Segmind Shatters Existing SDXL Benchmarks: Unveiling Ultra-Fast Image Generation with Optimized SDXL 1.0
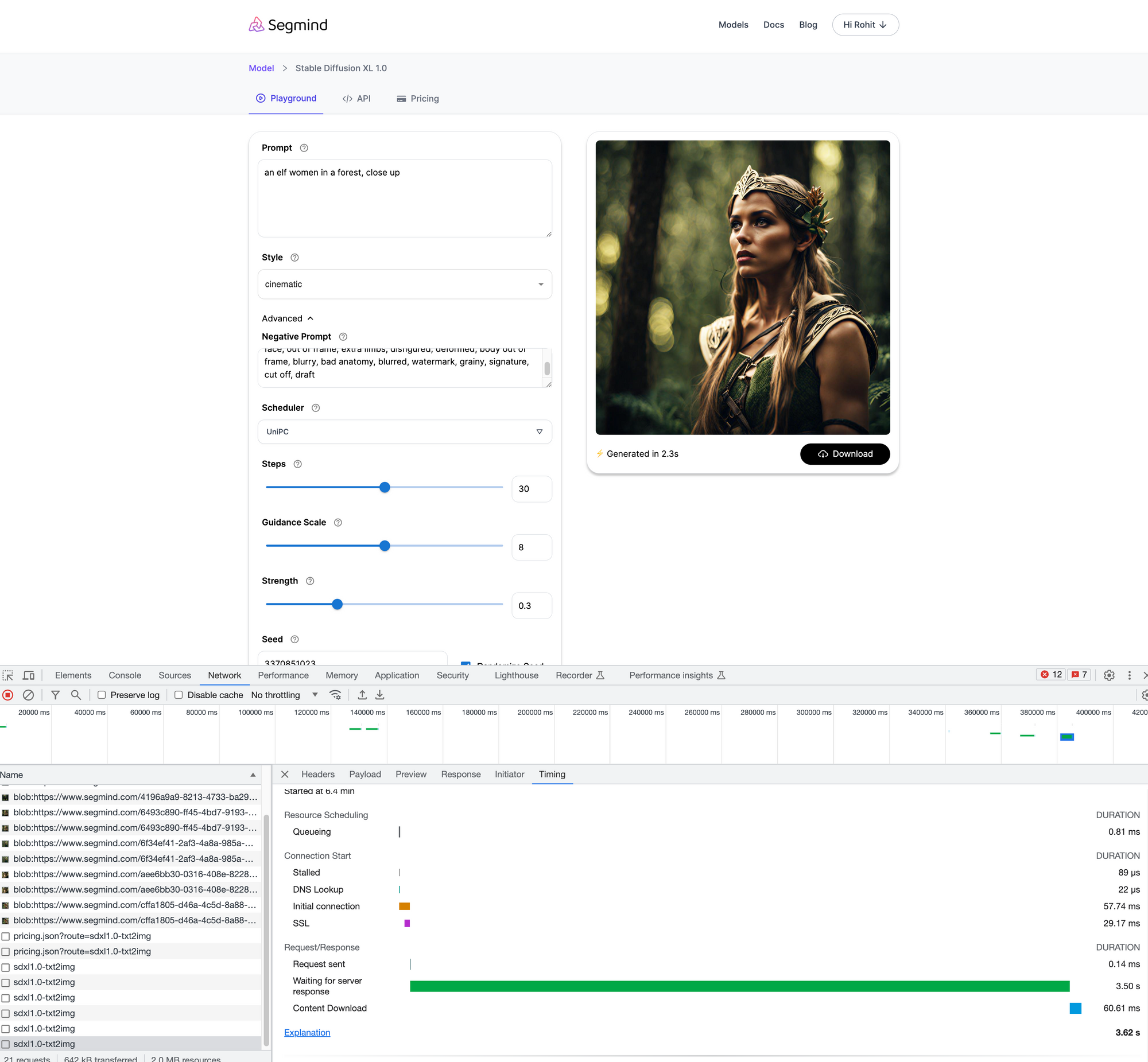
Segmind unveils its groundbreaking optimization of the Stable Diffusion XL (SDXL 1.0) model, setting new standards in rapid image generation. Achieving astonishing speeds, our model generates images in just 2.3 seconds on an NVIDIA A100.


In a groundbreaking advancement, we have unveiled our latest optimization of the Stable Diffusion XL (SDXL 1.0) model. Setting new standards for rapid image generation, our optimized model generates an image in an astonishing 2.3 seconds on a NVIDIA A100, without compromising image quality.
Our serverless APIs are designed to withstand high request loads and ensure robust reliability, which solidifies Segmind's position at the forefront of AI image generation. Developers and tech enthusiasts can now experience this ultra-fast performance firsthand here accelerated endpoint for SDXL 1.0. In essence, Segmind promises market-leading AI-generated image quality, delivered in under 4 seconds end-to-end.
Segmind's Path to Unprecedented Performance
Our optimized SDXL 1.0 employs NVIDIA's TensorRT optimization as well as CUDA Graphs, to achieve this speed and efficiency. An integral part of the optimization process was the evaluation and incorporation of various scheduling algorithms. Of these, UniPC emerged as the standout performer, proving to be the most efficient. Furthermore, Segmind seamlessly integrated the SDXL refiner, recommending specific settings for optimal outcomes, like a prompt strength between 0.1 to 0.3 and a high noise fraction ranging from 0.5 to 0.8.
