Best SDXL Models for Image Generation & Transformation
We take a look at various SDXL models or checkpoints offering best-in-class image generation capabilities. From txt2img to img2img to inpainting: Copax Timeless SDXL, Zavychroma SDXL, Dreamshaper SDXL, Realvis SDXL, Samaritan 3D XL, IP Adapter XL models, SDXL Openpose & SDXL Inpainting.


In this blog post,we will explore its enhanced capabilities with specialized versions like Copax Timeless SDXL, Zavychroma SDXL, Dreamshaper SDXL, Realvis SDXL, and Samaritan 3D XL. These variations are fine-tuned to deliver exceptional image quality, showing improvements in color accuracy, contrast, and detail clarity. We will briefly cover SDXL Lighting models for blazing fast image generation. Additionally, we'll explore how the integration of the IP Adapter and ControlNet preprocessors further boosts the model's functionality, allowing for more precise and contextually rich image generation. Finally we will explore Inpainting capability of SDXL for image transformation.
SDXL Checkpoints
Fine-tuning the SDXL model involves integrating specialized datasets related to specific subjects or styles. This process sharpens the model's focus on particular themes, effectively merging its comprehensive knowledge base with a more focused expertise in certain areas. Checkpoints like Copax Timeless SDXL, Zavychroma SDXL, Dreamshaper SDXL, Realvis SDXL, Samaritan 3D XL are fine-tuned on base SDXL 1.0, generates high quality photorealsitic images, offers vibrant, accurate colors, superior contrast, and detailed shadows than the base SDXL at a native resolution of 1024x1024.
| Model | Use Case |
|---|---|
| Copax TimeLess SDXL | Varied and lifelike artistic images |
| Zavychroma SDXL | Magic-realism style with detailed focus |
| Dreamshaper SDXL | Dreamlike images for various media |
| RealVis SDXL | Hyper-realistic human figures |
| Samaritan 3D XL | 3D cartoon characters |
Copax Timeless SDXL
The Copax TimeLess SDXL is a versatile diffusion model, offering an expansive range of artistic styles far beyond genre constraints, especially in rendering detailed characters and facial expressions, thanks to its roots in the reliable SDXL 1.0 architecture. This combination of style diversity, detailed realism, and proven foundation makes Copax TimeLess SDXL a standout choice for creating varied and lifelike images.

Zavychroma SDXL
Zavychroma SDXL, the successor to the ZavyMix SD1.5 model, has been reengineered for the SDXL framework, embodying a unique blend of magic and realism. Transitioning to SDXL, it not only maintains its distinctive aesthetic but also improves image quality and coherence, with a focus on complex details like eyes and teeth. Key advantages include enhanced realism, particularly in rendering intricate features, and delivering high-quality results without the need for a refiner, simplifying the creative process.

Dreamshaper SDXL
Dreamshaper XL is designed for transforming text prompts into vivid, dreamlike images. Initially developed to turn text, dreams, and descriptions into visually intense representations, it has become a go-to tool not just for artists, but also for professionals in gaming, cinema, advertising, and graphic design. Built on the SDXL framework, Dreamshaper XL features adaptable checkpoints on SD, enabling the creation of a wide array of visuals, from realistic video game characters and digital art to classical paintings.

Realvis SDXL
RealVis XL, leveraging the SDXL framework, excels in creating hyper-realistic images, particularly human figures. Its strength is in producing details so lifelike — skin and hair textures, body proportions — that they are virtually indistinguishable from real life.

Samaritan 3D XL
Samaritan 3D XL is grounded in the SDXL framework, specifically tailored for crafting 3D cartoon characters. It's an ideal tool for animators, game developers, and digital artists who aim to create emotionally rich and whimsical cartoon characters in 3D. Utilizing the robust SDXL framework, it ensures detailed and high-quality renderings, capturing the essence and expressiveness of cartoon characters.

SDXL Lighting Models
SDXL Lightning models are known for their remarkable speed, efficiency, and exceptional image quality. They offer offers numerous benefits, including Rapid Image Generation, High-Quality Image Generation, and versatility for its the ability to generate images for various purposes efficiently (Such as Photorealistic Image Generation and so on). We have curated some of the best SDXL lighting models available on Segmind. Each of these models brings something unique to the table, making them all excellent choices for different text-to-image generation needs. Do check them.

