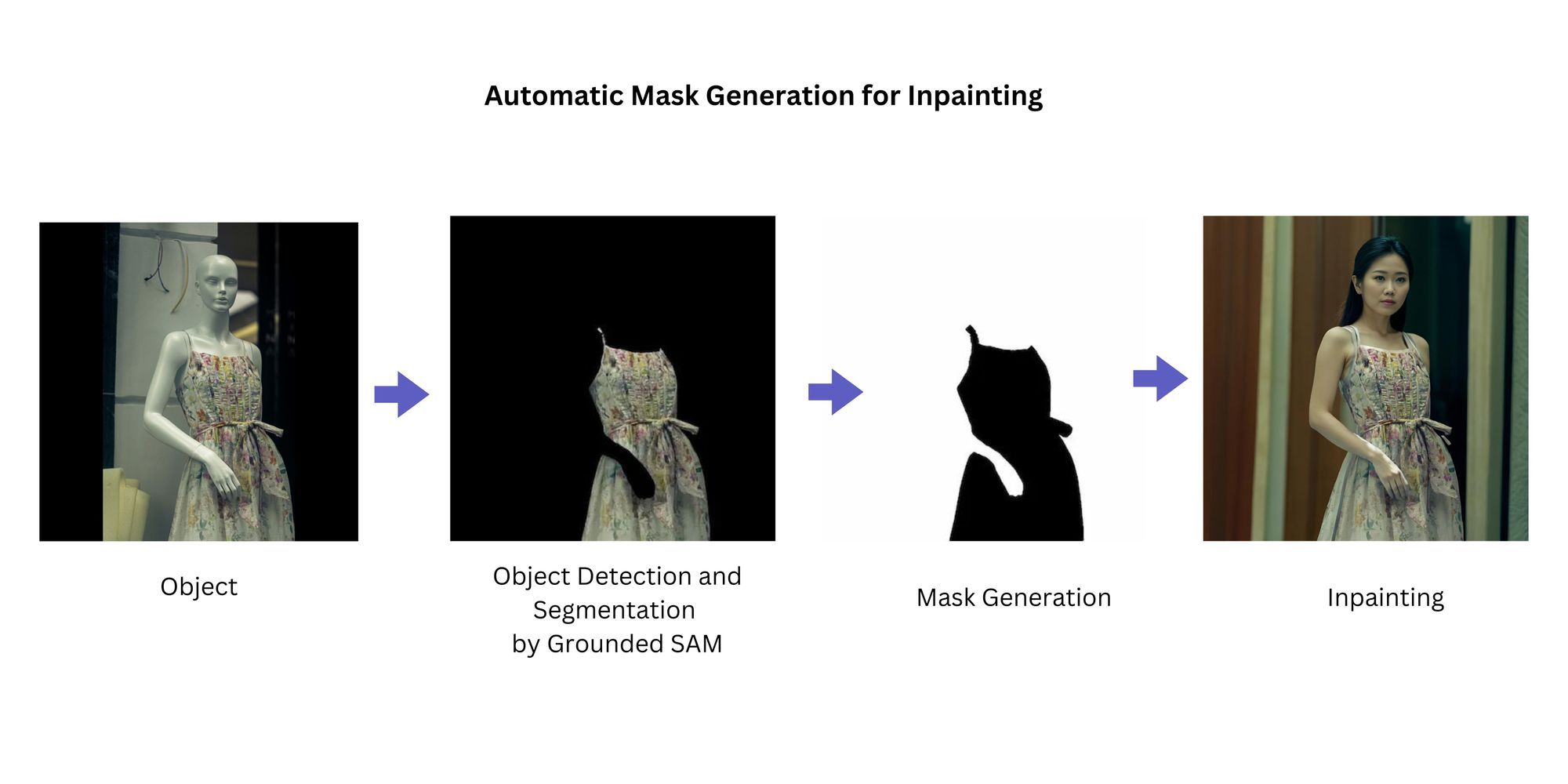
Grounded SAM: Automatic Image Inpainting Mask Creation
Discover how Grounded SAM, simplifies your Inpainting workflow by creating mask automatically with just text prompts. Just describe the object (hair, dress, etc.) and get precise masks for flawless inpainting.


Grounded SAM is a tool that automatically generates precise masks for image inpainting using just text prompts. Grounded SAM combines two different deep learning models: Grounding DINO and Segment Anything Model (SAM).
- Grounding DINO: This model acts as an open-set object detector. It can identify objects in an image even if it hasn't been specifically trained on them before. It uses a technique called "grounded pre-training" to achieve this.
- Segment Anything Model (SAM): This model specializes in image segmentation. Given an image and a text prompt, it can segment (separate) the object described in the prompt from the background. SAM is particularly good at handling situations where there's limited labeled data for specific objects.
* Get $0.50 daily free credits on Segmind.
How Grounded SAM works?
- Grounding DINO scans the image: It first analyzes the image and tries to identify potential objects based on its pre-trained knowledge.
