How to Face Swap in Stable Diffusion Using IP Adapter & ControlNet
Dive into the world of creative photo transformation with our easy-to-follow guide on Face Swap with Stable Diffusion XL (SDXL). Here, you'll learn to morph your images into your favorite hero characters using IP Adapter & ControlNet Depth.


Have you ever wondered how it would feel to see yourself in the shoes, or rather, the face, of your favorite superhero or iconic character? In today's digital age, the ability to blend reality with imagination opens up a realm of creative possibilities, and that's exactly what we're exploring here. This guide is all about turning that curiosity into a stunning reality. The process we're discussing goes beyond the basic face swap techniques you might be familiar with. We'll guide you through using the IP Adapter and ControlNet Depth, showing how you can combine just your photograph with the image of your favorite superhero.




IP Adapter & ControlNet Depth
The IP Adapter enhances Stable Diffusion models by enabling them to use both image and text prompts together. At its core, the IP Adapter takes an image prompt (referred to as the IP image) and a text prompt, and merges attributes from both to generate a new, altered image. This composite image is then fused with the input image, which has been pre-processed using ControlNets like Canny, Depth, or Openpose. The result is a blended image that skillfully combines elements from the original images, all while being steered by the nuances of the text prompt. This process allows for a more integrated and cohesive result, marrying the visual cues from the images with the descriptive guidance of the text.
Integrating the IP Adapter with the ControlNet Depth Preprocessor greatly enhances the capabilities of the SDXL model. The IP Adapter enables the SDXL model to effectively process both image and text inputs simultaneously, significantly expanding its functional scope. The Depth Preprocessor plays a vital role in extracting depth data from images. This aspect is crucial for accurately interpreting the spatial layout of the original scene, a fundamental component in depth perception.
Faceswap with IP Adapter XL Depth
In the face swap process, we start by choosing a superhero-themed image as our input image. This input image is analyzed by the Depth Preprocessor to accurately grasp its spatial layout and depth, a crucial step for realistic depth perception in the final image. Alongside, we select an Image Prompt (IP Image), usually a person's photo, to set the scene for the final composition. A Text Prompt is also employed to clearly define the specific alterations desired in the IP Image. The IP Adapter then skillfully merges these components, blending the depth characteristics of the superhero image with the context of the IP Image, guided by the directives of the Text Prompt. This results in an image where the person from the IP Image is seamlessly integrated into the superhero setting, maintaining a natural depth and coherence with the Text Prompt's specifications. The outcome is a fluidly blended image where the individual appears to belong naturally within the superhero context.