SDXL with IP Adapter & ControlNet Preprocessors
The IP-Adapter is a cutting-edge tool created to augment pre-trained text-to-image diffusion models like SDXL. It uniquely allows SDXL to utilize both an image prompt (IP Image) and a text prompt simultaneously. By integrating with ControlNet preprocessors like Canny, Openpose, or Depth, the IP-Adapter enhances the flexibility and creativity in image generation, harnessing the combined strengths of textual and visual inputs.
| Model | Ideal Scenario |
|---|---|
| IP Adapter Canny XL | Scenarios requiring precise edge and contour definition in images |
| IP Adapter Depth XL | Applications needing realistic depth and spatial representation |
| IP Adapter OpenPose XL | Accurately rendering human poses in images involving human figures |
IP Adapter XL Canny
In the IP Adapter XL Canny, the Canny edge preprocessor extracts outlines from an input image, which helps in preserving the composition of the original image. The IP Adapter allows the SDXL model to use both an image prompt and a text prompt simultaneously. This dual-input capability enables the model to blend elements from both the input image and the image prompt, with the text prompt providing iterative refinement. The result is the creation of complex images that are rich in context, seamlessly integrating aspects of both the visual inputs under the guidance of the text prompt.

IP Adapter XL Depth
In the IP Adapter XL Depth, the Depth Preprocessor extracts depth cues from images, which helps in understanding and recreating the spatial dimensions of the original scene. Working in tandem with IP adapater, it enable the generation of images that are not only detailed but also exhibit a rich sense of contextual depth. They effectively blend elements from both the original image and the image prompt, with the text prompt serving to refine and guide the process.
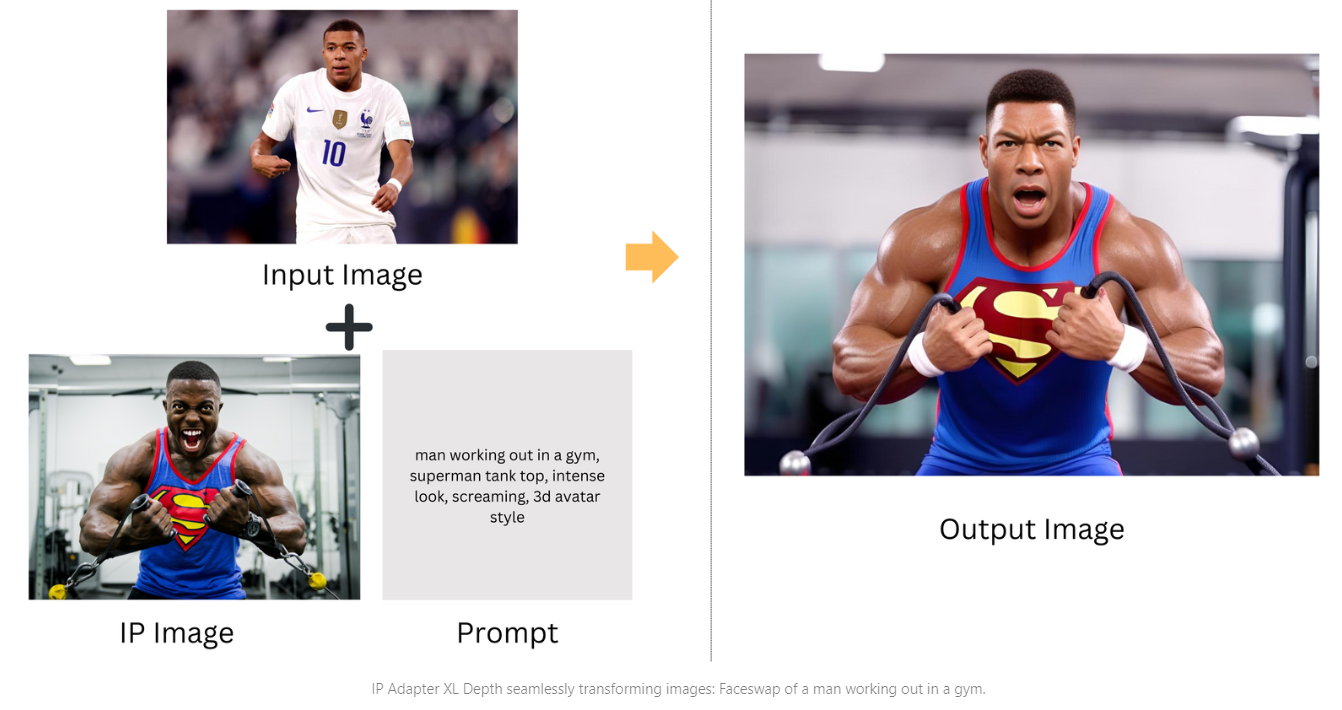
IP Adapter XL Openpose
In the IP Adapter XL Openpose, the Open Pose Preprocessor specializes in identifying and analyzing human poses and gestures within images, a key factor for accurately depicting human figures and their movements as seen in the original scene. The synergy with IP Adapter facilitates the production of images that are not only visually impressive but also rich in context, especially effective in scenarios that involve human subjects.

