Stable Diffusion: Common Pitfalls, Use Cases, and How To Handle Real-world Deployments at Massive Scale.
Stable Diffusion, what you must know. Common pitfalls, use cases, and how To handle real-world deployments at a massive scale.


The First Fundamental question: what is Generative AI?
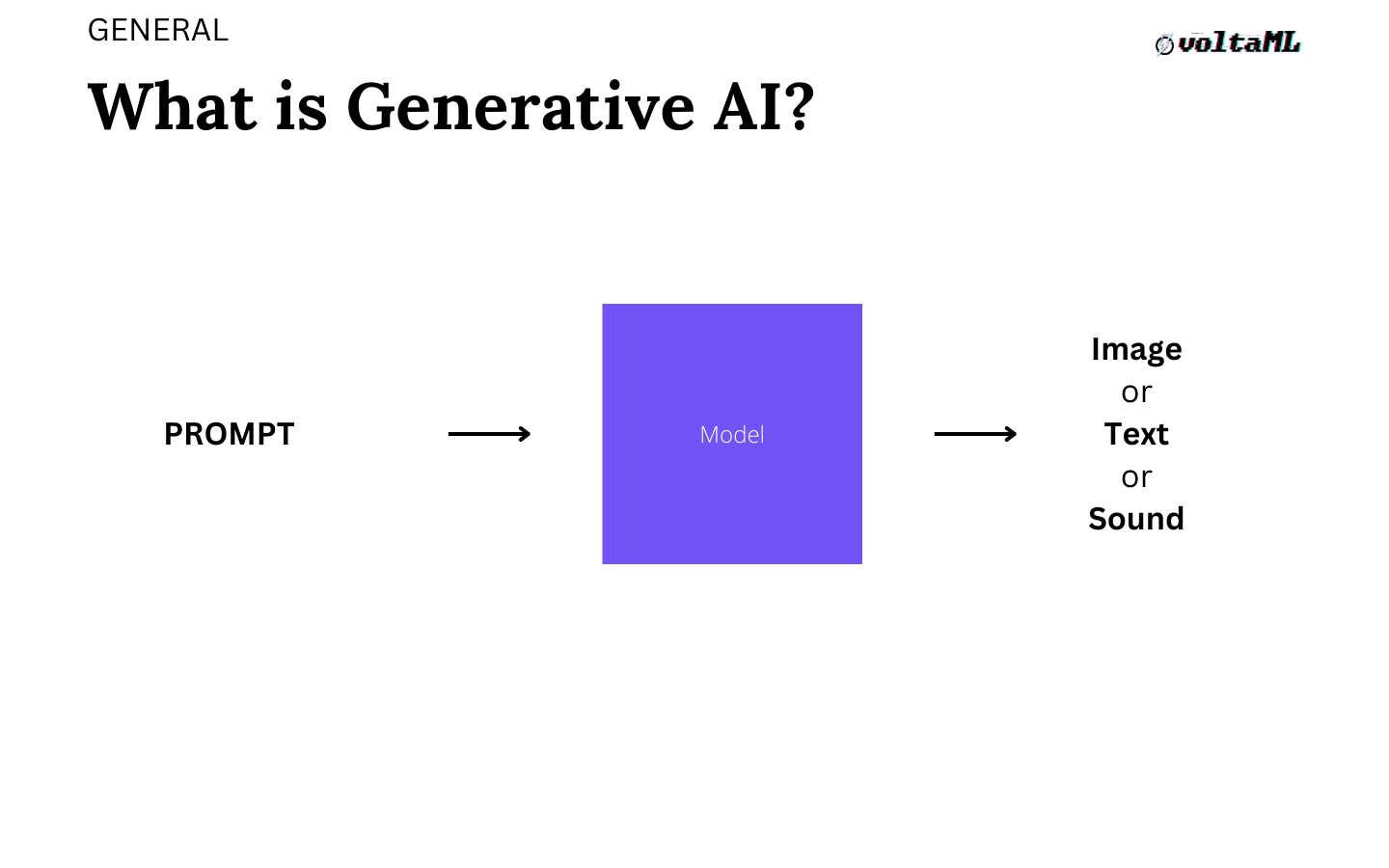
Generative AI is an algorithm that can be used to create new content which could include audio, code, images, or text.
