SSD-1B : Best settings for crafting compelling images
A comprehensive guide to maximizing the potential of the SSD-1B model for image generation.


Nearly a month back we announced SSD-1B a cutting-edge diffusion-based text-to-image model that stands out as the fastest in the market. It achieves unparalleled image generation times, particularly notable for producing high-quality 1024x1024 images swiftly. As a key component of our distillation series, SSD-1B offers a remarkable 50% reduction in size and a 60% increase in speed compared to the SDXL 1.0 model. Despite this significant boost in efficiency, SSD-1B maintains a minimal impact on image quality when compared to its predecessor SDXL 1.0.
This article delves into a comprehensive exploration of the optimal settings to extract the maximum impact from SSD-1B. Before delving into these settings, let's take a closer look at the architecture of the model.
The Architecture of SSD-1B
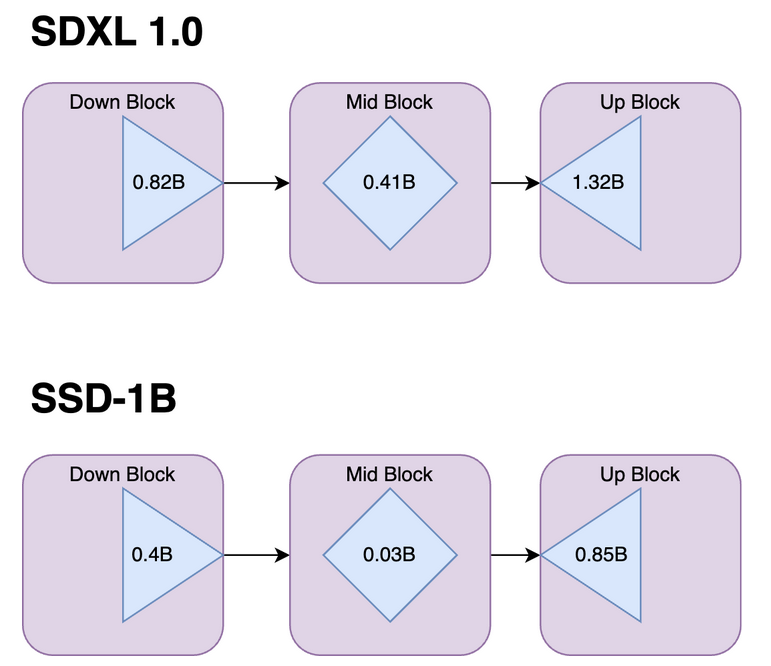
The SSD-1B model is configured with 1.3 billion parameters, a strategic reduction from the base SDXL model. To achieve a more streamlined size, we focused on removing specific layers while meticulously preserving image quality. Notably, the removal of transformer blocks within the Attention Layers proved to have no significant impact on quality.
Additionally, we omitted the Attention and a Resnet layer from the mid-block, as research indicated their limited impact on overall quality. The Unet block underwent a progressive distillation process, gradually shortening it in each stage and subsequently training the model. In total, 40 transformer blocks and 1 Resnet block were successfully removed, contributing to the model's more compact architecture.
These modifications collectively result in a 50% reduction in the model's size, coupled with a remarkable 60% increase in speed for both inference and fine-tuning processes.
Choosing the best set of values for parameters
Guidance Scale
The guidance scale parameter plays a pivotal role in influencing the adherence of the image generation process to the provided text prompts. It acts as a fundamental and essential element in ensuring that the generated images closely align with the intended meaning and context conveyed by the input text prompts. A higher value intensifies the connection between the generated image and the input text, but it comes at the expense of diversity and overall image quality


Observing the behavior of prompts at different extremes reveals distinct characteristics. When the guidance scale is set to values near 1, there may be a slight compromise in artistic quality.

On the other hand, values above 19 or 20 enforce strict adherence to the text but may also impact the artistic quality of the generated image. In the optimal range of 12 to 17, the emphasis shifts to highlighting details in the image. For those seeking to generate images rich in tiny details as specified in the prompt, it is advisable to choose values within this specific range.
Steps
This refers to the number of denoising steps. In this process, initiated by a random noise generated from text input, the model undergoes a repeated cycle. As the cycle progresses, each step involves the removal of some noise, resulting in a gradual improvement in image quality.
The higher the value of steps, the more high-quality images are produced.

The generation of high-quality images is notably observed between steps 15 and 25. Beyond this range, subsequent steps do not yield a significant difference in the overall quality of the generated images. However, the form of the image undergoes repeated changes without introducing additional details
It's worth noting that minor details, such as the quality of feathers or the texture of leaves in the background, see incremental improvements with each step in this phase.
Negative prompts
Negative prompts allow users to define the kind of image they would not like to see while the image is generated without providing any input. These prompts serve as a guide to the image generation process, instructing it to exclude certain elements based on the user-provided text.
By utilizing negative prompts, users can effectively prevent the generation of specific objects, and styles, address image abnormalities, and enhance overall image quality.
Examples of commonly used negative prompts :
- Basic negative prompts: worst quality, normal quality, low quality, low res, blurry, text, watermark, logo, banner, extra digits, cropped, jpeg artifacts, signature, username, error, sketch, duplicate, ugly, monochrome, horror, geometry, mutation, disgusting.
- For Adult content: NSFW, nude, censored
- For realistic characters: extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck


Scheduler
In the context of the Stable Diffusion pipeline, schedulers are algorithms that are used alongside the UNet component. The primary function of these schedulers is integral to the denoising process, which is executed iteratively in multiple steps. These steps are essential for transforming a completely random noisy image into a clean, high-quality image.
The role of schedulers is to systematically remove noise from the image, generating new data samples in the process. Among the various schedulers, UniPC, Euler, and DDPM are highly recommended.
Summary
In conclusion, SSD-1B can be used to generate eye-catching and stylish images. The key strengths of SSD-1B lie in its ability to strike a balance between efficiency and visual quality. Its faster processing capabilities make it a practical solution for applications where timely image generation is crucial. This positions it as a frontrunner in the realm of diffusion models, showcasing exceptional speed and compactness when compared to its contemporaries.