Segmind Vega RT: Model Deep Dive


In this blog, we delve into the intricacies of the Segmind Vega RT (Real-Time). Segmind Vega RT is the world’s fastest image generation model, achieving an unprecedented 0.1s per image generated at 1024x1024 resolution. Segmind Vega RT, a distilled consistency adapter for Segmind Vega, significantly decreasing the required number of inference steps to only 2 to 8 steps.
Under the Hood
Segmind Vega RT is a distilled LCM-LoRA adapter for the Vega model. This innovation significantly reduces the number of inference steps needed to produce high-quality images, with as few as 2 to 8 steps generating results. Consequently, it takes less than 0.1 seconds to create an image using a Nvidia A100.
The underlying technology, Latent Consistency Model (LCM) LoRA, was introduced in 'LCM-LoRA: A Universal Stable-Diffusion Acceleration Module' by authors Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu et al.
How does the LCM-LoRA work?
LCM-LoRA operates through two main ideas:
- Latent vectors in LDMs remain consistent over various diffusion stages, indicating that they can be utilized repeatedly, cutting down on computational expenses and memory demands.
- Latent vectors in LDMs can be applied across distinct fine-tuned models, allowing them to produce images for diverse uses and fields.
LCM-LoRA encompasses two primary actions:
- Distillation: A limited number of LoRA layers undergo training to imitate the original LDM's output via a teacher-student design. Integrating the LoRA layers among the LDM's convolutional blocks enables them to modify the latent vectors relative to the noise levels. The outcome is a compact model called LCM capable of producing pictures utilizing fewer diffusion phases and less memory.
- Transfer: Afterward, the LoRA layers get moved to any customized variant of the LDM, without extra instruction. Insertion of the LoRA layers amongst the refined model's convolutional blocks makes them share identical latent vectors with the original LDM. Resultantly, the model generates images catering to varying scenarios and areas, maintaining similar speeds and qualities to LCM.
In summary, LCM-LoRA focuses on training only a few adapters, referred to as LoRA layers, rather than the entire model. These LoRA layers are integrated within the convolutional blocks of the Latent Diffusion Model (LDM), where they learn to replicate the initial model's outputs. By doing so, the final model, named LCM, can create images using reduced diffusion steps and lesser memory usage.
Segmind Vega Architecture
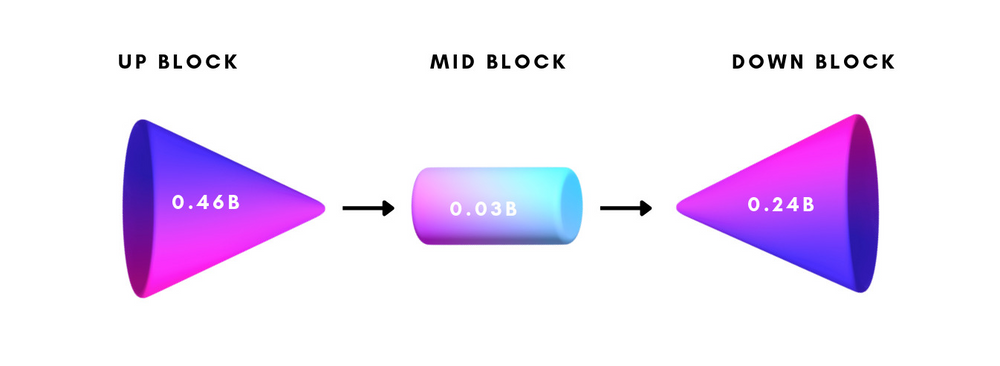
Segmind Vega is a symmetrical, distilled version of the SDXL model, being more than 70% reduced in size and delivering speeds twice as fast. Its configuration consists of three primary components - the Down Block (comprising 247 million parameters), Mid Block (containing 31 million parameters), and Up Block (totaling 460 million parameters). Despite its decreased dimensions, Vega's structure remains largely similar to that of SDXL, allowing seamless integration with pre-existing systems via minor modifications or enhancements. While not as extensive as the SD1.5 Model, Vega offers superior high-resolution output capabilities thanks to its SDXL architecture, rendering it a fitting substitute for SD1.5.
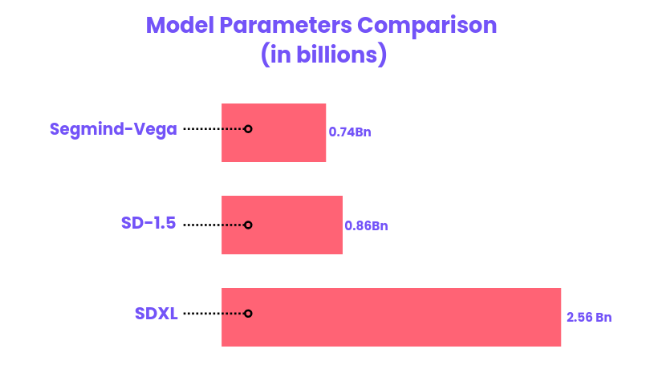
To delve deeper into the intricacies of Segmind Vega, you can check out this blog
Limitations
While Segmind Vega RT boasts impressive real-time performance at higher image resolutions, there are certain limitations to consider.
- Firstly, while the model excels at creating detailed portraits of humans, it struggles to accurately generate full-body images, often resulting in deformities in limbs and facial features.
- Additionally, being an LCM-LoRA model means that it does not support the use of negative prompts or guidance scales.
- Lastly, due to its smaller size and lower parameter count, the model's output lacks diversity and may be most effective for specialized applications when fine-tuned.
A Hands-On Guide to Getting Started
Segmind's Vega RT model is now accessible at no cost. Head over to the platform and sign up to receive 100 free inferences every day! Let's go through the steps to get our hands on the model.
Building the prompt
Effective prompts are essential for guiding the model. Craft clear instructions detailing desired modifications. Experiment with different prompts to personalize results. Utilize the user-friendly Segmind Vega interface for seamless interaction and creative image generation.
Let's have a look at the results produced :
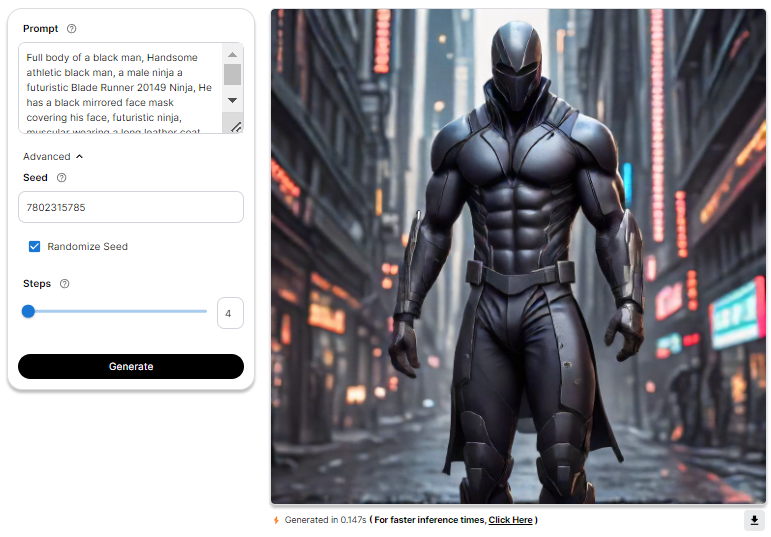
Adjusting the Advanced Settings
Let's explore advanced settings to enhance your experience, guiding you through the details for optimal results.
1. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.

