Top 7 Image-To-Video AI Models (Reviewed And Compared)
Want to make videos from images? Check out these 7 best image-to-video AI models. Compare pros, cons, key features, and more to find out the best model for your needs.


Turning still images into high-quality videos has never been easier. With the rise of AI-powered tools, anyone can now create dynamic video content from static pictures. In this guide, we'll explore the top image-to-video AI models, along with their pros, cons, and key features.
These tools open up exciting possibilities for content creators, marketers, and anyone looking to bring their images to life. Let's explore how these innovative tools can transform your creative process.
Comparing The Top Image-To-Video Generative AI Models
Top 7 Free Image-To-Video AI Models
1. CogVideoX - Best For High-Resolution Video Creation
CogVideoX is a powerful AI tool that turns static images into dynamic, high-quality videos. It's designed with content creators, marketers, and developers in mind, offering a range of features to enhance video production.
This model stands out for its ability to generate videos at resolutions up to 720 x 480 pixels. This makes it suitable for professional use in marketing, social media, and educational content. CogVideoX supports various precision levels (FP16, BF16, and INT8), allowing users to balance performance and quality based on their needs.
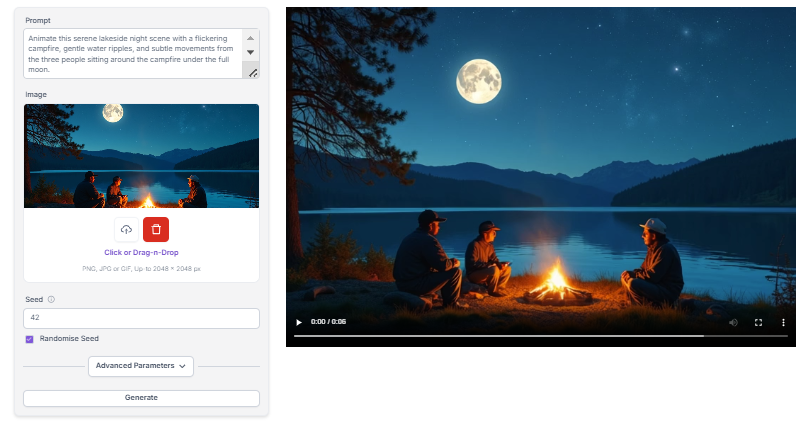
One of CogVideoX's key strengths is its VEnhancer technology. This feature boosts video resolution and improves visual effects, resulting in more polished and engaging final products.
Key Features:
- High-Resolution Output: Creates videos suitable for professional use.
- Versatile Precision Options: Allows users to optimize for performance or quality.
- VEnhancer Technology: Improves video quality and visual appeal.
- Multi-Purpose Use: Ideal for content creation, animation, and educational videos.
CogVideoX shines when compared to other models due to its focus on high-resolution output and precision control. While tools like Stable Video Diffusion might offer smoother transitions, CogVideoX's emphasis on visual quality makes it a strong choice for those prioritizing image clarity and detail.
To use CogVideoX, start by uploading your source image. Then, select your desired output resolution and precision level. You can also adjust settings related to the VEnhancer technology to fine-tune your results. The interface is straightforward, but new users might need some time to understand all the available options.
Best For: CogVideoX is best for content creators and marketers who need high-quality video output. It's particularly useful for:
- Producing engaging social media content
- Creating promotional videos for marketing campaigns
- Developing animated sequences for film and animation projects
- Generating instructional videos from static diagrams or images
2. Stable Video Diffusion - Best For Smooth Video Transitions
Stable Video Diffusion (SVD) is an advanced AI model that uses latent diffusion to generate high-quality videos. This innovative approach allows for smooth transitions and realistic motion, making it a powerful tool for video creation.
SVD works by mapping video frames into a latent space. This allows the model to analyze and manipulate complex patterns with precision. The result is videos with natural-looking movement and seamless transitions between frames.
