Segmind Vega: Model Deep Dive
The Segmind Vega Model is a distilled version of the Stable Diffusion XL (SDXL), offering a remarkable 70% reduction in size and an impressive 100% speedup while retaining high-quality text-to-image generation capabilities.


In this blog, we delve into the intricacies of the Segmind Vega. The Segmind Vega Model is a distilled version of the Stable Diffusion XL (SDXL), offering a remarkable 70% reduction in size and an impressive 100% speedup while retaining high-quality text-to-image generation capabilities.
Dive deep with us as we uncover the intricate details of its architecture, innovative training techniques, and compare its latency against other models. By the end of this article, you'll have a thorough understanding of how to create images using Segmind Vega and optimize different parameters for your specific use case.
Under the Hood
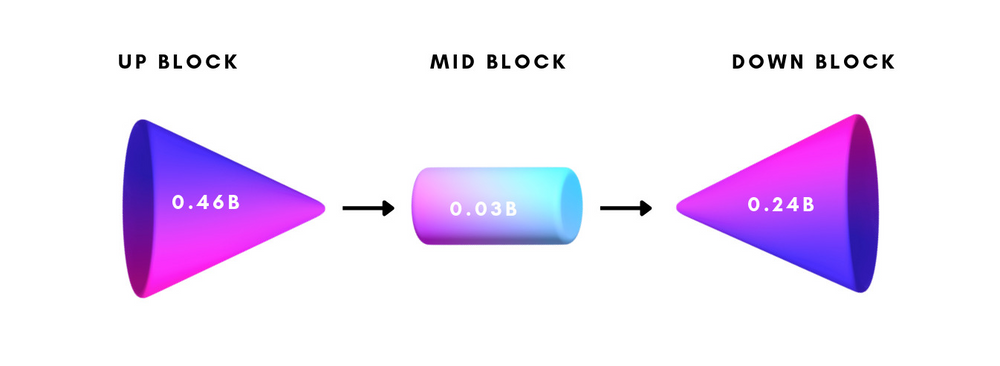
Segmind Vega is a symmetrical, distilled version of the SDXL model, being more than 70% reduced in size and delivering speeds twice as fast. Its configuration consists of three primary components - the Down Block (comprising 247 million parameters), Mid Block (containing 31 million parameters), and Up Block (totaling 460 million parameters). Despite its decreased dimensions, Vega's structure remains largely similar to that of SDXL, allowing seamless integration with pre-existing systems via minor modifications or enhancements. While not as extensive as the SD1.5 Model, Vega offers superior high-resolution output capabilities thanks to its SDXL architecture, rendering it a fitting substitute for SD1.5.
Training
The training technique involves using a distillation-based retraining approach, where it is used to replicate the characteristics of each level of the teacher U-Net model. This is accomplished through the implementation of layer-specific losses during the training process. By doing so, the aim was to effectively transfer knowledge while maintaining the ability of the smaller SDXL models to generate accurate results.

The training plan, which draws inspiration from distillation-based retraining methods, allows the compressed models to acquire critical information from the teacher model. As a result, these compact models can accurately imitate the performance of the initial U-Net across multiple types of layers, such as those involving attention and ResNet.
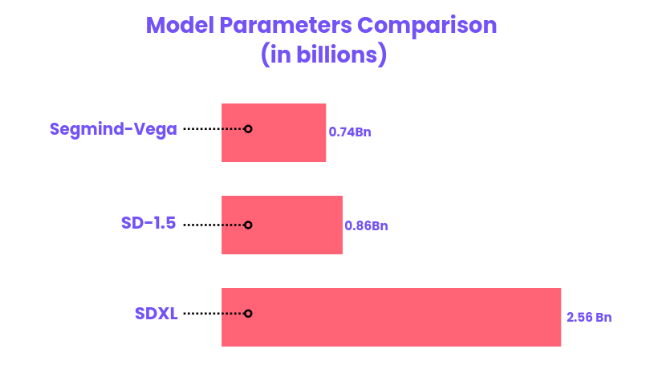
Latency Comparison

The latency comparison chart highlights notable performance distinctions among SDXL, SD1.5, and Segmind Vega models, tested on Nvidia A100 80GB GPUs. In uncompiled model latency, Vega outshines with a 1.39-second latency for 1024x1024 resolution, surpassing SDXL (3.35 seconds) and SD1.5 (1.42 seconds for 768x768 resolution). In compiled model latency, Vega excels further with a mere 0.86-second latency, significantly faster than SD1.5 (0.91 seconds) and SDXL (1.98 seconds). Vega's optimized performance, maintaining speed advantages at higher resolutions, positions it as a formidable choice for time-sensitive applications.
