SSD-1B vs. SDXL 1.0: A Detailed Side-by-Side Comparison
This blog post covers a detailed side-by-side comparison of the SSD-1B and SDXL 1.0, aiming to dissect their capabilities and performance.


Ever since image generation models were announced, the world of digital creativity has witnessed a remarkable transformation. These models have the incredible ability to bring ideas to life through visually stunning images. Today, our focus is on exploring and comparing two such marvels in the text-to-image generation domain namely SDXL 1.0 and SSD-1B.
Why this comparison, you ask? Well, as the possibilities of these models continue to expand, understanding the advantages as well as the capabilities of each of these models helps us make informed decisions about which model aligns better with our specific creative needs. In this post, we're set to compare two such models, ensuring a fair evaluation by defining specific criteria for our comparison. Before delving into the details, let's explore the architecture of each model. It's worth noting that we are committed to fairness in our assessment and we've set the best settings for the respective models to guarantee an equitable comparison.
Architecture
SDXL 1.0 :
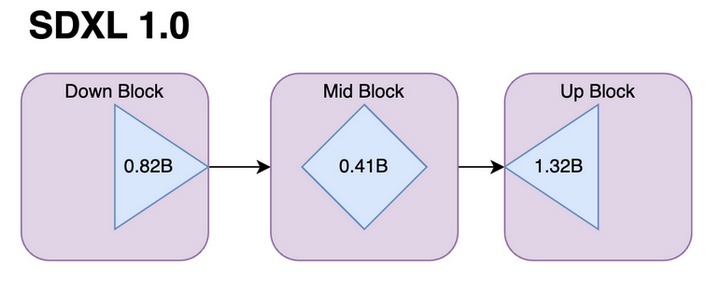
The SDXL Model, presented by Stability Diffusion has approximately 2.6 billion parameters, achieved by incorporating a greater number of U-Net parameters. A notable departure from its predecessor, Stable Diffusion, lies in the heterogeneous distribution of transformer blocks, a shift from the earlier uniform distribution.
Several novel changes characterize the SDXL model. One key enhancement involves a more substantial text conditioning encoder and the integration of OpenClip, effectively incorporating textual information into the image generation process. Another noteworthy addition is the introduction of "Size conditioning," where the original training image's width and height serve as conditional inputs.
Crucially, SDXL introduces a second Stable diffusion model specially designed to handle high-quality and high-resolution data. These advancements collectively position the SDXL model as a robust and versatile tool in the realm of image generation.
SSD-1B:
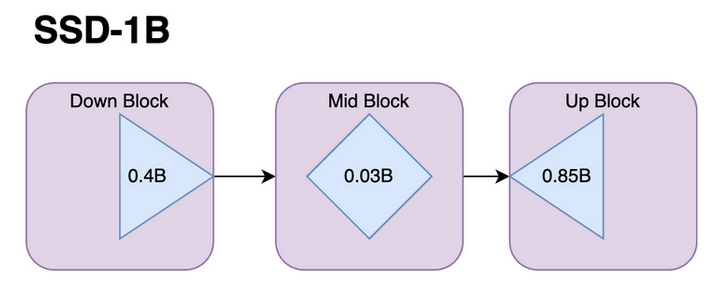
The SSD-1B model is configured with 1.3 billion parameters, a strategic reduction from the base SDXL model. To achieve a more streamlined size, the architecture was made by removing specific layers while meticulously preserving image quality. Notably, the removal of transformer blocks within the Attention Layers proved to have no significant impact on quality.
Additionally, the Attention and a Resnet layer from the mid-block has been omitted, as research indicated their limited impact on overall quality. The Unet block underwent a progressive distillation process, gradually shortening it in each stage and subsequently training the model. In total, 40 transformer blocks and 1 Resnet block were successfully removed, contributing to the model's more compact architecture.
These modifications collectively result in a 50% reduction in the model's size, coupled with a remarkable 60% increase in speed for both inference and fine-tuning processes.
Inference Speed:
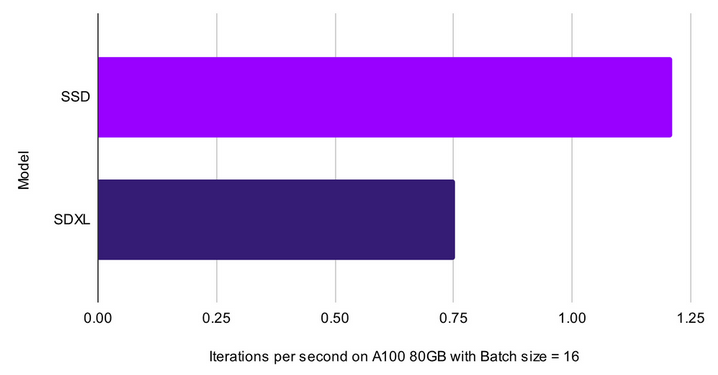
The SSD-1B model brings an impressive 60% boost in both inference and fine-tuning speeds compared to the SDXL Model. Even at a single-unit batch size, the SSD-1B stands out with an impressive 16.02 images per second (It/s), showcasing a remarkable 56% speed increase over the SDXL's 10.26 It/s. This trend of improved performance persists as we scale up batch sizes.
At four units, the SSD maintains a speed of 4.78 It/s, surpassing the SDXL's 3.03 It/s. The SSD continues to lead as batch sizes increase to eight and sixteen, achieving 2.44 and 1.21 It/s, respectively. This not only demonstrates resilience to higher workloads but also showcases a consistent performance threshold. In contrast, the SDXL's throughput decreases to 1.54 and 0.7519 It/s under the same conditions.