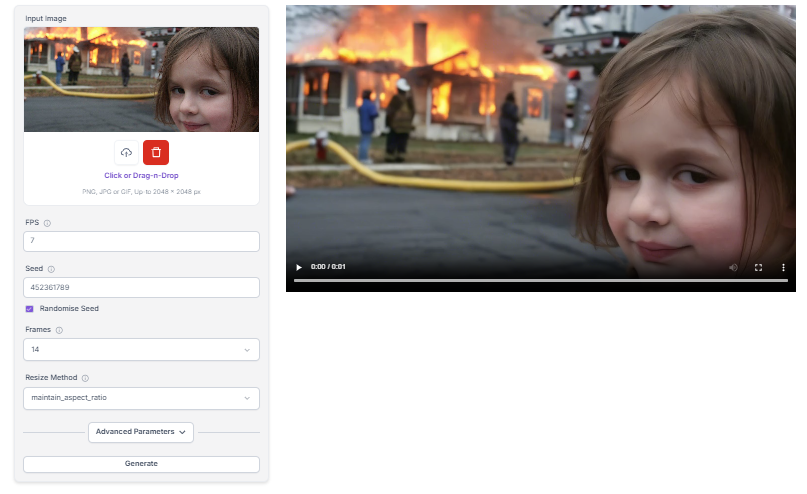
One of SVD's strengths is its efficiency. By optimizing the diffusion process, it reduces the computational load required to generate videos. This makes it more accessible to creators who might not have access to high-end hardware.
Key Features:
- Latent Diffusion Process: Enables precise pattern analysis for smooth video creation.
- Deep Neural Network: Trained on vast datasets to replicate realistic video dynamics.
- Versatile Capabilities: Handles video upscaling, frame rate conversion, and new content generation.
- Efficient Resource Use: Optimized process makes it accessible with less powerful hardware.
Compared to other models, SVD excels in creating smooth, natural-looking motion. While tools like CogVideoX might offer higher resolution output, SVD focuses on the quality of movement and transitions. This makes it particularly useful for projects where fluid motion is crucial.
To use SVD, you'll typically start by inputting your source image and any text prompts to guide the video generation. The model then processes this information through its latent diffusion system to create the final video. While the interface is usually straightforward, understanding how to craft effective prompts can take some practice.
Best For: Stable Video Diffusion is ideal for creators who prioritize smooth, natural-looking motion in their videos. It's particularly well-suited for:
- Creating animated scenes from static images
- Generating realistic motion in character or object animations
- Upscaling and improving the frame rate of existing videos
- Producing videos based on text descriptions, useful for visualizing concepts or stories
3. Easy Animate - Best For Quick Animation Projects
Easy Animate is an advanced animation AI model that turns static images into dynamic animations. It uses deep learning and convolutional neural networks (CNN) to create smooth, realistic movements.
This tool is built on a transformer-based architecture, utilizing motion modules, u-vit (a Vision Transformer variant), and slice-vae for processing longer videos. This complex system allows Easy Animate to handle a wide range of animation tasks effectively.
One of Easy Animate's strengths is its flexibility in input options. You can provide both a detailed text prompt and a reference image to guide the video generation process. This dual-input approach allows for more precise control over the final output.
Key Features:
- High Frame Rate Support: Generates videos at up to 27 frames per second for smooth animations.
- CFG Scale Control: Allows users to adjust how closely the generation follows the input prompt.
- Scheduler Options: Offers various schedulers like "Euler" to influence the visual style.
- Customization Options: Supports seed values for consistent results and negative prompts to specify unwanted elements.
Compared to other models, Easy Animate stands out for its user-friendly approach to animation. While tools like Stable Video Diffusion might offer more advanced motion control, Easy Animate provides a more accessible entry point for quick animation projects.
To use Easy Animate, start by uploading your reference image and entering a text prompt describing the desired animation. You can then adjust settings like frame rate, CFG scale, and scheduler type to fine-tune your results. The interface is designed to be intuitive, making it easier for beginners to create impressive animations.
Best For: Easy Animate is ideal for users who need to create quick, high-quality animations without extensive technical knowledge. It's particularly useful for:
- Social media content creators looking to add movement to static images
- Marketers creating engaging animated ads
- Educators developing animated explanations of concepts
- Artists experimenting with AI-assisted animation techniques
4. Runway - Best For Professional-Grade Video Production
Runway Gen-3 AlphaTurbo is an advanced AI model designed for converting static images into dynamic, high-quality videos. It's part of the Gen-3 Alpha series, known for its high fidelity, smooth motion, and cost-efficient processing.
