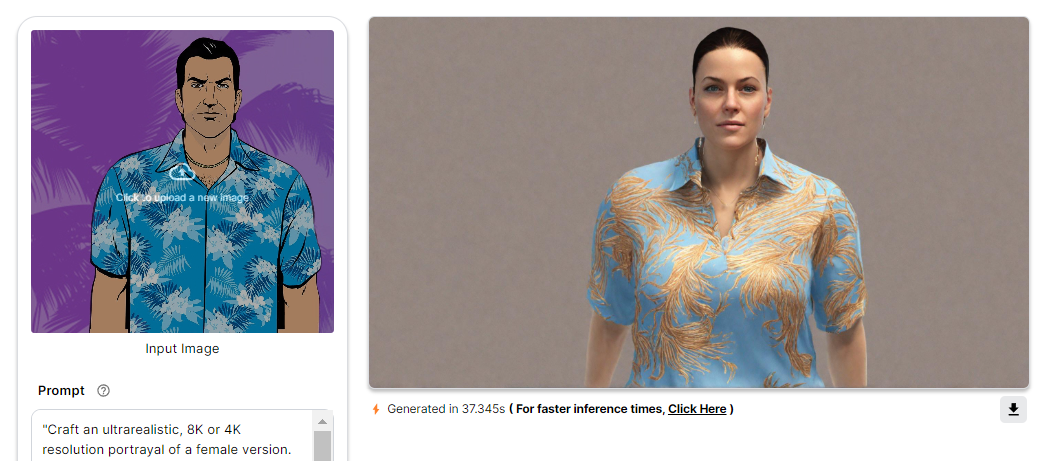
Summary
Segmind's SSD-1B Depth introduces an innovative dimension to image processing by incorporating depth maps, leveraging the prowess of the SSD-1B model. The model is good at fixing noisy pictures in SSD-1B Img2Img, making them clearer without messing up how they originally looked. We'll also dig into how it does this and figure out how to use some fancy advanced settings.
Moreover, the discussion highlights the model's flexibility through API integration, making it easy to incorporate into various workflows with programming languages such as Bash, Python, and JavaScript. In conclusion, users are encouraged to explore more examples, gaining a deeper insight into the diverse capabilities and creative applications of SSD-1B Depth.