The parameters for both text-to-image models are identical. Therefore, we will begin by understanding these parameters and subsequently get to know about the optimal values for each model while comparing them.
Guidance Scale:
The guidance scale is crucial in making sure our generated images match the given text prompts. If we increase the value of this parameter, then the image gets super connected to the text, but it might lose some diversity and overall quality in the process.
Steps:
This parameter is about how many times the model cleans up noise to make better images. Imagine starting with a bit of random noise from the text, and the model goes through a cycle where it keeps refining the image by removing some of that noise
The higher the value of steps, the more high-quality images are produced.
Schedulers:
In the context of the Stable Diffusion pipeline, schedulers are algorithms that work alongside the UNet component. The main job of these schedulers is crucial to the denoising process, which happens step by step. These steps are super important for turning a random noisy image into a high-quality image.
The schedulers' job is to systematically get rid of noise from the image, creating new data samples along the way.
Negative Prompts:
Negative prompts allow users to define the kind of image they would not like to see while the image is generated without providing any input. These prompts serve as a guide to the image generation process, instructing it to exclude certain elements based on the user-provided text.
By utilizing negative prompts, users can effectively prevent the generation of specific objects, and styles, address image abnormalities, and enhance overall image quality.
When comparing both of these models, we will ensure to use the following negative prompts to make this comparison fairer.
worst quality, normal quality, low quality, low res, blurry, text, watermark, logo, banner, extra digits, cropped, jpeg artifacts, signature, username, error, sketch, duplicate, ugly, monochrome, horror, geometry, mutation, disgusting , NSFW, nude, censored.
Apart from the examples where we would like to try out various prompts to assess their capabilities, we'll also employ specific negative prompts to gauge how well each model handles avoiding undesired elements and adheres to user preferences.
Image comparisons between both models:
We will now take a look into how both these models stack up based on a few key factors, we would like to compare them based on
- Prompt adherence: How well the models stick to the given instructions.
- Art styles: The variety and quality of artistic styles the models can produce.
- Functionality: The overall performance and capabilities of the models.
By looking at these aspects, we can get a clearer picture of what each model brings to the table. As a side note, all parameter values in the respective models are fixed according to our findings, which can be reviewed in detail best-settings for SDXL and best-settings for SSD. It’s time to experiment and see what unfolds!
Prompt Adherence:
Prompt adherence refers to how well a model follows the provided textual instructions to create an image. However, it's important to note that there isn't a specific framework or evaluation metric to precisely measure the quality of prompt adherence in text-to-image generation models. Well-designed prompts serve as a kind of roadmap, steering the model toward generating images that align with the intended vision. While there's no one-size-fits-all method to assess prompt quality, a creative and clear prompt often contributes to more accurate and visually appealing results.
Let's start with simple prompts and then move on to extremely detailed prompts that specify individual nuances in the images.
Prompt : Woman