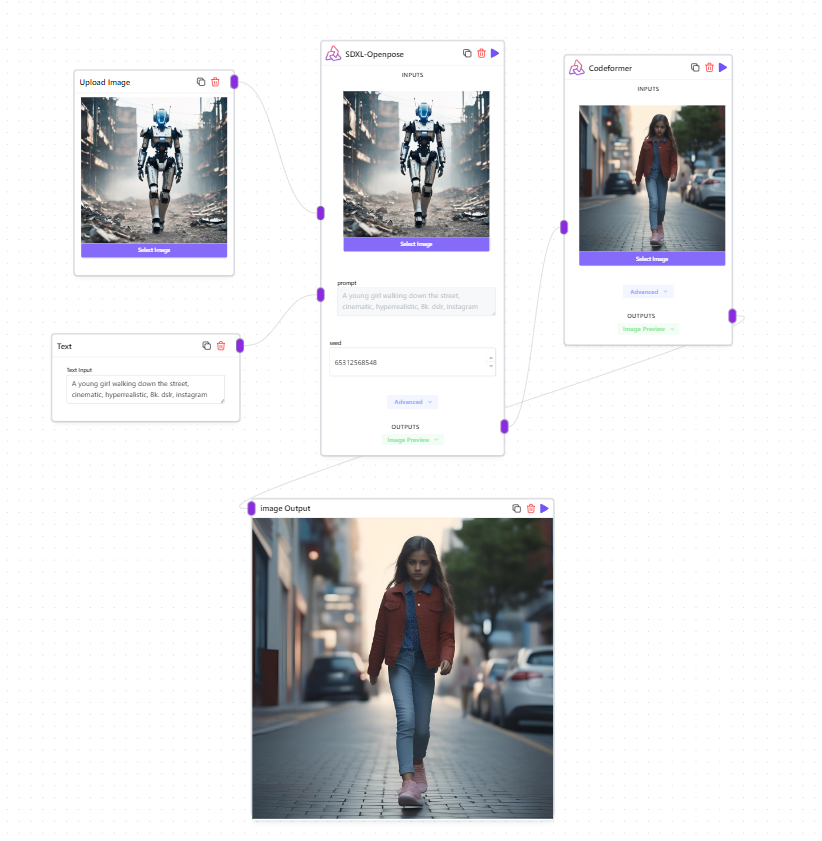
SDXL Openpose
The SDXL OpenPose, using the ControlNet OpenPose preprocessor, accurately learns and replicates human poses. ControlNet converts key pose points into a control map, which, when combined with a text prompt in the Stable Diffusion model, results in images that mimic original human poses with added creative flexibility.
SDXL Inpainting
The SDXL 1.0 Inpaint model is a sophisticated text-to-image diffusion model that generates photo-realistic images from text prompts. Its standout feature is inpainting, enabling precise image modifications using a mask. This enhances its capabilities in both image generation and editing. Inpainting involves altering specific image parts by using a mask to designate change areas (white pixels) and preservation areas (black pixels). The model processes these marked areas, adapting them to align with the input prompt.

Conclusion
This review of the SDXL model extensions highlights a substantial leap in image generation capabilites of SDXL. Each specialized model builds upon the base SDXL's capabilities, offering unique features for various artistic and realistic image creation needs. These advancements mark a notable evolution in AI-driven image generation, opening new creative possibilities across various industries.