Opting for more denoising steps also comes at the cost of slower and more expensive inference. While a larger number of denoising steps improves output quality, it's crucial to find a balance that meets specific needs.
2. Seed
The seed is like a kickstart for the random number generator, which sets up how the model begins its training or creating process. Picking a particular seed makes sure that every time you run it, the model starts in the same way, giving you results that are consistent and easy to predict.
Code Unleashed
Segmind offers serverless API to leverage its models. Obtain your unique API key from the Segmind console for integration into various workflows using languages such as Bash, Python, and JavaScript. To explore the docs, head over to Segmind Vega RT API.
First, let's define the libraries that will assist us in interacting with the Segmind Vega RT API and processing the images.
Next, we'll set up our Segmind Vega RT URL and API key, granting access to Segmind's models. Additionally, we'll define a utility function, toB64, to read image files and convert them into the appropriate format for building the request payload.
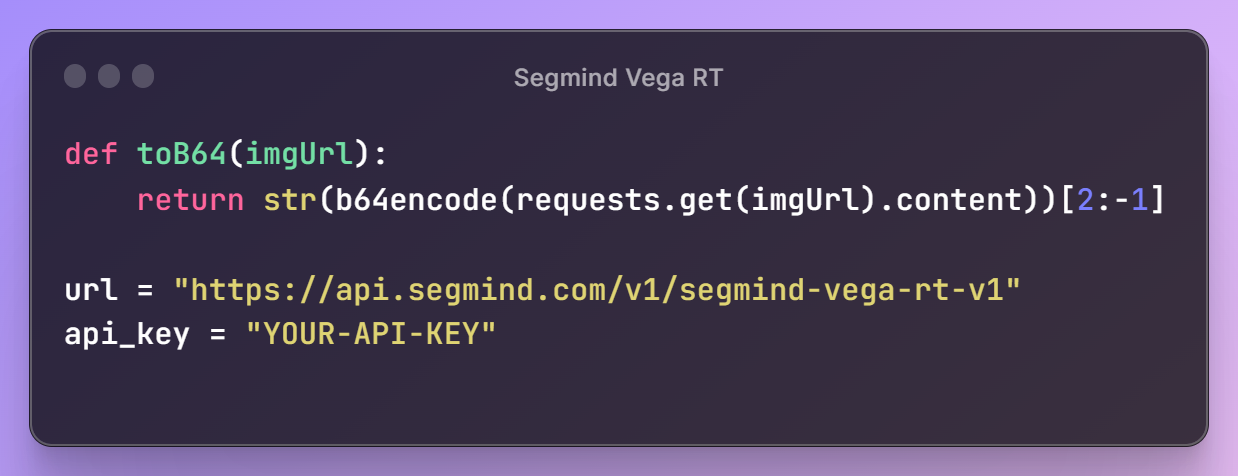
With these initial steps in place, it's time to create a prompt for our image, specify the desired parameter configurations, and assemble the request payload for the API.

