Nvidia's Power Play: Will They Control the Future of Generative AI?
In the high-stakes game of artificial intelligence (AI) innovation, Nvidia Corporation is making bold moves that could potentially reshape the future of the industry.


Nvidia is the enigmatic powerhouse of technology, that has wielded its silent influence for decades, subtly molding our lives from the early gaming CPUs to the forefront of artificial intelligence (AI). With a name derived from the Latin word for envy, "invidia," Nvidia is poised to reshape the very fabric of the tech industry.
Even as the company's shares continue to soar, due to its strong positioning in the AI revolution, Nvidia is not resting on its laurels. Instead, it’s taking the lead in defining AI’s future in novel areas making strategic counterstrikes against emerging competitive threats, particularly in the realm of generative AI. In this article I wanted to delve into Nvidia's power play, exploring its vertical integration strategy, the role of its community, and its ambitious plans for the future from the perspective of a long-time follower and founder of an AI startup.
So will Nvidia's maneuvers enable it to control the future of generative AI? Let's unpack the story.
The Nvidia Story

Nvidia was founded in 1993 by Jen-Hsun “Jensen” Huang, Chris Malachowsky, and Curtis Priem who had previously worked together at Sun Microsystems, aimed to focus on the burgeoning market for graphics processing units (GPUs), which are essential for creating visual effects in video games.
The company's first product, the NV1, was released in 1995. However, it was the introduction of the RIVA series of graphics cards in 1997 that truly put Nvidia on the map. These cards offered superior performance at a lower cost, making them a hit among PC gamers.
In the early 2000s, Nvidia began to diversify its product line. It launched the GeForce series, which quickly became a popular choice for both gaming and professional applications. Around the same time, the company also entered the market for integrated graphics processing units, which are used in laptops and other mobile devices. In recent years, Nvidia has expanded beyond graphics processing and moved into the AI and data center markets. The company's GPUs are now used in everything from powering AI algorithms to facilitating cryptocurrency mining. This strategic evolution has helped Nvidia become one of the leading technology companies in the world.
From Graphics to Neural Networks: The Rise of GPUs in Machine Learning
A Graphics Processing Unit (GPU) is a specialized chip designed to accelerate the creation of images in a frame intended for output to a display device. GPUs are very efficient at manipulating computer graphics and image processing, and their highly parallel structure makes them more efficient than general-purpose CPUs for algorithms where the processing of large blocks of data is done in parallel.
The relevance of GPUs for machine learning comes from their ability to process large blocks of data in parallel. Machine learning, and particularly deep learning, involves the manipulation and analysis of high-dimensional data called Tensors. In order to train a deep neural network, GPUs enable matrix multiplications, a type of operation that can be parallelized very effectively.
GPUs, with their thousands of cores, can perform many operations simultaneously, making them well-suited to the task. This has led to a significant speedup in machine learning model training times, making more complex and larger models feasible to train.
Nvidia, one of the leading manufacturers of GPUs, recognized this potential early on and developed CUDA, a parallel computing platform and application programming interface (API) model, that allows developers to use Nvidia GPUs for general-purpose processing – an approach termed GPGPU (General-Purpose computing on Graphics Processing Units). This has made Nvidia's GPUs a popular choice for machine learning and other data-intensive tasks since developers essentially could customize the raw computing power to whatever need or application they wanted.
The Surge of Deep Learning
By 2011, advancements in GPU speeds enabled the training of convolutional neural networks without layer-by-layer pre-training, highlighting the efficiency and speed of deep learning. A notable example is AlexNet, a convolutional neural network that won several international competitions in 2011 and 2012. In 2012, Google Brain conducted an experiment known as "The Cat Experiment," which explored the challenges of unsupervised learning. The experiment involved a neural net spread over 1,000 computers, which was shown ten million unlabeled images from YouTube. The training software identified recurring patterns, with one neuron responding strongly to images of cats and another to human faces, demonstrating the potential of unsupervised learning in deep learning.