A person sends in a prompt, which is a sentence asking to do something and the model takes that in and creates an image, text, or sound.
What is Stable Diffusion?

Stable diffusion is a very versatile generative AI model. It can be used in a few ways. The simplest way that it can be used is to create an image from text. You can send in a prompt, let's say 'cat' which is one word and the model takes that in on one side and creates an image for you as an output. You can also use it to edit an image which is technically called in-painting, where you parse an image and ask it to do some changes to it.
For example, you see (in the image above) that there is a photo of a dog and then you ask it to change the face to a 'face of a cat sitting on a park bench' and it creates an image with that dog replaced with a cat, and it does this pretty well. There are some challenges but the potential is so huge that a lot of apps are leveraging this technology to start editing images.
The Anatomy of Stable Diffusion.
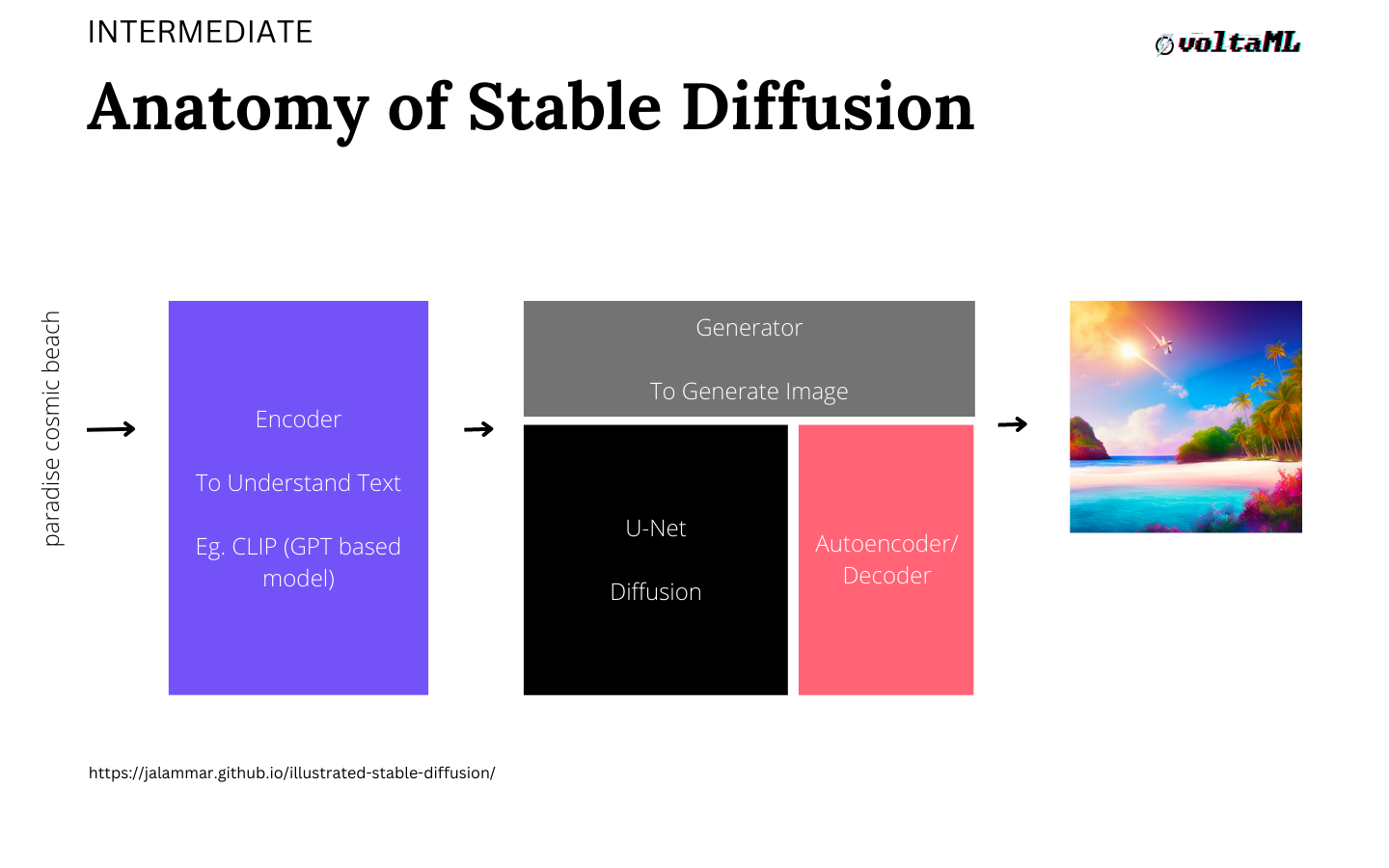
The architecture of stable diffusion takes a multi-model approach and it has three main components each of which has its own neural network.
Built-in, the first module in stable diffusion is the encoder module which is used to understand the text, so you parse in the text on one side and the 'encoder module' generates a few tokens for the downstream models to take in. Once the encoder creates these tokens, it sends them to something called a u-net architecture and this is where all the magic happens. There is a diffusion process happening, where you're searching for an image in a latent space and this process happens 20, 30, times, known as steps. The diffusion process is something that takes a noisy image and makes it a sensible image by the end of the whole process. Lastly, the tokens generated by the u-net as an array are passed to an autoencoder for it to generate the final image that you see on the screen.
Use cases


We see new use cases pop up almost every week because of the model's versatility. You can use stable diffusion in every industry, here are some of them.
Character creation (visual effects) is one, type in a detailed prompt that is maybe 20 to 50 words long and it will create that character for you.
E-commerce: instead of going and shooting different angles of a product with different backgrounds you could simply have a few images and use stable diffusion to put it in different backgrounds and different contexts depending on where you are marketing or what product it is.