To understand more about the Segmind Vega, you can read this paper:
A Hands-On Guide to Getting Started
Segmind's Vega model is now accessible at no cost. Head over to the platform and sign up to receive 100 free inferences every day! Let's go through the steps to get our hands on the model.
Building the prompt
Effective prompts are essential for guiding the model. Craft clear instructions detailing desired modifications. Experiment with different prompts to personalize results. Utilize the user-friendly Segmind Vega interface for seamless interaction and creative image generation.
Let's have a look at the results produced :
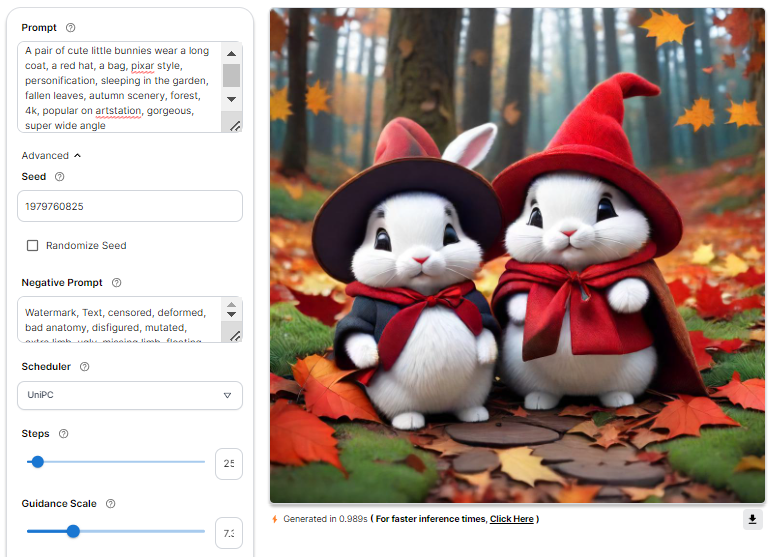
Adjusting the Advanced Settings
Let's explore advanced settings to enhance your experience, guiding you through the details for optimal results.
1. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.

Opting for more denoising steps also comes at the cost of slower and more expensive inference. While a larger number of denoising steps improves output quality, it's crucial to find a balance that meets specific needs.
2. Guidance Scale
The CFG scale, also known as the classifier-free guidance scale, is a setting that manages how closely the image creation process follows the provided text prompt. If you increase the value, the image will adhere more closely to the given text input.

3. Negative Prompt
A negative prompt is like telling the AI what not to include in the picture it generates. It helps avoid weird or strange images and makes the output better by specifying things like "blurry" or "pixelated".

4. Seed
The seed is like a kickstart for the random number generator, which sets up how the model begins its training or creating process. Picking a particular seed makes sure that every time you run it, the model starts in the same way, giving you results that are consistent and easy to predict.
5. Scheduler
Working closely with the UNet segment, schedulers manage both the rate of advancement and intensity of noise throughout the diffusion process. It introduce escalating random noise to the data before subsequently reducing it, resulting in improved image clarity over time. Controlling the pace of alteration and managing noise levels directly influence the ultimate aesthetic qualities displayed by the generated images.
To delve deeper into the intricacies of Schedulers, you can check out this blog
Code Unleashed
Segmind offers serverless API to leverage its models. Obtain your unique API key from the Segmind console for integration into various workflows using languages such as Bash, Python, and JavaScript. To explore the docs, head over to Segmind Vega API.