Nvidia released cuDNN, a CUDA-based library for Deep Neural Networks around September 2014 to double down on deep learning use cases. Although it received mixed reviews early on, over the next few years it became common for higher-level frameworks such as Tensorflow and PyTorch to use cuDNN interface for GPU computation.
In 2014, the Generative Adversarial Neural Network (GAN) was introduced by Ian Goodfellow. GAN involves two neural networks competing against each other, with one network attempting to imitate a photo convincingly enough to trick its opponent into believing it's real. The opponent, on the other hand, searches for flaws in the imitation. The game continues until the imitating network can create a near-perfect photo that deceives the opponent. This approach has been used to perfect products and, unfortunately, has also been exploited by scammers to steal identities and commit financial fraud.
Transformers And The Genesis of Generative AI
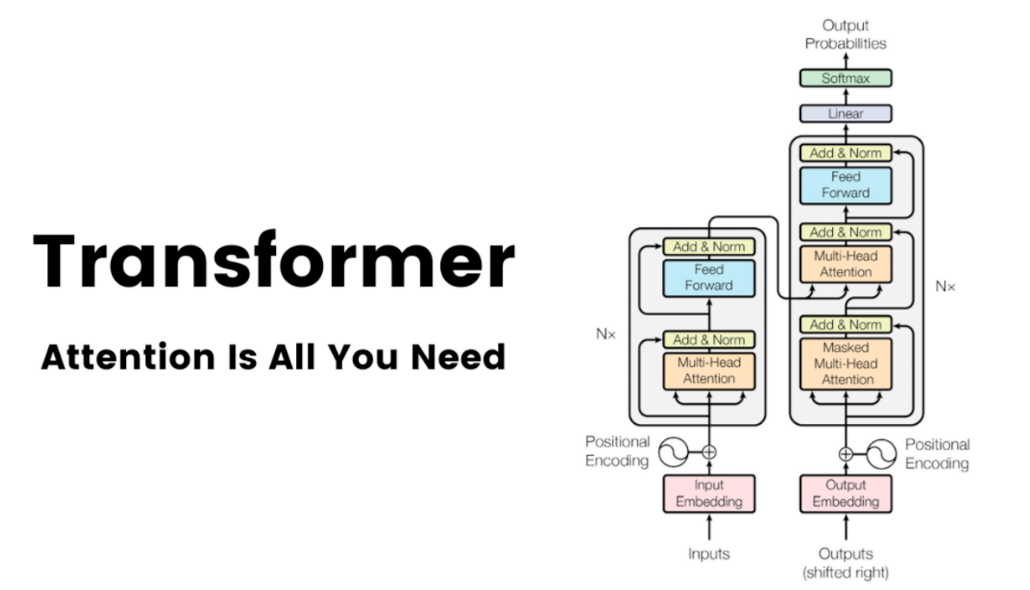
In 2017, "Transformers" were introduced by Google in a paper titled "Attention Is All You Need". This model, based solely on attention mechanisms, marked a departure from the dominant and complex recurrent or convolutional neural networks in an encoder-decoder configuration.
This created a new set of models and capabilities initially in the next generation and machine translation applications. Transformers were later adopted to build image and speech models that surpassed the capabilities of older models by a large margin, making them a go-to approach for a wide variety of use cases.
As model capabilities improved, the sizes of these models grew. Larger models performed better and model sizes quickly grew from a few GBs to hundreds of GBs over the last 3-4 years. GPU memory became the bottleneck and there was a need to use multiple GPUs in parallel to train and deploy these models. The original ChatGPT model, based on the GPT-3.5 architecture, was designed to run on multiple GPUs (8 to 32). However, OpenAI has made optimizations to the model to enable it to run on a single large GPU, which significantly reduces the computational resources required. Similarly, our open-source library voltaML has significantly reduced the GPU resources required to run stable diffusion models, a text-to-image model.