Image editing: we're seeing a lot of use cases in image editing. Hundreds of apps have come out with in-painting as one of their core features where you can take an image and say change x. Let's say in the first image you have yellow flowers and you want purple flowers so you can prompt 'change the color of the flowers to purple' and it will output the same image with purple flowers.
Fashion: You can use stable diffusion to very organically change the clothes that someone is wearing. One can pick up a jacket and say 'hey, how will I look in this jacket'. It is going to transform the photo of you to one with you wearing the jacket and it looks very natural.
Gaming: we also have use cases in asset creation for gaming. We have seen a few companies use stable diffusion or slightly modified versions of stable diffusion to create assets. It would have taken a few weeks if not months for an artist to create these type of assets.
Web design: one can ask for different types of themes or color schemes and it's going to throw out different layouts and themes for you.
These are just some of the use cases we have seen. There are probably 990+ more that we cannot cover here, but this should offer a good understanding of what are the use cases for stable diffusion are.
Issues

GPU memory: As we keep adopting this technology, the biggest hindrance to using stable diffusion today is that it requires a lot of memory and it requires GPU memory. So smaller GPU cards less than 8 GB do not work well with Stable Diffusion today. A pretty large card is needed to really use stable diffusion. If you are creating large images at 1080p or larger resolutions, you will need a much larger GPU.
Artifacts: There's also a peculiar problem with artifacts getting created. This is something, some of you might have seen. For example, if you ask the model to create a human face or a hand, you might see a hand with six fingers or eight fingers or maybe three legs or four legs. This is because the model really doesn't know the fundamentals, unlike how humans understand. A good strategy to mitigate this is fine-tuning the model. We've seen people fine-tune only on human images so that the probability of this happening becomes very very small. In this case 99.99% of the time you will get a good-looking face or a standard without artifacts in the image.