This tool stands out for its ability to produce professional-grade videos with superior image quality and smooth transitions. The Turbo variant is optimized for faster processing, making it a powerful option for creators who need quick turnaround times without sacrificing quality.
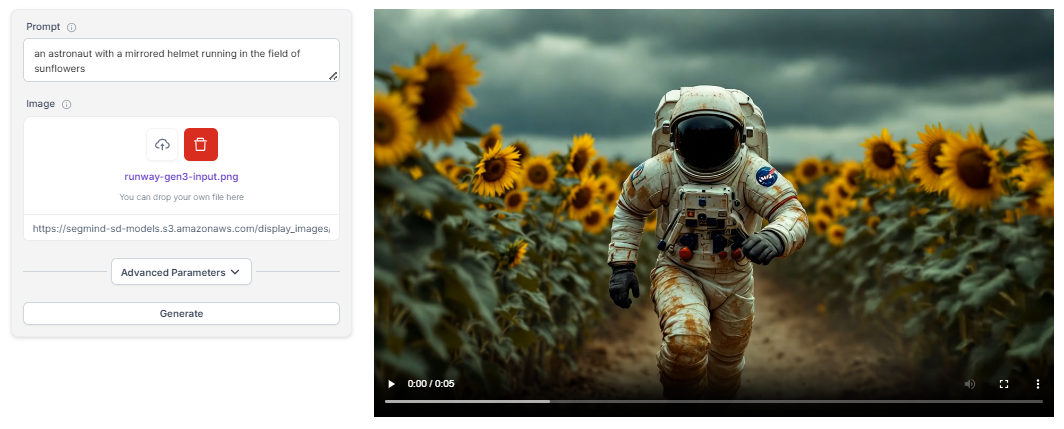
Runway offers versatile input options, supporting both text and image prompts for precise video generation. This flexibility allows users to create highly customized outputs tailored to their specific needs.
Key Features:
- Extended Video Duration: Can generate videos up to 10 seconds long, extendable in 8-second increments.
- High-Resolution Output: Supports resolutions up to 1280x768 or 768x1280.
- Prompt-Driven Creation: Uses detailed text prompts to control scene details, camera angles, and movements.
- Iterative Refinement: Allows for prompt adjustment to improve video output quality.
Compared to other models, Runway Gen-3 AlphaTurbo excels in producing cinema-quality videos with a high degree of control. While tools like Easy Animate might be more user-friendly for quick projects, Runway offers the depth and flexibility needed for professional-grade video production.
To use Runway, start by uploading a high-quality image as your initial frame. Then, provide a detailed text prompt describing the desired scene, including specifics about lighting, camera movements, and subject actions. Generate the video and adjust output settings as needed. The key to success with Runway is in crafting detailed, precise prompts and being willing to refine them through multiple iterations.
Best For: Runway Gen-3 AlphaTurbo is best suited for professional content creators and filmmakers who need high-quality, customizable video outputs. It's particularly useful for:
- Creating cinematic short films or teasers
- Producing high-end marketing and advertising content
- Developing visually stunning music videos
- Generating complex visual effects for film and TV production
5. Luma Dream Machine - Best For Cinematic Video Creation
Luma Dream Machine is an advanced AI tool that converts static images into high-fidelity, 1080p cinema-grade videos. It's designed for professional content creation across various industries, offering a powerful solution for turning still images into dynamic, engaging videos.
This tool uses sophisticated image analysis and transformation algorithms to generate realistic visuals with accurate motion, object interactions, and environmental consistency. Its rapid processing capability, generating 120 frames in just 120 seconds, makes it a time-efficient option for content creators working under tight deadlines.