Once the request payload is ready, we'll send a request to the API endpoint to retrieve our generated image. To meet our workflow requirements, we'll also resize the image for seamless integration into our next steps.
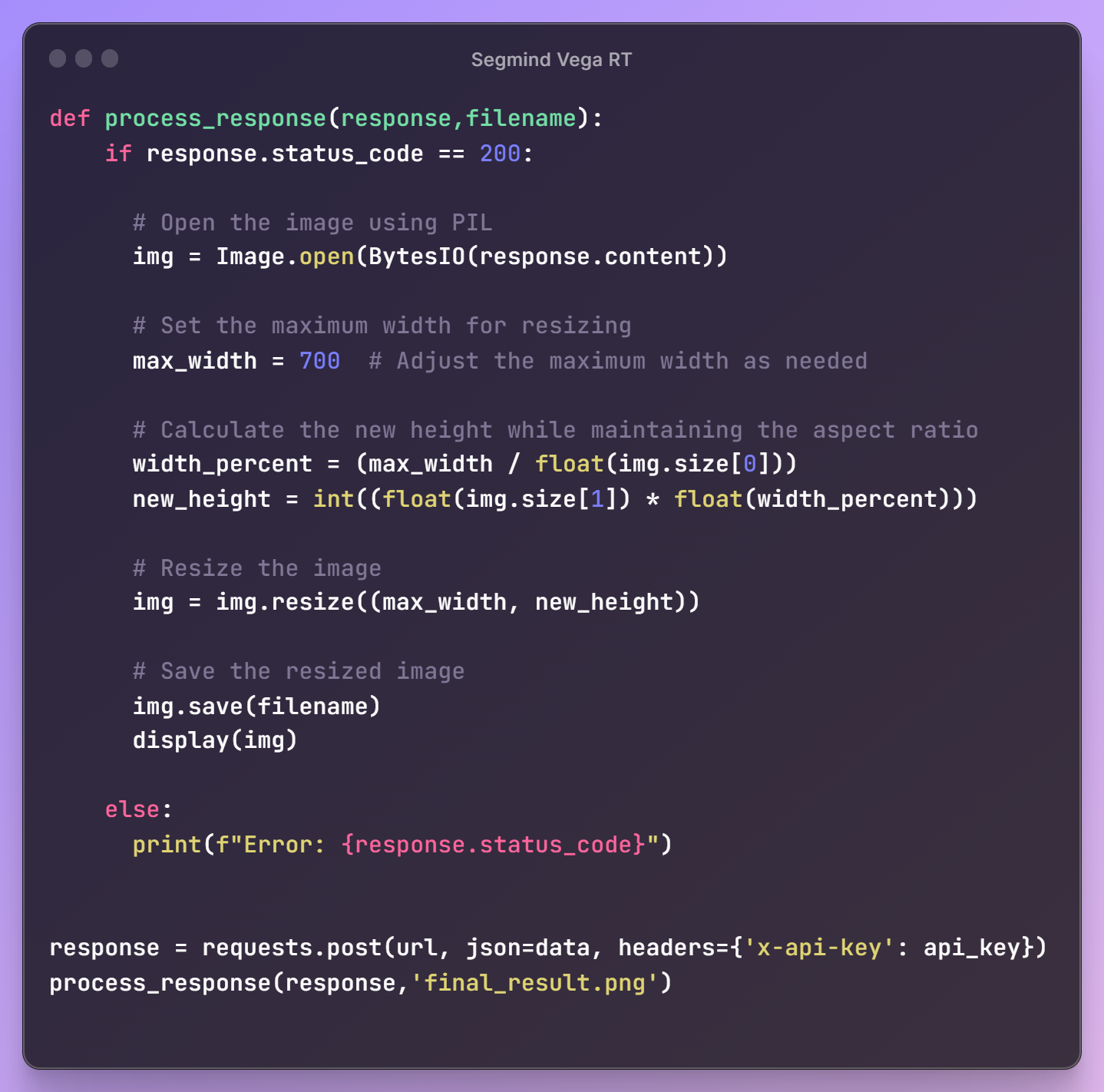
Here's the final result! This module can be effortlessly integrated into your workflows in any language.

Some More Examples





Summary
Experience the power of Segmind Vega RT, Segmind's remarkable real-time image generation model, engineered to produce stunning 1024x1024 resolution images in merely 0.1 seconds. Leveraging the groundbreaking LCM-LoRA acceleration method, it drastically lowers the inference steps for exceptional image generation, ranging between 2-8 steps. It is built upon the Segmind Vega model, a more space-efficient alternative to the SDXL model.
Ready to experience this model's magic firsthand? Segmind's platform invites you to explore its capabilities directly. Experiment with different parameters and witness how they influence your creations. If you favor a systematic workflow, take advantage of the provided Colab notebook, carefully guiding you toward unlocking your artistic potential.