Prompt engineering is learning what words to put into the prompt. For example, if you want a very real-looking image you might need to have a keyword called 'hyper-realistic' added to the model. Prompt engineering is something that's becoming very common. People are understanding how prompts work, to try and create products around them.
Large images: Another challenge with stable diffusion is generating large images. This is of course tied up to VRAM or the GPU memory issues that we spoke about. Today, it is almost impossible to create 4K images or a video from Stable Diffusion. Of course, this looks like something that would be fixed over the next six months or one year as we lower memory footprints and get larger graphic cards.
Copyright issues: Finally, images that Stable Diffusion generates might have copyright issues. You'll need to be careful. Let's say you ask for an image of a car to be used on your blog, it might generate an image with a car with Ford's logo or Tesla's logo on it. You might want to double-check the image before using it commercially.
Pitfalls

Stable diffusion is a multi-model architecture where two important libraries are being used: diffusers and transformers. Setting up the right dependencies or versions is very critical for the right functioning of stable diffusion. Any new updates, upgrades, or downgrades to either of these libraries may result in incompatibilities and improper output generation of the images. We have faced some backward compatibility issues, for example, the upcoming new schedulers in the diffusers library.
Large memory footprints: checkpoint files of these stable diffusion models can range from 2 GB to 12 GB in memory. Managing these models directly on a GPU becomes very challenging during training as well as inference. They usually lead to out-of-memory issues while generating high-resolution images.
Stable diffusion has a multi-model architecture where three models are loaded simultaneously during inference. Improper loading of these models into the inference pipelines may lead to memory leakages or excess memory expansion in the VRAM during inference.
Schedulers: schedulers are algorithms that determine the de-noising rate and quality of noise in an image. There are more than 10 types of schedulers for the de-noising loop available as of today. Selecting the right type of scheduler impacts the image quality and the generation time of the image.
