VoltaML, Reduce The Cost of Inference and Speed Up Your Machine Learning Models Up To 10x
Reduce The Cost of Inference and Speed Up Your Machine Learning Models Up To 10x

Reduce inference cost up to 10x and accelerate your machine learning models up to 10x
It's time to accelerate your machine learning models up to 10x using our low-code library 🚀

VoltaML is your one-stop library for all things machine learning inference acceleration.
Do you know that 90% of AI costs are only related to inference? Meta does 200 Trillion inferences per day. ML compilers help optimize and accelerate inferences of different AI models. But, using ML compilers is HARD!
To address this issue, we have developed an inference acceleration library that allows you to accelerate your models by 10x, using just a couple of lines of code and never worrying about inference costs again.
Why should you care about inference acceleration?
As data scientists and ML engineers, we focus majorly on building our AI models and getting to the best accuracies. But what about optimizing to get the best performance for the models in production?
The need for data scientists and ML engineers with knowledge of inference optimization will grow exponentially in the coming years. Start your inference optimization journey with voltaML.
From ML algorithms like XGBoost or LightGBM to deep learning models in computer vision and NLP, voltaML offers acceleration for a diverse set of AI models.
How do we do it?

Let numbers speak for themselves 🗣
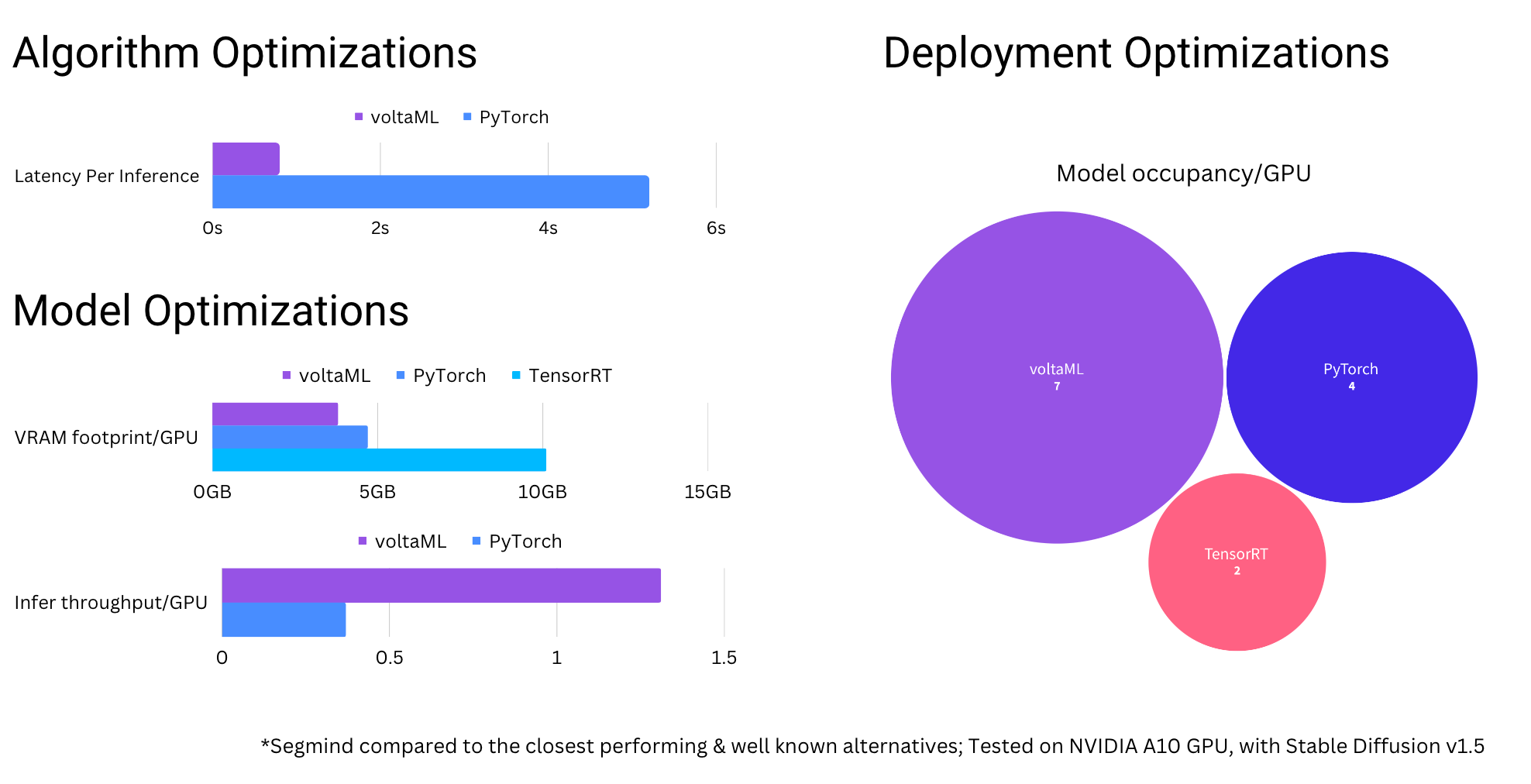

🚀🚀 Check out our Github library, try us and give us a 🌟
As always we will be picking a few users that have starred us to send some voltaML goodies 🎁