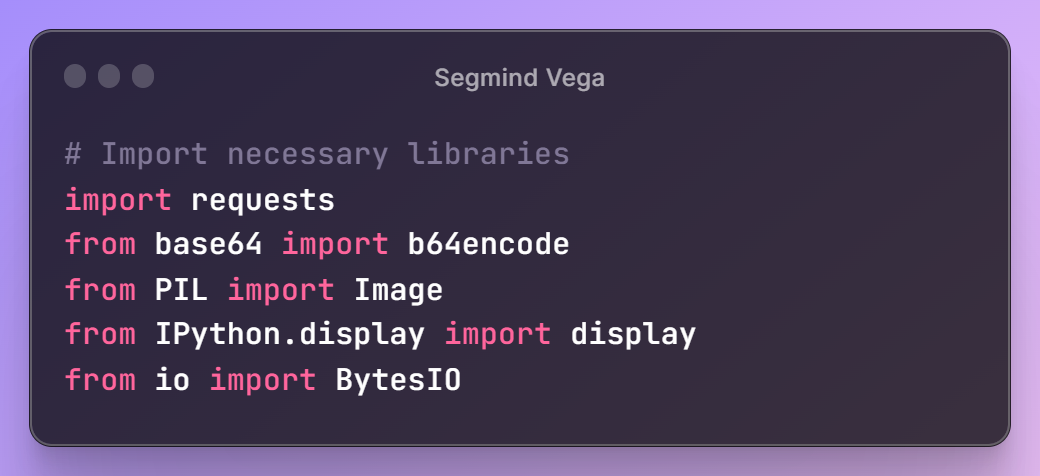
First, let's define the libraries that will assist us in interacting with the Segmind Vega API and processing the images.
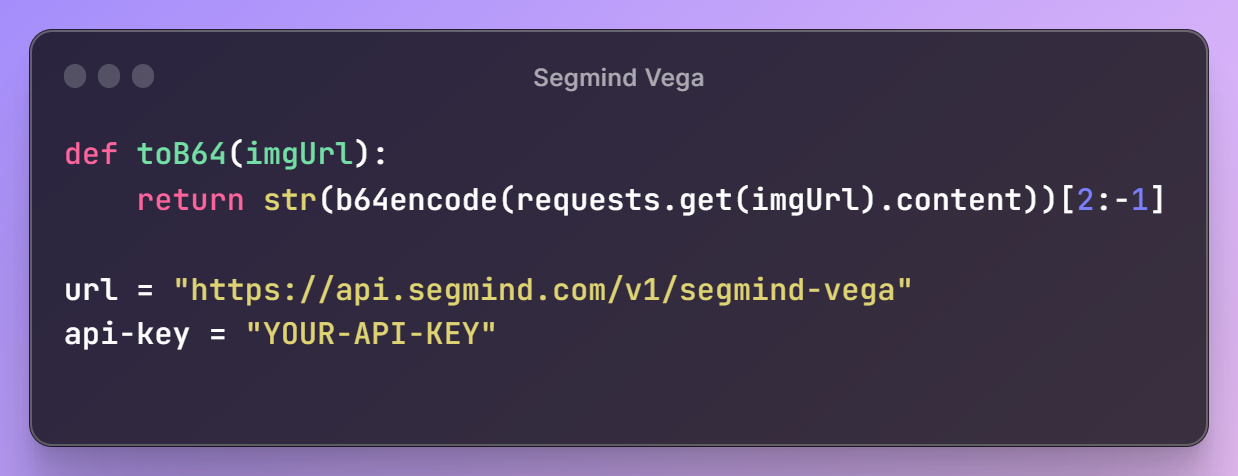
Next, we'll set up our Segmind Vega URL and API key, granting access to Segmind's models. Additionally, we'll define a utility function, toB64, to read image files and convert them into the appropriate format for building the request payload.