Prompt : A child walking down the road

So far, we've observed some straightforward prompts in action, noting that the SSD model tends to provide more close-up shots compared to the SDXL Model. Now, let's explore a set of more intricate prompts to see how both models handle complexity.
Prompt : Poker chipmunk cowboy drinks beer at speckled pink cyber pyramid, cinema lighting

Prompt : A cute grey cat in a boat floating in a starry night sky

The SDXL Model produces images with a refined and polished appearance, showcasing a high level of sophistication. On the flip side, images produced by the SSD model frequently showcase a vivid and radiant quality.
Prompt : Cute lofi girl in front of his computer in her cozy and messy room, unreal engine 5 render, gorgeous lighting, pastel pink hues, 8k render, realistic scenic render.

Prompt : an intimidating woman, on a rooftop, leather jacket, tattoos, red hair, New York, natural lighting, Nikon D100, RAW photo, film grain, post-processing

Prompt: Display a mesmerizing cocktail presentation with vibrant colors, meticulously crafted garnishes, and an ambiance that exudes sophistication. The image needs to be visually stunning

However, when the prompts presented to the models are more detailed we do find the SDXL model struggling a bit to adhere to the prompt.
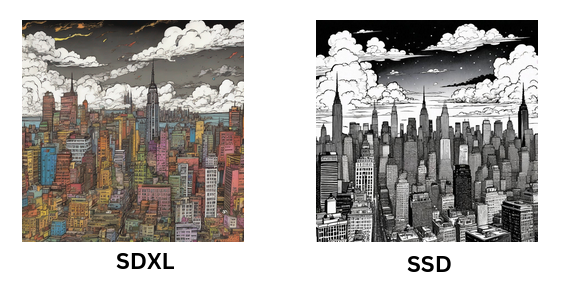
Prompt : Chaotic stunning New York City, skyline, style of tin tin comics, pen and ink. vintage 90's anime style, black and white, colorful clouds
Prompt : a girl playing chess against a hooded skeleton on the moon, black hole in the background, Street Art

Both models excel at crafting visually striking images based on the given prompts. However, it's worth noting that the SDXL model occasionally struggles to fully adhere to the provided prompts. On the other hand, the images generated by the SSD model not only demonstrate a vibrant quality but are also rich in texture that adds depth and detail to each visual creation.
Art Styles:
Text-to-image generation models can simulate various artistic styles, be it capturing the essence of classic paintings, modern illustrations, or even futuristic designs. Checking out the different art styles these models can handle helps us grasp the full extent of their artistic skills. We'll continue exploring this aspect by giving the models various prompts to test their abilities, just like we did with the previous criteria.
Prompt : blog profile image, man, glass, 30s, writing journal, asian, painting, watercolor, left-handed

Prompt : 8k wallpaper of a beautiful anime adventurer girl wearing gold jewelry in the streets of a city in Western Sahara, intricate detail, 8k, fluid motion, stunning shading

Prompt : A close up of a cyclops wearing an epic art, in style of art, highly detailed art, ornate dramatic devil wing amulet, detailed digital 2d art, intricate armor, symmetric concept art, face of an black-armored villain, cyberpunk, on a deep red and black mechanic temple

Prompt : A portrait of a samurai , 4K resolution, anime line art, in the style of Leiji Matsumoto, with clear lines, no shadows, on a pure WHITE background suitable for a adult's coloring book.

