A Comprehensive Guide to Distilled Stable Diffusion Models
We will explore a range of distilled models of Stable Diffusion, providing a comprehensive guide on the concept of distillation, its purpose, and the architecture of these various models.


Although diffusion models showcased remarkable performance in generative modeling, one drawback they faced was the prolonged sampling time. This resulted in advancements in image generation models to reduce the sampling time as well as increase the quality of images generated.
In the blog post, we will take a look into various distilled version models of Stable Diffusion through an in-depth guide on what is distillation, why it is done, and also the architecture of various models.
Introduction
In these models, diffusion operations unfold within a semantically compressed space. The overall process is twofold. First, it adds up noise to the data called forward diffusion and then it proceeds to remove this noise which is called reverse diffusion.
Before getting into the concept of distillation, it's essential to develop a clear understanding of the components inherent in this framework and comprehend how they contribute to the necessity for distillation
Components that aid this process:
Stable diffusion is a latent diffusion model and it operates in latent space which consists of the compressed information of the image. The components are
- Variational AutoEncoder
- U-Net
- Text Encoder
- Schedulers
When the data is given, U-Net performs iterative sampling to gradually remove the noise from the randomly generated latent code while the text encoder and image decoder support the U-Net to generate images that align with the prompt specified. The presence of a Variational autoencoder is to compress the image to a lower dimensional space in the latent space.
Conditioning plays a vital role in guiding the 'noise predictor,' analogous to a car, ensuring it steers toward the desired direction, ultimately yielding the intended resultant image.
However, the presence of all these components, while crucial for image generation, contributes to a computationally expensive process. The primary bottleneck lies in the sampling speed, attributable to the limited conditioning information available to the model.
What is Knowledge distillation and what does it do?
Knowledge distillation revolves around the concept of a teacher guiding a student, where the smaller model endeavors to emulate the behavior of its larger counterpart. In essence, it entails a form of compression, allowing the seamless transfer of knowledge from the larger model to the smaller one, all without compromising performance.
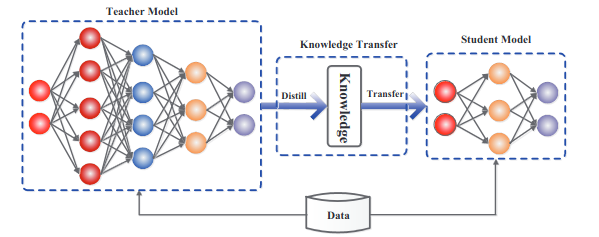
In Knowledge distillation, the knowledge type and the distillation strategies play a crucial role in student learning. A vanilla knowledge distillation process uses logits of a large model as the teacher model, sometimes the activations of and features of the intermediate layers are also used as the knowledge to guide the student, etc.
Knowledge distillation not only helps in reducing the size and complexity of the model but also helps in improving the computational requirements needed to run the model.
Distilled Stable diffusion
To increase the efficiency of computation for text-to-image generation models various methods are used from using a pre-trained diffusion model to reduce the number of denoising steps to enabling an identical architectural model with fewer sampling steps, to post-training quantization methods and removal of few architectural elements in the diffusion model in itself.
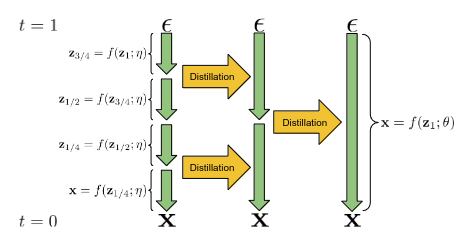
In the paper “ Progressive Distillation for Fast Sampling of Diffusion Models”, the idea was to have a progressive distillation with the teacher model which was trained in the standard way, and later initialize a student model using the same parameters of the teacher model however the difference arose in the way the target for the denoising model.
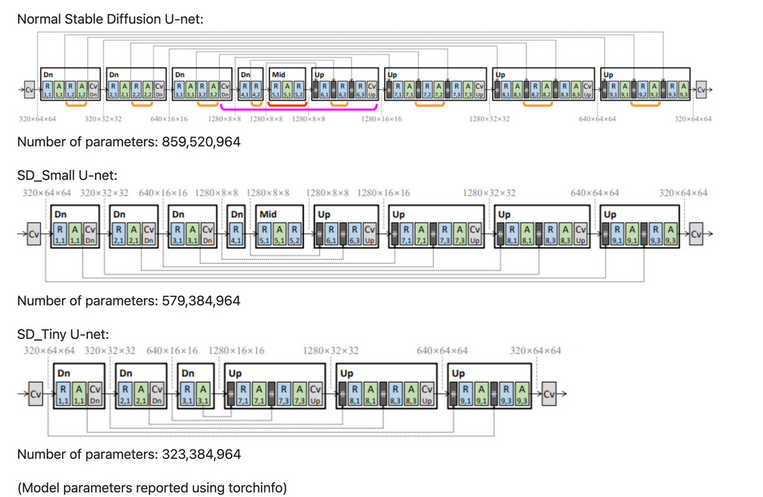