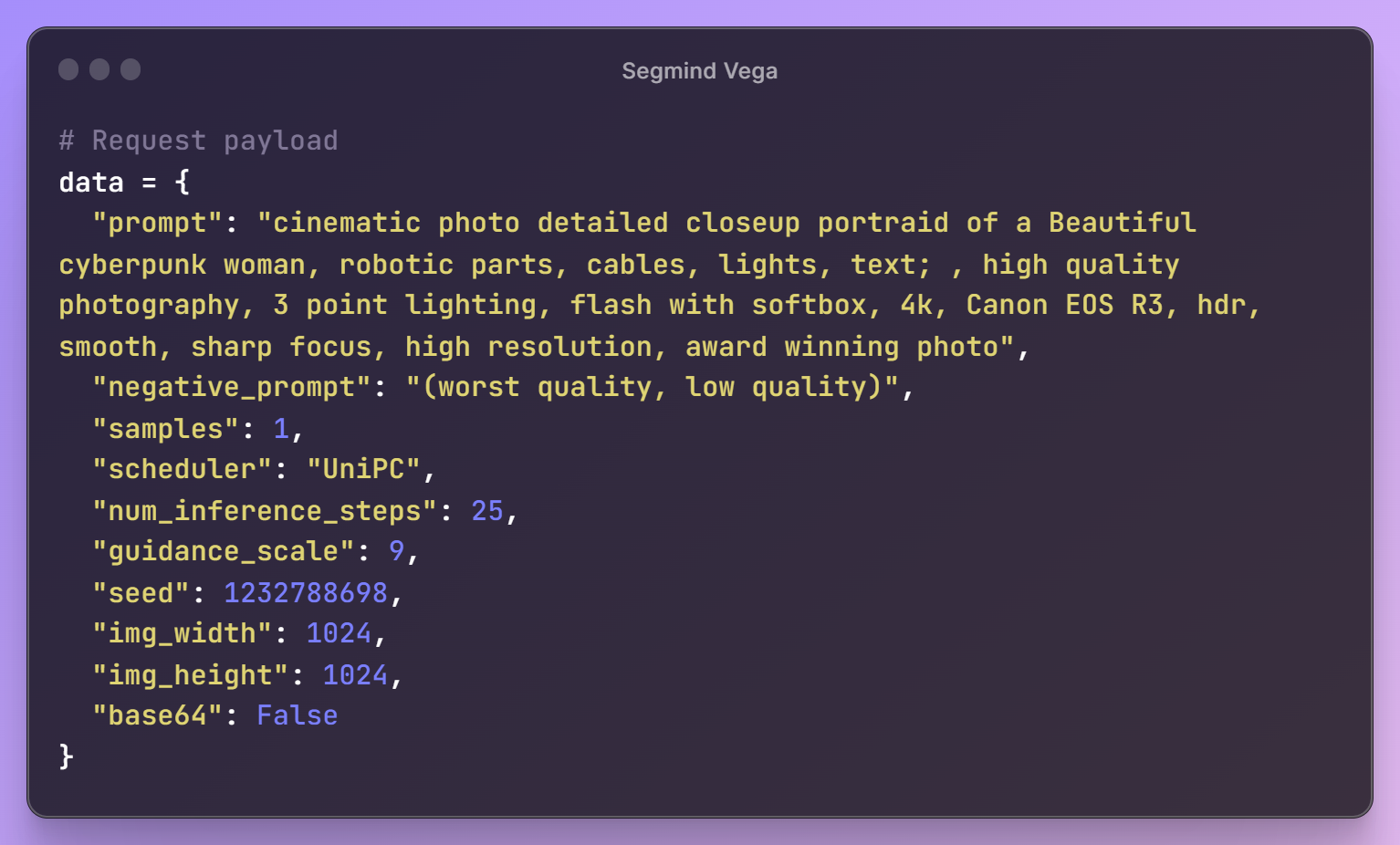
With these initial steps in place, it's time to create a prompt for our image, specify the desired parameter configurations, and assemble the request payload for the Segmind Vega API.
