SDXL Openpose: A Deep Dive into Effective Parameter Choices
A comprehensive guide to maximizing the potential of the SDXL Openpose model in image generation.


The SDXL Openpose Model is an advanced AI model that transforms the landscape of human pose estimation. the model seamlessly combines the control features of ControlNet with the precision of Openpose delivering an unmatched level of accuracy and control for human pose analysis within the Stable diffusion framework.
Crafted through the thoughtful integration of ControlNet's control mechanisms and OpenPose's advanced pose estimation algorithms, the SDXL OpenPose Model stands out for its ability to process visual data with exceptional precision. Let us take a look into the ControlNet architecture before we can find the best parameter values.
ControlNet Architecture
The ControlNet architecture is purpose-built to acquire a wide range of conditional controls. This is achieved through a distinctive technique called "zero convolutions," which utilizes zero-initialized convolution layers.
These layers incrementally develop parameters from zero, establishing a controlled and noise-free environment throughout the fine-tuning process. This method acts as a safeguard against the introduction of disruptive noise, thereby maintaining the integrity of the pre-trained model. Importantly, it facilitates the seamless integration of spatial conditioning controls into the model.
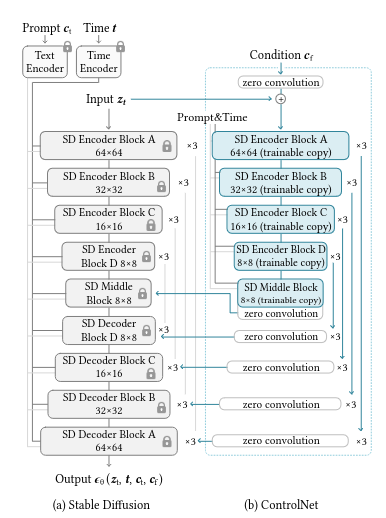
How does SDXL OpenPose work?
The SDXL OpenPose demonstrates its technical proficiency through the utilization of the OpenPose model. This model excels in learning intricate details of human poses, including the precise positions of hands, legs, and the head. The outcome is the accurate replication of human poses.
ControlNet plays a pivotal role in this process by converting these key points into a control map. This map, combined with a text prompt, is then input into the Stable Diffusion model. The result is the generation of images that replicate the original pose, while also granting users creative flexibility.
Selecting the best set of values for the parameters in the model:
1. Guidance scale
The guidance scale parameter significantly impacts how well the generated images align with the given text prompts. It serves as a crucial element in ensuring that the generated images accurately reflect the intended meaning and context of the input text prompts. When the value of the guidance scale is increased, the connection between the generated image and the input text becomes stronger. However, it's important to note that this enhancement in connection comes with a trade-off – higher values compromise the diversity and overall quality of the generated images
Input image and prompt:


Input image and prompt:


Examining the impact of prompts at various extremes highlights specific characteristics. When the guidance scale approaches a value of 1, there might be a slight compromise in artistic quality. Conversely, values exceeding 19 or 20 ensure strict adherence to the text but may also affect the overall artistic quality of the generated image.
The optimal range of values will be between 12 and 17. If your goal is to generate images that consist of intricate details as outlined by your prompt, it is recommended to select values within this specific range.
2.Steps
This parameter is about the number of denoising steps, representing the number of iterations in a process initiated by random noise derived from the text input. Throughout this iterative cycle, the model consistently refines the image by gradually removing noise.
A higher number of steps corresponds to increased production of high-quality images.
Input image and prompt:


The generation of high-quality images is observed in the range of 50 - 75, beyond this range the number of steps doesn’t seem to alter nor give a significant difference in the overall quality of the images.
It's important to highlight that if your goal is to generate images with a simple and clean appearance, lacking intricate details, the effective range falls between 25 and 40.
3.ControlNet Scale
This parameter influences the degree to which the image generation process adheres to the input image and the provided text prompt. A higher value results in a stronger alignment between the generated image and the provided image and text input.
However, setting the value to the maximum is not always advisable. Although higher values may appear to influence the artistic quality of the images, they don't necessarily translate to the intricate details required.
Example 1:


Example 2:


We get to see that the images generated exhibit intricate details when the Controlnet scale is set within the range of 0.3 to 0.6. Values above that range do not tend to offer an additional increase in artistic quality.
Reducing the Controlnet scale to lower values diminishes both the intricacy of details and the overall artistic quality of the generated images.
4.Negative prompt
This parameter allows users to specify the elements they wish to exclude from the generated images without providing explicit input. These prompts guide the image generation process, directing it to avoid certain features based on user-provided text.
By employing negative prompts, we can effectively block the generation of specific objects and styles, address image abnormalities, and enhance overall image quality.
Commonly used negative prompts include:
- Basic negative prompts: worst quality, normal quality, low quality, low res, blurry, text, watermark, logo, banner, extra digits, cropped, jpeg artifacts, signature, username, error, sketch, duplicate, ugly, monochrome, horror, geometry, mutation, disgusting.
- For Adult content: NSFW, nude, censored.
- For realistic characters: extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck.

With negative prompt :

Without negative prompt

5.Schedulers
Within the Stable Diffusion pipeline, schedulers play a pivotal role in collaboration with the UNet component. Their primary function is crucial to the denoising process, executed iteratively across multiple steps. These steps are instrumental in the transformation of a randomly noisy image into a clean, high-quality image.
Schedulers systematically eliminate noise from the image, generating new data samples in the process. Noteworthy schedulers in this context including Euler, and DDPM are highly recommended in general and might vary for particular contexts.