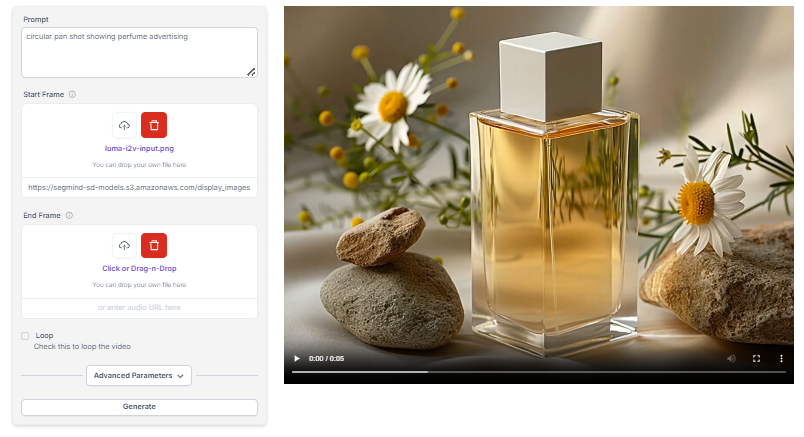
Luma Dream Machine is built on a transformer-based architecture trained on extensive video datasets. This foundation allows it to produce cinematic quality videos with fluid camera motions, enhancing storytelling capabilities.
Key Features:
- High-Fidelity Video Generation: Creates realistic visuals with accurate motion and object interactions.
- Fluid Camera Motion: Offers versatile camera movements like panning, orbiting, and crane shots.
- Aspect Ratio Flexibility: Supports various aspect ratios for different platforms.
- Part of Universal Imagination Engine: Integrates with Luma's larger initiative for diverse content generation.
Compared to other models, Luma Dream Machine stands out for its focus on cinematic quality and professional-grade output. While tools like Runway offer similar high-quality results, Luma's emphasis on camera movements and cinematic techniques makes it particularly suited for filmmakers and professional video producers.
To use Luma Dream Machine, start by uploading your source image. Then, provide detailed instructions for the desired video, including specific camera movements and scene details. The tool's interface allows for fine-tuning of various parameters to achieve the desired cinematic effect.
Best For: Luma Dream Machine is ideal for professional content creators and filmmakers looking to produce high-quality, cinematic videos. It's particularly useful for:
- Creating engaging promotional videos for marketing campaigns
- Developing visually striking educational content
- Producing high-end social media content for platforms like Instagram and YouTube
- Generating cinematic sequences for film and TV production
6. Kling AI - Best For Efficient Video Generation
Kling AI, developed by the Kuaishou AI Team, is an innovative tool that transforms static images into high-quality videos. It uses advanced 3D space-time attention and diffusion transformer technologies to generate videos efficiently.
This model stands out for its dynamic-resolution training, which allows it to support various aspect ratios. This flexibility makes Kling AI suitable for creating content across different platforms and formats, from social media posts to widescreen presentations.
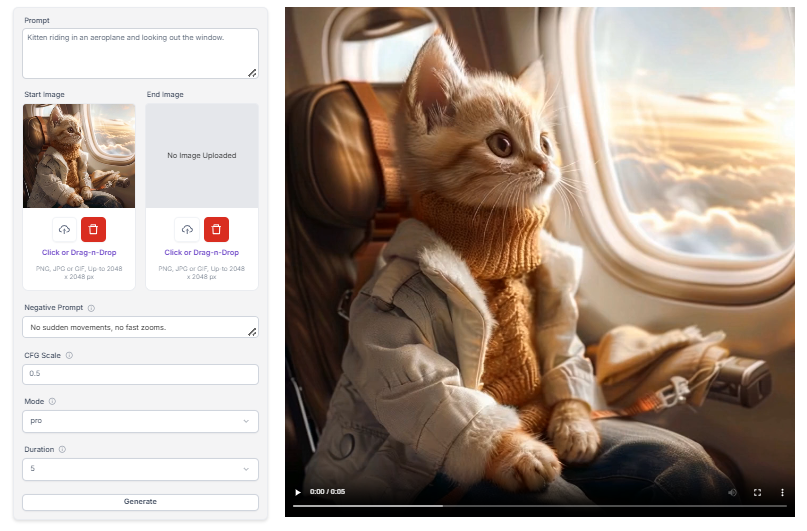
Kling AI is designed to create short-form content, typically generating videos between 5 to 10 seconds in length. While this might seem limiting, it's ideal for creating engaging social media content, short ads, or quick explanatory videos.