Prompt : Nike sneaker concept, made out of cotton candy clouds , luxury, futurist, stunning unreal engine render, product photography, 8k, hyper-realistic. surrealism

Comparing the images generated by both models, the artistic quality of both images is high. However, the images from SDXL, while maintaining high artistry, exhibit a notable absence of texture and subtle nuances compared to those produced by SSD-1B. The depth in the images appears to be more pronounced in SSD-1B.
Furthermore, the detailing in aspects like hair, the texture of the skin, and objects appears to be more intricate and pronounced in SSD-1B, setting it apart while SDXL struggles to produce photorealistic images with a deep depth of field.
Functionality:
This is about how well the model performs in turning text into images, considering the types of instructions it can handle and its creative abilities. Checking the functionality helps us understand what the model does well and where it might have some limitations.
Now, we'll give specific instructions to the model, like increasing parameter values and adding more negative prompts.
For example, let's say we want a close-up picture of a girl without any blur in the background. We'll add "blur" and "bokeh" to the negative prompts to avoid these effects.
Prompt : A beautiful blonde 25-year-old with a cruel indifferent expression and looking down on her face, close up

Here's the interesting part: when we compare the images generated by the two models, even though we clearly stated our intention, SDXL adds a blurry effect to the image, while SSD sticks to our instructions.
Next, we try something different, like a sun's profile in a halftone pattern in the form of an absurdist painting. We increase the guidance scale value for both models to 15.
Prompt : Sun profile, Halftone pattern , highly textured, genre-defining , fringe absurdism ,Award winning halftone pattern illustration , simple flowing shapes , subtle shadows, paper texture , minimalist color scheme

The result: SDXL gives us a better image following our prompts, resembling an absurdist painting. SSD, on the other hand, tends to create images that look more like digital art, especially when we want a painting-like texture.
Moving on, let's try generating an image with a shadow figure emerging from the darkness.
Prompt : shadow figure man emerging from the darkness, black and grey gradient, foggy, realistic, 8k, unreal engine, cinematic

It's interesting to see that when our prompt is vague, both models tend to create similar-looking characters.
Let us try to test the ability of photorealism of both models.
Prompt : beautiful girl standing with beautiful vally in background, age 20, black short hair, waist shot, dynamic pose, smiling, dressed in fashion outfit, beautiful eyes, sweet makeup, 35mm lens, beautiful lighting, photorealistic, soft focus, kodak portra 800, 8k

Prompt : A realistic photo of a 25 years old woman crying, with brown shiny eyes, dark hair in a ponytail, a deeply depressed expression, rounded cheeks with some freckles, fit strong body, dark illumination, hyperrealistic, hyperdetailed, 8k

SDXL lacks in this department. While it produces high-quality images, finer details like hair or facial features aren't up to the mark when compared with SSD.
Finally, we explore abstract images and scenes with backgrounds and objects, focusing on the overall composition ability of the model.
Prompt : 3d cubist-inspired painting of jazz musicians' instruments set against a black backdrop. fusion of traditional acrylic paint with digital techniques to achieve meticulous attention to detail. incorporate Salvador Dali's style

SSD often displays a bright and digital art-like quality, while SDXL produces a more toned-down and saturated version.
Prompt : a topdown fantasy map from 90 degrees angle of a market, dnd encounter, in the style of sound art, epic fantasy, Rembrandt lighting, dungeon village fantasy, extremely detailed, photorealistic, octane render, 8 k, unreal engine 5.

Prompt: An abstract pattern for a book cover with pastel tones, think Eastern Europe abandoned city

Prompt : a sketch in greyscale of a scene from above depicting a fractured and earthquake devastated city, pencil effect. realistic. high details. harsh lighting.

However, there are instances where both models struggle and don't depict the desired prompt well
Prompt : a photo of a cat drawing a flower

Prompt : bird flying over two vehicles along the road, cinematic

Overall, we find that SDXL lacks composition and struggles with text-to-image alignment compared to the SSD model, especially for images requiring high symmetry and composition.
Conclusion
In conclusion, text-to-image generation models showcase remarkable advancements in transforming textual prompts into visual compositions. Each model brings its unique strengths and nuances to the creative process. Despite their proficiency, certain challenges emerge, such as issues with photorealism, composition, and alignment with the provided text. As this technology develops, we expect better models and training methods. Exploring text-to-image models is exciting and opens up new ways to express creativity by blending words and visuals.
The essence of this comparison isn't just about declaring one model as the best; rather, it's an exploration of how each model evolves and improves. We find SSD to have better text-to-image alignment compared to SDXL and also improved efficiency in generating images.