- Provides context and location: Grounding DINO then provides SAM with information about these potential objects, including their locations in the image.
- SAM refines the segmentation: Using the text prompt and the information from Grounding DINO, SAM segments the desired object in the image, helping in creating a precise mask for the object.
Benefits of Grounded SAM
- Automatic Mask Generation: Unlike manual methods, Grounded SAM leverages its object detection and segmentation capabilities to automatically generate a mask for your chosen area. This saves time and effort compared to painstakingly drawing masks yourself.
- Open-Ended Object Handling: Grounded SAM excels at identifying a wide range of objects, even those it hasn't been specifically trained on. This makes it perfect for inpainting tasks involving diverse objects.
Using Grounded SAM for Creating Mask in Inpainting Automatically
Grounded SAM utilizes Grounding DINO to understand your text prompt. This allows you to specify what object you want to manipulate in the image. Based on the identified object from your text prompt, Grounded SAM employs SAM (Segment Anything Model) to create a segmentation mask. This mask precisely defines the region of the image containing the target object. The generated mask from Grounded SAM is then fed into any Stable Diffusion inpainting models. These models use the mask to isolate the target area and fills it in based on the surrounding image content and your additional prompts (if any).
Here are a few examples of using Automatic Mask generator in Inpainting process.
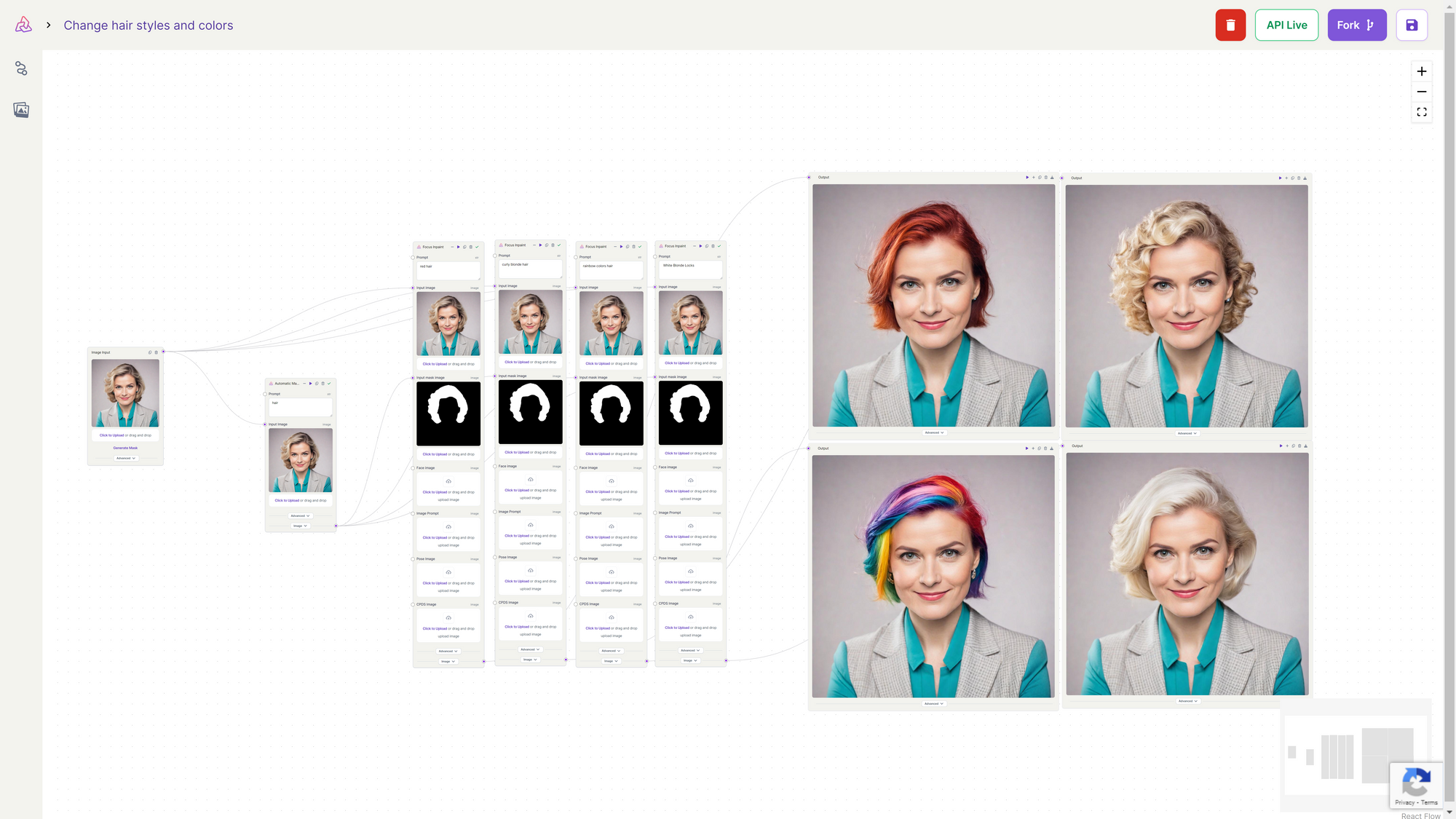
- Change Hair Color
If you want to modify hair (as demonstrated in the workflow below), explicitly designate the hair as the text prompt in the automatic mask generator. This step ensures an accurate mask is generated specifically for the hair. With the mask in place, you can proceed with inpainting models like Fooocus Inpainting. During inpainting, specify the desired hair color or style as part of the inpainting process. The black pixels (human) is preserved, while the white pixels is inpainted (the hair).