Recognizing that different applications and tasks may demand distinct optimization strategies, Segmind offers a comprehensive list of schedulers to cater to varying needs. From the precision of "DDIM" and the tailored approaches of "DPM Multi" and "DPM Single," to the sophisticated mechanisms of "Euler a," "Heun," and "DPM2 Karras," the platform ensures that every user finds their ideal match. Additionally, with options like "LMS," "PNDM," "DDPM," and the highly efficient "UniPC" at the users' disposal, Segmind stands out as a platform that prioritizes flexibility and user-centric solutions.
TensorRT, NVIDIA's inference optimizer, is designed to elevate the performance of deep learning models. When coupled with CUDA Graphs, it allows computations to be visually represented as a graph, enabling the CUDA runtime to co-optimize kernels and significantly reduce overhead. Introduced in CUDA 10, CUDA Graphs revolutionized GPU operations by allowing a series of CUDA kernels to be encapsulated as a single graph of operations. This move away from the traditional sequence of individually launched operations meant that multiple GPU operations could be triggered through a single CPU operation, dramatically cutting down launching overheads.
Benchmarking: More than Just Numbers
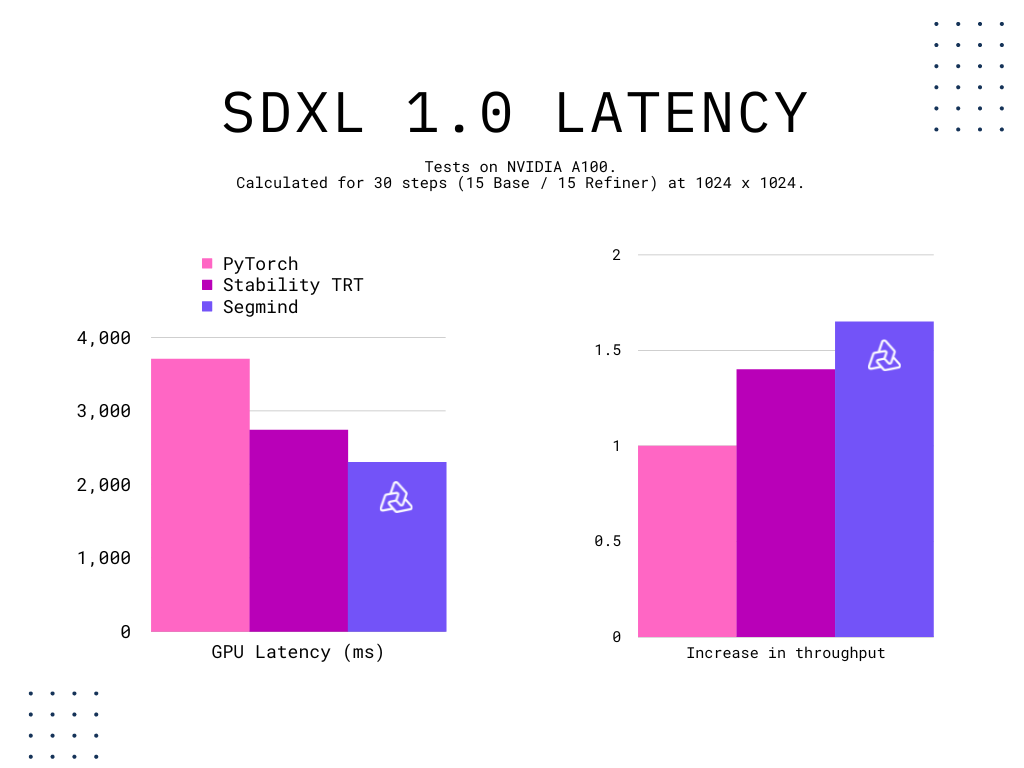
The optimized SDXL 1.0 model boasts a latency of just 2.3 seconds for 30 inference steps, a benchmark achieved by setting the high noise fraction at 0.5 and the prompt strength at 0.3. When focusing solely on the base model, which operates on a txt2img pipeline, for 30 steps, the time taken is 3.7 seconds. These metrics demonstrate Segmind's commitment to pushing the boundaries, promising the market's highest quality AI-generated images over the internet in a record time of under 4 seconds.
As we reflect on Segmind's recent breakthrough with the SDXL 1.0 model optimization, it's clear that we're witnessing a pivotal moment in the realm of AI image generation. This achievement isn't merely about shattering existing benchmarks; it's a testament to what's possible when relentless innovation meets deep expertise. It's not just about creating images faster; it's about reimagining the boundaries of what generative AI can achieve.
With our optimizations, our customers not only can achieve double the throughput on the state-of-the-art SDXL model but also lower their inference costs.
As we look ahead, Segmind's forthcoming launch of fine-tuning APIs further amplifies the anticipation. The promise of crafting specialized models tailored to specific concepts using minimal images offers untold potential for personalized AI applications.
You can contact us via this page to register your interest in Segmind Fine Tuning APIs or Serverless Inference APIs. Segmind provides APIs to over 50 models in image space including Codeformer and Controlnets. Our team would be happy to learn about your requirements and assist you in leveraging generative AI for your company.
References:
StabilityAI Blog