On the right (in the image above) we have two images displayed, generated using the same prompt and the same parameters configurations. The funny part is, configuring the scheduler incorrectly can lead you to generate some horrifying images similar to the one at the top. This is a case where we messed up with a scheduler.
VoltaML
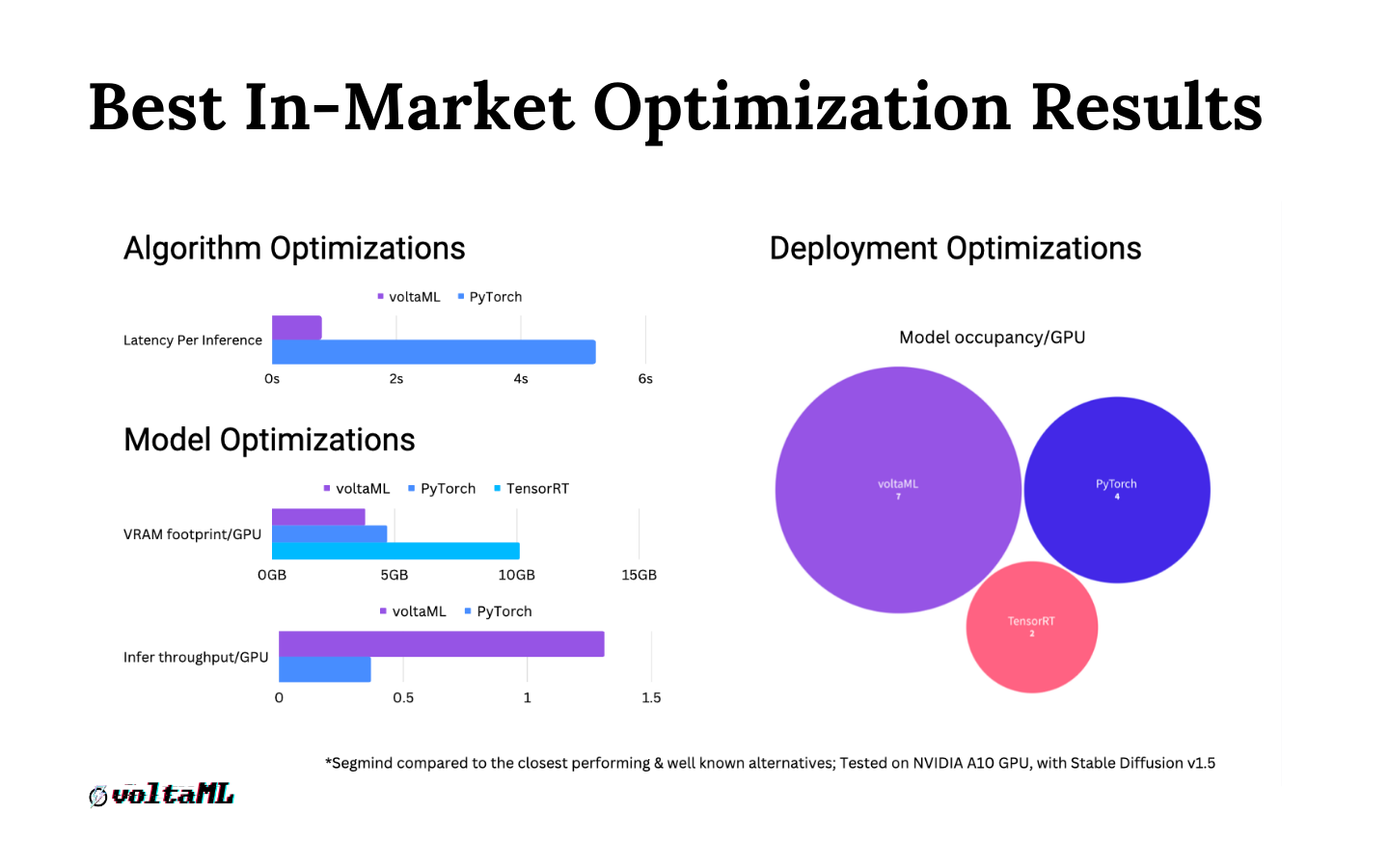
Based on the above challenges mentioned, we discovered a few optimizations for stable diffusion using TensorRT. TensorRT is a framework based on Nvidia CUDA parallel programming model that helps us to optimize the model inference and accelerate its performance. TensorRT performs several significant transformations and optimizations to the neural network graphs including folding, pruning of unnecessary graph nodes, and layer fusions. voltaML leverages these to convert model checkpoint files to TensorRT engine files. We apply multiple optimizations on the models such as lowering the precision to FP16, layer folding, pruning, etc, for faster inferences from the models. We have also applied the attention layers from The flash attention library. We have seen a 5x to 10x improvement in performance with all these optimizations.
Other than inference speed, we also worked on improving the memory requirements. We use static batches which lowers the VRAM usage dramatically. We also eliminated the loading of redundant and unnecessary packages during inferencing, which also help to lower the v-ram usage and increase the efficiency of the model. Try it out for free on Github
Deployment optimizations

For deployments, we use Nvidia Triton servers to serve models efficiently. We have observed that Triton is capable of serving parallel models at the same time and has better CUDA core utilizations and optimizations without giving any code errors and memory leakages. Handling parallel requests at the same time is a task that Rest API Services need to handle. These are a few of the optimizations and advancements we have built at voltaML.
For more information stay tuned for future platform updates.
Try out voltaML on Github & give us a star
https://github.com/VoltaML/voltaML
There is a new model out in the stable diffusion series called SDXL 1.0. If you are interested in using the latest SDXL 1.0, read more about the model and best settings for SDXL here.