Using Grounding DINO & SAM in Stable Diffusion Inpainting
Learn how Grounding DINO and SAM can transform your image processing tasks. Discover how these tools, combined with Segmind’s Background Removal model for image manipulation, open up a world of creative possibilities for image manipulation, especially in Stable Diffusion Inpainting.


Let’s talk about two incredible tools for image manipulation: Grounding DINO and Segment Anything Model (SAM). Grounding DINO is a state-of-the-art model that excels in zero-shot object detection. It combines the robust DINO architecture with grounded pre-training, allowing it to detect a wide range of objects based on human inputs like category names or referring expressions. SAM is a universal tool for image segmentation. It gives users the power to segment and recognize any element in an image at any level of detail they choose.
Grounding DINO
When you use Grounding DINO, you can give the model specific prompts to detect objects in images, all without the need for retraining. This makes it incredibly flexible and adaptable for a variety of real-world tasks. It’s especially good at open-set object detection, where it uses both language and vision modalities to detect objects based on human inputs.
Segment Anything Model (SAM)
SAM, on the other hand, is all about image segmentation. It lets users segment and recognize any part of an image at the level of detail they want. When you combine Grounding DINO with SAM, you get the best of both worlds. You can use the zero-shot object detection of Grounding DINO and the segmentation capabilities of SAM to precisely segment elements in images based on semantic text prompts.
Segmind Background Removal
Once segmentation of an element from an image is done, Segmind Background Removal V2 model can effortlessly create mask. The mask can then be used to either change the background or the replace the object with a new object.
This combination gives you a comprehensive tool for both object detection and image segmentation tasks, opening up a world of creative possibilities for image manipulation especially in Stable Diffusion Inpainting.
Creating masks for Stable Diffusion Inpainting
Grounding DINO, SAM, and Background Removal V2 can be used in creating masks for stable diffusion inpainting programmatically. Here’s a step-by-step process:
- Object Detection with Grounding DINO: Use Grounding DINO to detect the object of interest in the image. This is done by feeding the image and the object category as inputs to the Grounding DINO model.
- Image Segmentation with SAM: Once the object is detected, use SAM to segment the object from the rest of the image. This involves running the SAM model on the image and using the output of Grounding DINO to guide the segmentation.
- Mask Creation with Background Removal V2: With the object segmented, use Background Removal V2 to create a mask using the output of SAM to define the areas to be preserved (black pixels) and the areas to be filled (white pixels).
- Inpainting with Stable Diffusion: Finally, use Stable Diffusion to fill in the white pixels of the mask, effectively inpainting the desired areas.
Let's take a look at two examples where this workflow can be used.
Example 1: Background Generation
First, we use Grounding DINO to detect the shoes in the image. This model can identify and locate the shoes based on the category name “shoes” or a referring expression related to shoes. Next, we use SAM to segment the detected shoes from the rest of the image. This model can create a precise boundary around the shoes, separating them from the background. We then use Background Removal V2 to create a mask for the image. In this mask, the pixels corresponding to the shoes (the object we want to preserve) are colored black, and the pixels corresponding to the background (the area we want to replace) are colored white. Finally, we use Stable Diffusion to fill in the white pixels of the mask, effectively generating a new background for the image. The black pixels of the mask (the shoes) are preserved during this process, ensuring that only the background is altered.
This process allows us to generate a new background for the image while preserving the shoe.