Training these models still requires 100s of GPUs. When it comes to inferencing, speed is the key. It determines the model usability for practical applications, controls the user experience, and creates new avenues for novel applications. Although GPU inferences are faster than CPU inferences, a lot can be done to make them more efficient.
Paving the Way for the Future of Machine Learning
More memory (and bandwidth)
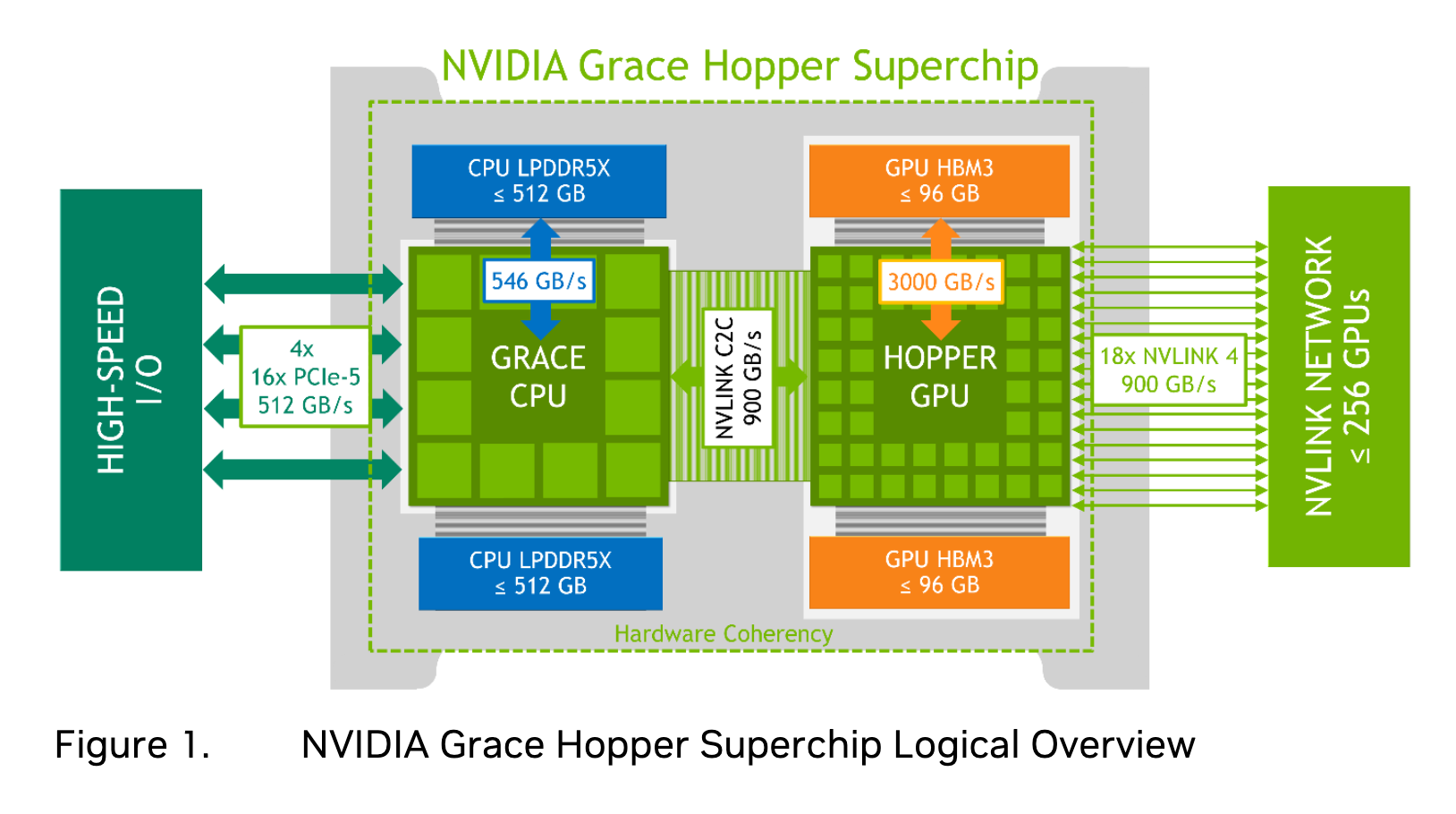
As model sizes grow, training and inferencing these massive models will require new architectures with fast access to a large pool of memory and tight coupling of the CPU and GPU. NVIDIA recently announced Grace Hopper, a new chip designed for superior performance for High-Performance Computing (HPC) and Giant AI Workloads. The NVIDIA Grace Hopper architecture combines the powerful NVIDIA Hopper GPU and the NVIDIA Grace CPU, interconnected by the high-bandwidth and memory-coherent NVIDIA NVLink Chip-2-Chip (C2C) technology.