Faceswap Examples
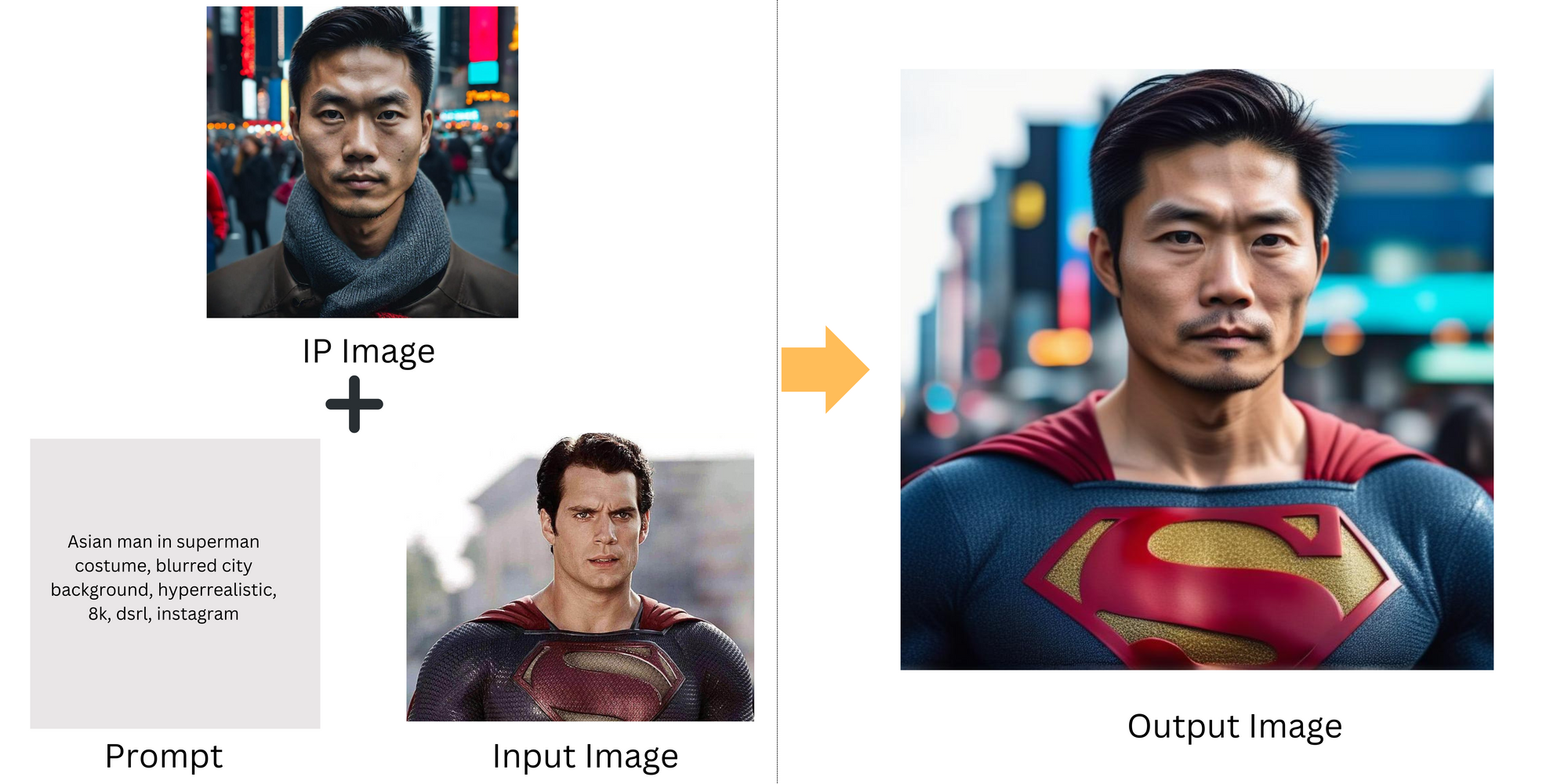
For an Superman face swap, we start with a Superman image and analyze it for depth and dimension. Then, we take a photo of an Asian man as the Image Prompt (IP Image) and use a Text Prompt to guide the transformation. The IP Adapter combines these, blending the man's features with the Superman image while keeping the depth intact. The result is a seamless blend where the Asian man appears naturally as Superman, matching the superhero's iconic look.
For an Iron Man face swap, we first choose an Iron Man image for its depth and dimensional analysis. Next, an Image Prompt (IP Image), perhaps a photo of an individual, is selected for transformation. A Text Prompt is used to direct the specific changes needed for the Iron Man context. The IP Adapter then merges these elements, integrating the individual's features into the Iron Man image, ensuring the depth remains realistic. The end result is a seamless fusion, where the individual appears naturally in Iron Man's suit, aligned with the iconic character's style.

In an Indiana Jones face swap, we begin with an image of Indiana Jones for its spatial and dimensional analysis. Alongside, we select a photo of a person as the Image Prompt (IP Image) for the transformation. A Text Prompt is used to specify the desired changes fitting the Indiana Jones theme. The IP Adapter merges these inputs, adapting the person's features into the Indiana Jones image while maintaining realistic depth. The final outcome is a smooth integration, where the individual appears as a natural part of the Indiana Jones scene, resonating with the adventurous essence of the character.

For a Captain America face swap, the process starts with an image of Captain America, analyzed for its spatial depth and dimensions. Next, a person's photo is chosen as the Image Prompt (IP Image) for transformation. A Text Prompt defines the specific alterations needed to align with the Captain America theme. The IP Adapter then expertly merges these elements, embedding the person's features into the Captain America image, ensuring the depth remains true to the original. The end result is a seamless blend, where the individual appears naturally in Captain America's attire, perfectly capturing the character's iconic look.

Conclusion
In conclusion, the face swap process, utilizing the IP Adapter and Depth Preprocessor, demonstrates its versatility and effectiveness across various themes, from superheroes like Superman and Captain America to iconic characters like Indiana Jones. Each example highlights the ability to seamlessly integrate an individual's features into a chosen theme while maintaining depth and realism. This technology not only transforms images but also preserves the essence of the original character, resulting in a harmonious blend that resonates with the character's iconic style. This process exemplifies the remarkable potential of modern image editing, offering a creative and immersive way to reimagine personal photos in the context of beloved characters.
Note: While exploring the exciting world of face swap in Stable Diffusion, we urge you to practice responsible use. This technology, while powerful and innovative, should be used with respect for privacy and ethical considerations. Always seek consent when using someone else's image and avoid creating content that is misleading, harmful, or violates any legal guidelines. Let's ensure that our creative explorations contribute positively and responsibly to the digital community.
*Sign up on Segmind now and receive 100 free inferences every day.