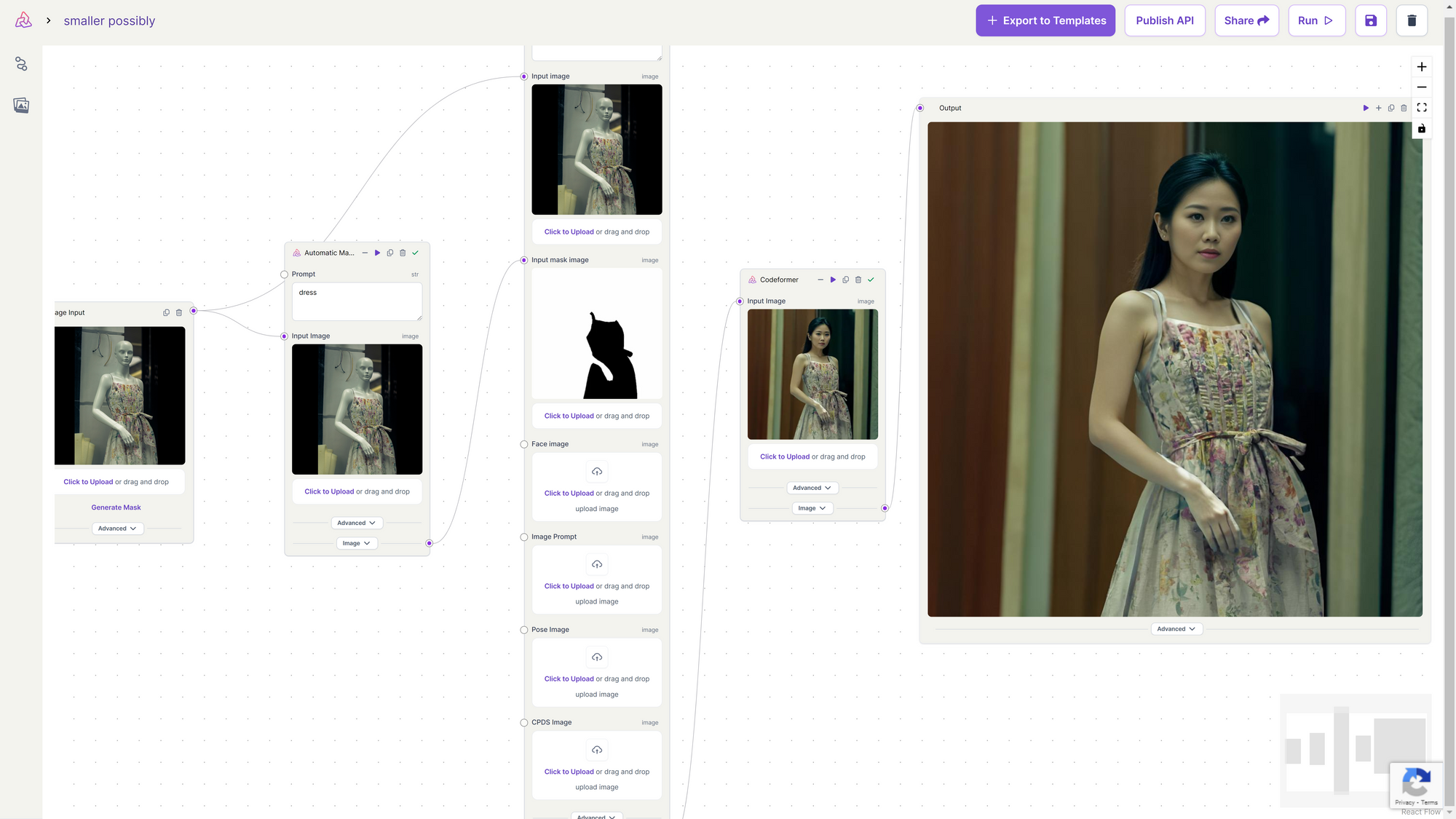
2. Model to Mannequin
If you want to transform a mannequin wearing clothing into an actual human model wearing the same outfit, explicitly designate the dress as the text prompt in the automatic mask generator. This step ensures an accurate mask is generated specifically for the dress. With the mask in place, you can proceed with inpainting models like Fooocus Inpainting. During inpainting, specify the desired hair color or style as part of the inpainting process. The black pixels (the dress) is preserved, while the white pixels is inpainted.