This integration forms a single Superchip with support for the new NVIDIA NVLink Switch System. The NVIDIA NVLink C2C interconnect provides a remarkable total bandwidth of up to 900 GB/s, offering 7 times more bandwidth than the commonly used x16 PCIe Gen5 lanes in accelerated systems.
Better compilers
The world of machine learning and the widely used frameworks have all been designed around the model creators or modelers, a person who designs, builds, and trains machine learning models. They are responsible for coming up with new architectures and models, emerging every few years. However, this rapid pace of change can be problematic for compilers, which take framework models as input and generate optimized codes as output and struggle to keep up with the latest developments.
Many popular architectures of the past have fallen out of use, and even newer models may not be stable or widely adopted. Some companies are exploring specialized hardware implementations that can better handle specific architectures. However, these solutions can take years to develop and may become obsolete before they are even released.
The future of compilers in the context of machine learning will involve adapting to rapid changes in the field, exploring specialized hardware and software implementations, producing stable and high-level code, and potentially dealing with disruptions caused by new hardware.
Looking into the future, we expect compilers to be as dynamic as new ML models entering the market every day. To keep up with the pace of innovation, newer LLMs may be trained to write low-level compilers for these ML models and automatically test their performance and latencies, and if required self adjusts the code to constantly keep improving.
Better orchestrators
For enterprise setups, GPUs are often used in clusters. A GPU cluster is a collection of computers each equipped with a GPU(s), enhancing computational capabilities, particularly for machine learning-related tasks. Clusters can be architected to achieve high availability (which redirects computation tasks amidst node failure), and high performance (leveraging multiple nodes for complex tasks). These clusters offer specific benefits depending on the computational requirements and resilience needed. Orchestrators, as the name suggests, orchestrate GPU clusters based on the volume of demand and complexity of the tasks at hand.
Efficient scheduling of distributed deep learning (DL) jobs in large GPU clusters is crucial for resource efficiency and job performance. In today's clusters containing thousands of GPU servers, running a single scheduler to manage all arrival jobs in a timely and effective manner is challenging, due to the large workload scale. The future of orchestrators lies in better scheduling algorithms that will support multiple job types, helping drive up overall cluster efficiency. Here are a few companies and projects worth mentioning in this space: MosaicML, Ray, PyTorch Lightning, and Nvidia Triton.
Nvidia's Battle: The Fight for Market Dominance
The primary threat to Nvidia comes from its largest cloud customers, such as AWS, Azure, and Google Cloud, producing their own chips for use in their data centers. These internally designed chips by Cloud Service Providers (CSPs) are better integrated into their servers and software designs, allowing for greater cost and processing efficiency. This could potentially lead to significantly lower demand for Nvidia’s chips, undermining Nvidia’s ability to command its current valuation.