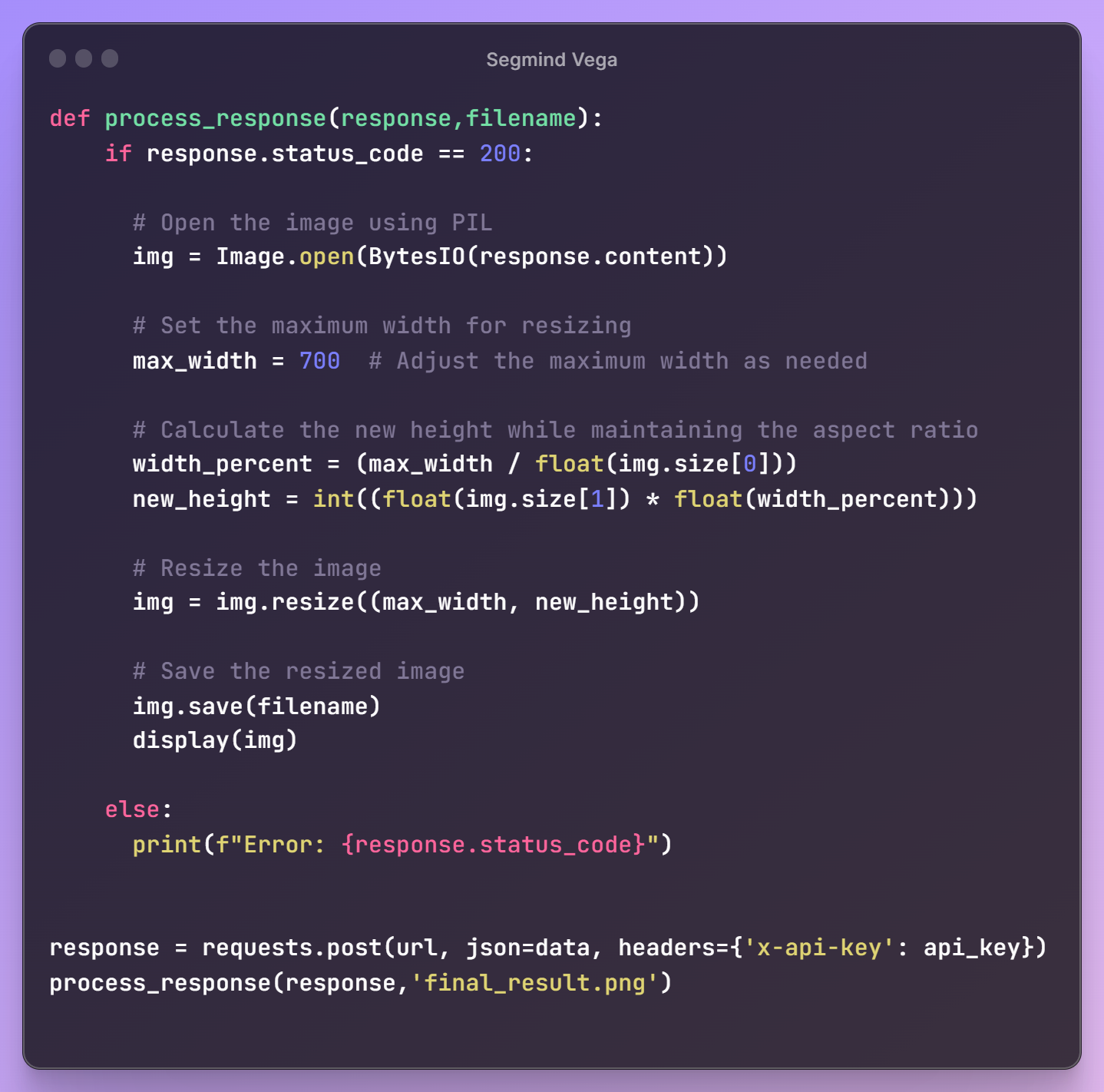
Once the request payload is ready, we'll send a request to the API endpoint to retrieve our generated image. To meet our workflow requirements, we'll also resize the image for seamless integration into our next steps.
Here's the final result! This module can be effortlessly integrated into your workflows in any language.

Some More Examples





Summary
Segmind Vega presents a significant stride in the realm of text-to-image generation, boasting a substantial size reduction and enhanced speed compared to its predecessor, the Stable Diffusion XL, whilst preserving exceptional generative abilities. Through its distinctive distillation-based training methodology and carefully designed architecture, Segmind Vega proves itself to be a powerful tool capable of producing high-quality images with minimal latency. Delving into the world of Segmind Vega promises exciting opportunities for creators, researchers, and developers alike, paving the way for novel applications.
Ready to experience this model's magic firsthand? Segmind's platform invites you to explore its capabilities directly. Experiment with different parameters and witness how they influence your creations. For those who prefer a structured workflow, a Colab file is available, providing a guided path to unleash your creativity.