In the paper titled “BK-SDM: A Lightweight, Fast and Cheap Version of Stable Diffusion”, the core idea was to remove architectural blocks from the U-Net present in Stable diffusion architecture and reduce the size as well improving the latency.
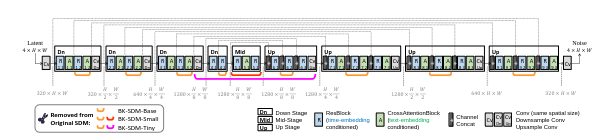
Types of Distilled Stable Diffusion models
While there are various types of distilled versions of the Stable diffusion models, we at Segmind have introduced a variety of distilled models in response to the escalating demand for accessible and efficient AI models. These models, tailored to address the constraints of computational resources, enable a more expansive application across diverse platforms.
Tiny and Small SD
The Tiny and Small SD models have been developed, inspired by the ideas presented in the paper shown previously, These models have 35% and 55% fewer parameters than the base model, respectively, while maintaining comparable image fidelity. You can find our open-sourced distillation code in this repo and pre-trained checkpoints on Huggingface.
In the knowledge distillation training process, three key components contribute to the loss function, each playing a distinct role. Firstly, the traditional loss captures the disparity between the latents of the target image and those of the generated image. Secondly, there is a loss between the latents of the image generated by the teacher model and the student model. However, the most pivotal component is the feature level loss, emphasizing the discrepancy between the outputs of each block in both the teacher and student models. Together, these components form a comprehensive framework for effective knowledge distillation in Tiny and Small SD Models.
Realistic-Vision 4.0 has been taken as the base teacher model and has been trained on the LAION Art Aesthetic dataset with image scores above 7.5, because of their high-quality image descriptions.
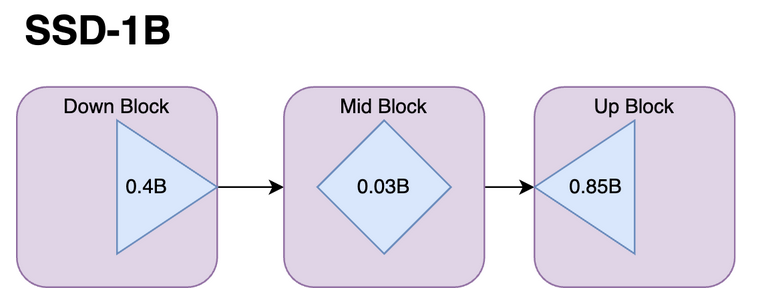
SSD-1B
SSD-1B is 50 percent more compact than SDXL and several layers have been removed from the standard SDXL model.
The major change present in this distilled model is how there has been a reduction in the size of the model. The transformer blocks inside the attention layers have been removed alongside the Attention and Resnet layer in mid-block. The Unet block has been progressively distilled by making it shorter in each stage. The model has been trained on GRIT and Midjourney scrape data.
A few images generated using SSD-1B:





Segmind Vega
Probably the fastest image generation model which achieves an impressive 100% speedup with a 70% reduction in size from the original SDXL model. While SSD-1B consists of 1B parameters, this tends to reduce the size even further and has only 745 million parameters. This leads to its blazing-fast image generation time.
Segmind Vega is a symmetrical and distilled iteration of the SDXL model. It not only reduces size by over 70% but also enhances speed by 100%. The Down Block comprises 247 million parameters, the Mid Block has 31 million, and the Up Block contains 460 million. Beyond the size discrepancy, the architecture closely mirrors that of SDXL.
A few images generated using Segmind Vega:





Conclusion
The adoption of knowledge distillation in models such as SSD-1B and Segmind Vega has proven instrumental in overcoming challenges associated with size and computational efficiency. Achieving remarkable speedups with significant reductions in model size underscores the efficacy of distillation techniques in enhancing the practicality of AI models. By transferring knowledge from larger models to smaller counterparts, we strike a balance between efficiency and performance.
However, it is also crucial to understand the fact these models are still early phases of the advancement of image generation models and have their fair share of limitations. The journey of building more efficient and powerful image generation models has just begun with the promise of numerous breakthroughs and advancements yet to come.