Key Features:
- 3D Space-Time Attention: Ensures smooth transitions and realistic motion in generated videos.
- Dynamic-Resolution Training: Supports various aspect ratios for different content needs.
- Efficient Processing: Quickly generates high-quality videos from static images.
- Detailed Prompt Control: Allows for precise customization of output through text prompts.
Compared to other models, Kling AI excels in efficiency and aspect ratio flexibility. While tools like Luma Dream Machine might offer longer video outputs, Kling AI's focus on short-form content makes it particularly suited for social media and digital advertising.
To use Kling AI, start by uploading an image to serve as the first frame. Then, provide a detailed text prompt describing the desired scene, actions, and camera movements. You can adjust output settings like resolution, aspect ratio, and video length to suit your needs. For best results, use high-resolution images and refine your prompts through multiple iterations.
Best For: Kling AI is ideal for creators who need to quickly produce short, high-quality videos. It's particularly useful for:
- Social media marketers creating engaging short-form content
- Advertisers developing brief, attention-grabbing video ads
- Educators making concise explanatory videos
- Content creators looking to add motion to static images for increased engagement
7. Sora - Best For Realistic, Complex Video Scenes
Sora, developed by OpenAI, is a cutting-edge AI video generator focused on creating realistic, high-quality videos with detailed customization. It's designed to handle complex scenes, making it suitable for professional video production and creative projects.
This tool stands out for its ability to generate highly realistic videos that can include multiple characters, complex actions, and detailed environments. Sora's strength lies in its understanding of the physical world, allowing it to create videos that adhere to real-world physics and logic.
Sora produces 60-second videos by combining 4-6 second clips. This approach allows for the creation of longer, more complex narratives while maintaining high quality throughout the video.
Key Features:
- Realistic Video Generation: Creates highly detailed and lifelike videos from text prompts.
- Complex Scene Handling: Capable of generating videos with multiple characters and intricate environments.
- Physical World Understanding: Produces videos that adhere to real-world physics and logic.
- Longer Video Capability: Combines short clips to create 60-second videos.
Compared to other models, Sora excels in creating highly realistic and complex video scenes. While tools like Kling AI might be more accessible for quick, short-form content, Sora offers unparalleled realism and detail for more ambitious video projects.
To use Sora (when it becomes publicly available), you'll likely start by providing a detailed text description of the desired video. This prompt should include information about characters, actions, environments, and any specific visual elements you want to include. The AI will then process this information to generate a video that matches your description as closely as possible.
Best For: Sora is best suited for professional filmmakers, advertisers, and content creators who need highly realistic and complex video content. It's particularly useful for:
- Creating realistic CGI sequences for film and TV
- Developing immersive virtual reality experiences
- Producing high-end commercials and promotional videos
- Generating complex visual storytelling for educational or training purposes
What Are Image-To-Video Generative AI Models?
Image-to-video generative AI models are programs that turn still pictures into moving videos. They use artificial intelligence to understand what's in an image and create new frames that show movement.
These models work by analyzing the input image to identify objects, people, and backgrounds. They then use this information to predict how these elements might move or change over time. The AI creates a series of new images, each slightly different, to create the illusion of motion.
At their core, these models use deep learning techniques. They're trained on large sets of videos and images, learning patterns of movement and change. When you give them a new image, they apply what they've learned to create a video that looks natural and makes sense.
The process typically involves:
- Analyzing the input image
- Predicting possible movements
- Generating new frames
- Smoothing transitions between frames
- Adding any requested effects or styles
The result is a short video clip that brings the static image to life.
Why Use Image-To-Video AI Generators?
Now, here are some of the top reasons why image-to-video generators are worth using:
- Save Time and Effort: These tools can create videos much faster than traditional animation methods. What might take hours or days to animate by hand can be done in minutes with AI. This is especially helpful for people who need to make lots of videos quickly, like social media managers or marketers.
- Cost Reduction: Making videos usually requires expensive equipment and skilled professionals. AI generators can produce good results without these high costs. This makes video creation more accessible for small businesses, educators, and individual creators who might not have big budgets.
