Introducing Segmind Stable Diffusion Word to Image


The world of art is about to change forever. With the introduction of Segmind Stable Diffusion Word to Image, anyone can now create stunning and unique artworks with just a few words.
This innovative AI-powered tool uses a technique called "text-to-image synthesis" to transform words and descriptions into visually stunning art pieces. Simply upload any image of consisting of a word, provide a simple prompt of the expected output image, and the model will generate a unique and original artwork that reflects your inspiration with the word embedded within the image.
The possibilities are endless. You could create custom apparel designs, personalised home decor, book covers, or advertisement visuals. The model can even be used to generate educational materials, tattoo designs, and more.
The Segmind Stable Diffusion Word to Image model is trained on a massive dataset of images and text, which allows it to understand the nuances of words embedded in an image. This results in artworks that are not only visually stunning, but also relevant to a particular anchor word from the input image.
The technical backbone of this model is the Stable Diffusion 1.5 ControlNet. Essentially, it's trained on pairs of images that include words and various forms of art, with an architectural extension to the UNET module. ControlNet, the unique neural network structure at the heart of the model, bolsters diffusion models by introducing extra conditions. It replicates the weights of neural network blocks into a "locked" copy and a "trainable" copy, where the trainable copy learns your condition and the locked copy preserves the initial model. Thus, large diffusion models such as Stable Diffusion can be enhanced with ControlNets to accommodate conditional inputs like edge maps, segmentation maps, keypoints, etc.
Whether you're a creative professional or simply someone who loves to express themselves, Segmind Stable Diffusion Word to Image is the perfect tool for you. With this powerful tool, you can now bring your ideas to life in a way that was never before possible.
How does it work?
Segmind Stable Diffusion Word to Image uses a technique called "diffusion modelling". Diffusion models are a type of generative model that are trained on a dataset of images. The model learns to create new images that are similar to the images in the dataset. In this case the model has been trained on a dataset of images consisting of words embedded within them. It then combines the words from the input image with the an image generated from a prompt provided by the user using ControlNet.
The diffusion models are not simply trained to copy the images in the dataset. They are also trained to understand the relationships between different elements in an image. This allows the model to generate new images using user given prompt, that are not only consists of the word from the input image, but also creates images that are creative, artistic and original.
How to use it
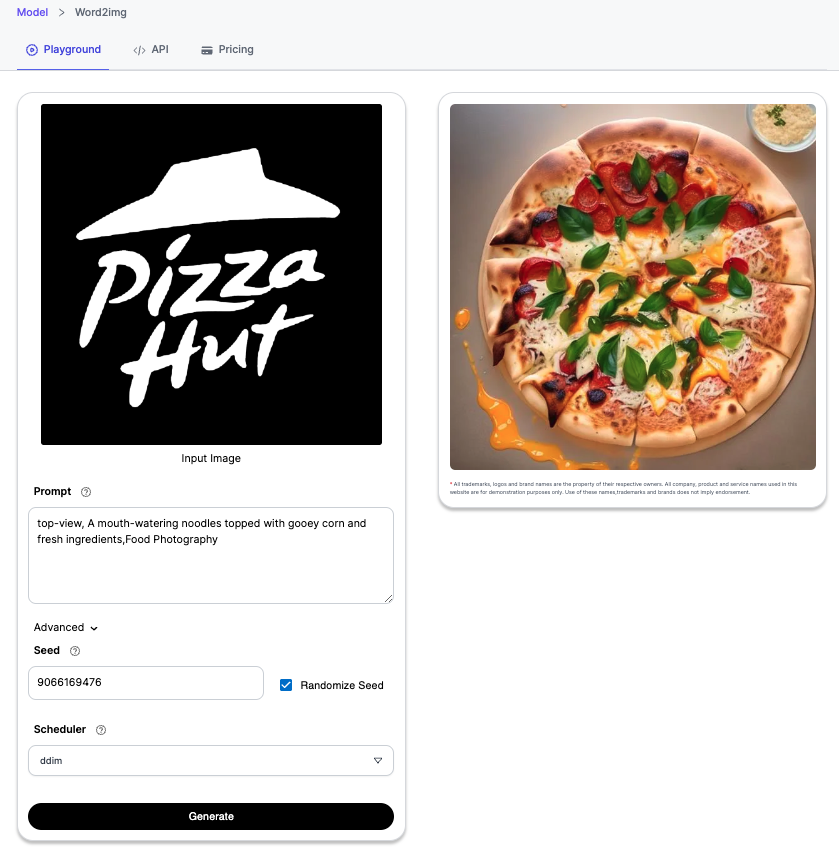
To use Segmind Stable Diffusion Word to Image, you will first need to upload an image of your choice consisting of a clearly identifiable word and then simply provide a keyword or phrase, along with a brief description. For example, you could upload the "Subway" logo and input the word "burger" and the description "juicy topped with cheese". The model would then generate a unique artwork that depicts a delicious burger with the word "Subway" embedded within the image.
You can also use the model to generate more specific artworks. For example, you could upload an image consisting of your name and input the word "birthday" and the description "colourful balloons". The model would then generate a unique artwork that depicts a birthday party with colourful balloons around your name. How amazing is that?
Segmind offers a set of Advanced settings such as Steps, Guidance Scale, ControlNet conditioning scale. You could leverage these settings to find the perfect balance for your particular use case/expected output. For a deeper understanding of each of the advanced settings you can refer to our article on best settings for SDXL that touches upon each of the topics.
Segmind Word to Image use cases
- Custom Apparel: A company could offer a service where customers input a word or phrase and a brief description, then receive a unique, custom-designed piece of clothing. For instance, a customer could input "love" and "beautiful floral design," resulting in a unique print that could be used on a T-shirt, hoodie, or hat.
- Personalized Home Decor: This could be a great tool for creating custom art pieces for the home. A customer could input their family's last name and a description of their home's color scheme or style, and the AI would generate a piece of art to match.
- Greeting Cards: Customers could create their own custom greeting cards. They could input a word like "Birthday" and a brief description such as "colorful balloons," and the AI would generate a unique card design.
- Event Planning: For events such as weddings or birthdays, the model could be used to create personalized decorations. The names of the couple or the birthday person could be incorporated into beautiful designs fitting the event's theme.
- Book Cover Design: An author could input the title of their book and a brief description of the book's theme to generate a unique cover design.
- Restaurant Menus: A restaurant could use the model to create a unique menu. They could input the name of a dish and a description of its flavors to generate a corresponding visual.
- Advertising: Companies could generate unique, eye-catching visuals for their ad campaigns. They could input their product's name and a brief description of its benefits or features to create an appealing design.
- Website Design: Web developers could use this model to generate unique visuals for a website. They could input the name of the company and a brief description of the company's values or mission to create a corresponding visual.
- Education: Teachers could use this tool to create educational materials. They could input a keyword from the lesson and a brief description of the concept to create a visual aid.
- Tattoo Designs: A tattoo artist could use this model to generate unique designs based on customer's input. For example, a customer might input a word that has significant meaning to them and a description of the style they want.
The future of art
Segmind Stable Diffusion Word to Image is a powerful tool that has the potential to revolutionize the world of art. With this tool, anyone can now create stunning and unique artwork with just a few words.
The possibilities are endless, and the future of art is wide open. With Segmind Stable Diffusion Word to Image, anyone can now bring their ideas to life in a way that was never before possible.