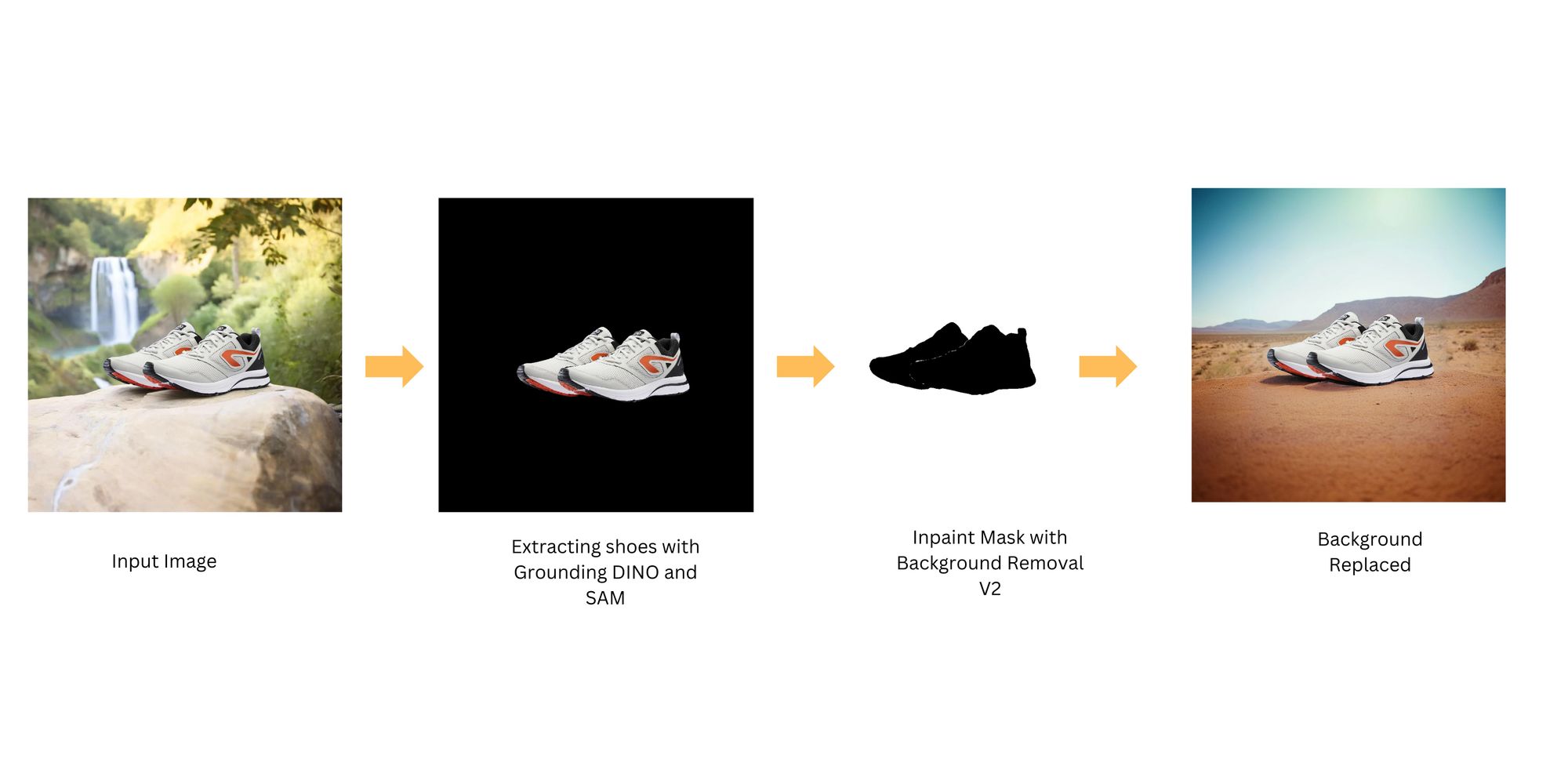
Example 2: Product Placement
First, we use Grounding DINO to detect the dress on the mannequin. This model can identify and locate the dress based on the category name “dress”. Next, we use SAM to segment the detected dress from the rest of the image. This model can create a precise boundary around the dress, separating it from the mannequin and the background. We then use Background Removal V2 to create a mask for the image. In this mask, the pixels corresponding to the dress (the object we want to preserve) are colored black, and the pixels corresponding to the mannequin and the background (the areas we want to replace) are colored white. Finally, we use Stable Diffusion to fill in the white pixels of the mask, effectively generating a new background for the image. The black pixels of the mask (the dress) are preserved during this process, ensuring that only the mannequin and the background are altered. The last step is to overlay the extracted dress onto an image of a model.
This process allows us to place the dress on a model while preserving the original look of the dress.

We have curated many such Stable Diffusion Inpainting workflows like the above two examples using Pixelflow. We encourage you to experiment with them and add your own unique touch. Become a part of the vibrant Pixelflow Community by joining our Discord server. Collaborate, create, and share innovative workflows with fellow Pixelflow community members.