Nvidia's Countermeasures
Despite these threats, Nvidia has been proactive in managing the risks. The company has been vertically integrating upwards by offering its own cloud services. In March 2023, Nvidia introduced its own cloud service, DGX Cloud, which provides enterprises with immediate access to the infrastructure and software needed to train advanced AI models. Nvidia offers access to its cloud services both directly and through partnerships with major cloud providers (probably, future competitors), like Microsoft Azure, Google Cloud, and Oracle Cloud Infrastructure.
Nvidia's strategy involves selling data center hardware to its partners and then leasing it back to run DGX Cloud.
This approach allows Nvidia to leverage its superior AI capabilities and brand power to attract businesses that want to invest in the highest-quality infrastructure available. By offering DGX Cloud services optimized for Nvidia’s GPUs, the company ensures the availability of cloud services that leverage the full potential of Nvidia’s technology, offering optimum performance and cost-efficiency.
Nvidia has also been building a strong developer community with its CUDA ecosystem. It consists of various components including general-purpose compute processors, parallel computing extensions for different languages, and accelerated libraries for quick application acceleration. The CUDA ecosystem goes beyond the CUDA Toolkit and the CUDA C/C++ programming language, providing users with the opportunity to optimize and accelerate their applications.
Since its inception in 2006, CUDA has gained significant popularity among researchers and developers. It has been extensively utilized in numerous applications and research papers. Additionally, CUDA has garnered support from a vast user base, with over 500 million GPUs equipped with CUDA capabilities found in notebooks, workstations, compute clusters, and supercomputers.
Lastly, at scale, it is still hard to orchestrate GPU nodes on a dynamic cluster setup such as via Kubernetes. Up until now, scaling machines using an orchestrator like Kubernetes has been solved for CPU workloads, but not effectively for GPU workloads. It is important to orchestrate different types of jobs such as real-time inferences, batch inferences, fine-tuning, etc. on a cluster to drive up overall compute efficiency.
Gaps
Although CUDA has become the de-facto library for machine learning applications and no other framework has even come close to CUDA's adoption, there are still some gaps that need to be filled for easier implementation and wider adoption. Many developers initially struggle to set up the dependencies required for CUDA, CuDNN, and PyTorch. Any new update or mismatch between any of the versions of these libraries leads to long debugging and reinstallation sessions, that are cumbersome and counterproductive.
Higher-level SDKs or abstractions that can give one-click all-in-one updates or reinstallation of these libraries, would provide a much-needed reprieve to ML developers. Adding to CUDA and CuDNN frameworks, deep learning compilers like TensorRT, AI Template, etc. have shown dramatic improvement in model performance. But again, implementation of these compilers and making them work with a model of your choice has not been the easiest of tasks for developers.
There is a need for higher-level abstractions for these compilers such as Segmind's voltaML, that can help unify different compilers into single, easily installable libraries, that can work out-of-the-box on a wide range of generative AI models.
Conclusion
While there are risks associated with Nvidia's strategy, including the potential for cloud providers to build their own AI-centric solutions and encourage clients to migrate completely to their in-house solutions, Nvidia is well-positioned to sustain its presence in the cloud industry. The company's endeavors are only likely to keep growing, whether it continues to focus on partnerships or increasingly serves enterprises directly. This expansion into the cloud helps sustain the value of Nvidia’s AI chips in the cloud industry, bolstered by a growing ecosystem around its chips and cloud services.
Nvidia, through strategic planning and comprehensive AI infrastructure, is well-positioned to lead in the growing AI market. Its success is attributed to its full-stack computing capacity and broad experience across silicon, software, application libraries, developers, and cloud incumbency, defined as a "10+ year well-honed turnkey model" against its competitors' less integrated "silicon-only solutions." Nvidia's market dominance hinges on its ability to meet the escalating demand for both top-tier and affordable mid-range chips, while competitors like AMD and Intel are making efforts to keep up. Given the enormous scale and potential growth of the AI sector, producing suitable chips is predicted to be a primary focus across the industry in the upcoming years.