- Try New Ideas Quickly: AI generators let you experiment with different video styles and effects easily. You can quickly see how an idea might look in motion without spending a lot of time on detailed animation. This is great for brainstorming or pitching concepts.
- No Special Skills Needed: You don't need to be an expert animator or video editor to use these tools. Most are designed to be user-friendly, so anyone can create videos with a bit of practice. This opens up video creation to more people, allowing for more diverse content.
- Enhance Static Content: These tools can breathe new life into existing images. A product photo can become a rotating 3D view, or a still landscape can turn into a scene with moving clouds and water. This can make your content more engaging and eye-catching.
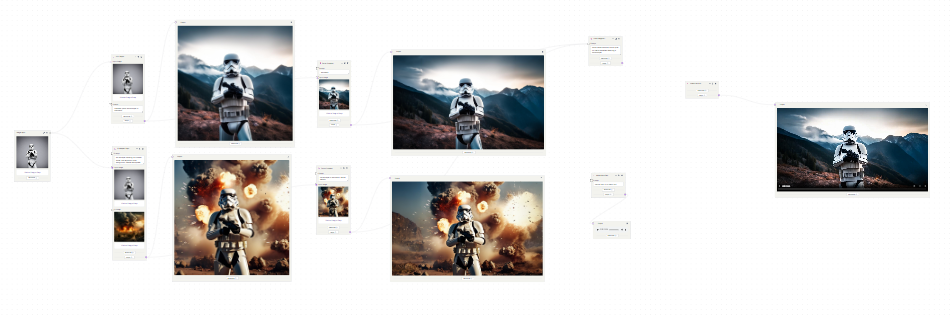
You can even combine multiple AI models with image-to-video AI models to generate high-quality video outputs. For instance, here’s an AI movie trailer custom workflow made using several AI models on Segmind, including Luma Dream Machine Image-To-Video, Fooocus Outpainting, SSD Depth, and more for high-quality results.
How To Pick The Best Image-To-Video Generative AI Model?
When choosing an image-to-video AI model, consider these factors:
- Video Quality: Look at the resolution and overall look of the videos the model produces. Higher resolution (like 720p or 1080p) is better for professional use. Also, check if the motion looks smooth and natural.
- Ease of Use: Some models are simpler to use than others. If you're new to this technology, look for tools with clear instructions and a simple interface. More advanced users might prefer models with more detailed controls.
- Video Length: Different models can create videos of different lengths. Some might only make short clips of a few seconds, while others can produce longer videos. Think about what length you need for your projects.
- Customization Options: Check how much control you have over the final video. Can you specify camera movements? Can you control the style or mood of the video? More options give you more creative freedom.
- Processing Speed: How quickly can the model create a video? This is important if you need to make many videos or if you're working on tight deadlines.
- Input Requirements: What do you need to provide to get a good result? Some models work well with just an image, while others might need detailed text descriptions too.
- Output Formats: Check what video formats the model can produce. Make sure it's compatible with the platforms or software you plan to use.
- Cost and Usage Limits: While we're focusing on free options, check if there are limits on how much you can use the tool. Also, consider potential future costs if you plan to use it a lot.
- Integration: If you're using other tools in your work, see if the AI model can integrate with them. This can make your workflow smoother.
- Updates and Support: Look for models that are regularly updated and have good user support. This ensures you'll have help if you run into problems and that the tool will keep improving.
Test a few different models with your own images to see which gives the best results for your specific needs. Remember, the best model can vary depending on what kind of videos you want to create.
Final Thoughts
Image-to-video AI models are changing how we create video content. They offer a mix of speed, affordability, and creativity that opens up new possibilities for many people. From marketers to educators to artists, these tools are making video creation more accessible and efficient.
As you explore these models, keep in mind that the best choice depends on what you need. Think about the quality you want, how easy the tool is to use, and what specific features matter most to your projects.
Want to enhance your AI video generation process? You might also want to explore Segmind’s PixelFlow platform, which lets you combine different AI models and create your own custom video generation process. This can help you have better control, customization, and make videos that really stand out!