SDXL ControlNet Models for Advanced Image Generation
SDXL ControlNet lets you create unique images using control images! This post dives into how ControlNet supercharges Stable Diffusion XL for user-driven image creation.


SDXL ControlNet models are built on top of Stable Diffusion XL (SDXL), a powerful generative model that produces high-resolution images from textual prompts. It leverages ControlNet as an additional component that conditions the image generation process. It allows you to guide the output by providing a control image.
* Get $0.50 daily free credits on Segmind.
In this blog post, we take a look at various SDXL ControlNet models and how they help in image-to-image transformation.
Control Images in ControlNet
Control images are images that provide specific information to ControlNet about how you want the final image to be modified based on your text prompt. They act like extra instructions for SDXL, allowing for more precise control over the generated image.
- Depth: Provides depth information to guide the model on object placement and perspective.

- Canny Edges: Highlights image edges in the control image, influencing the final image's style and sharpness.
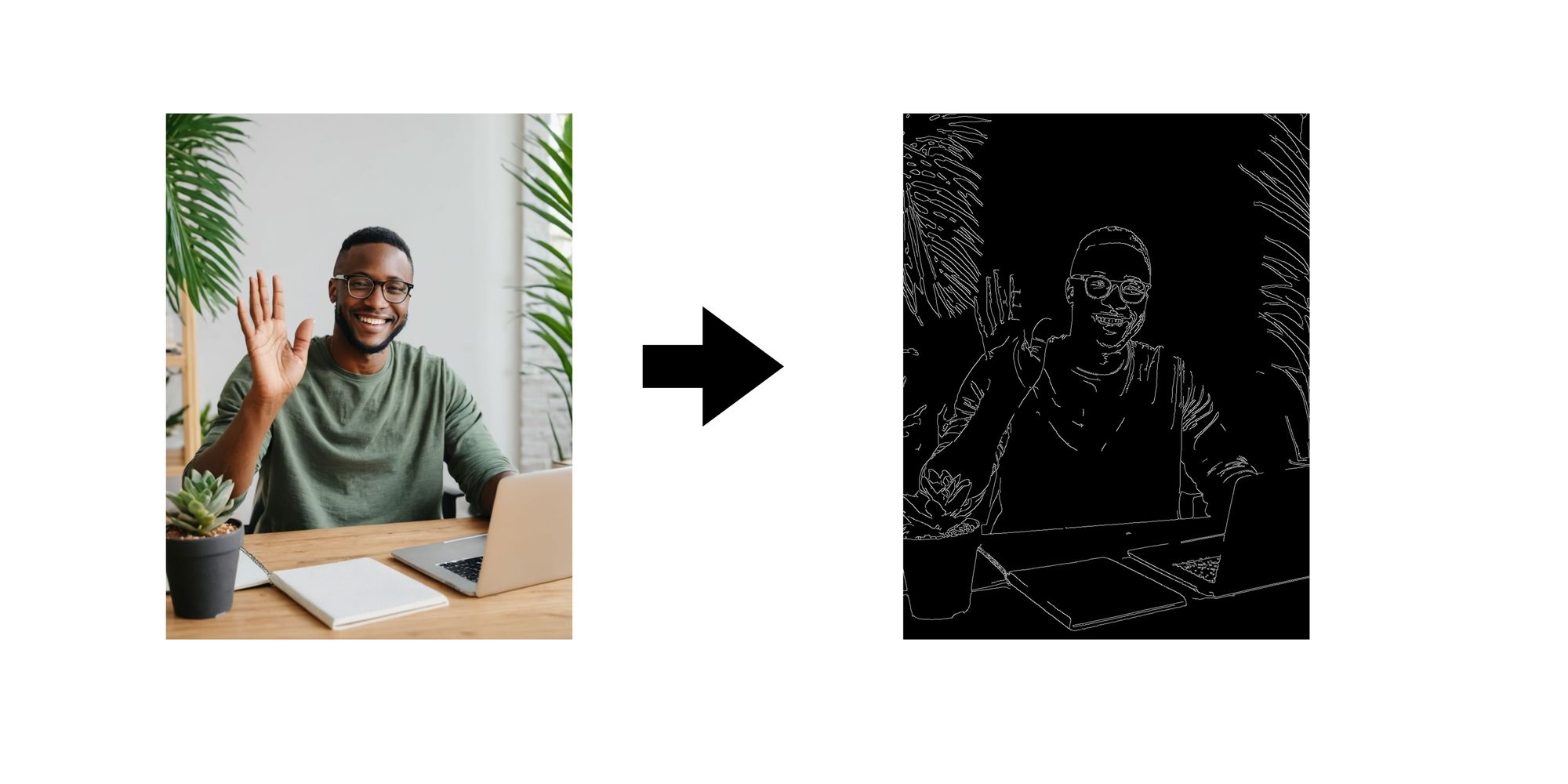
- Softedges: A control image with blurred edges can create a softer, dreamlike quality in the final output.
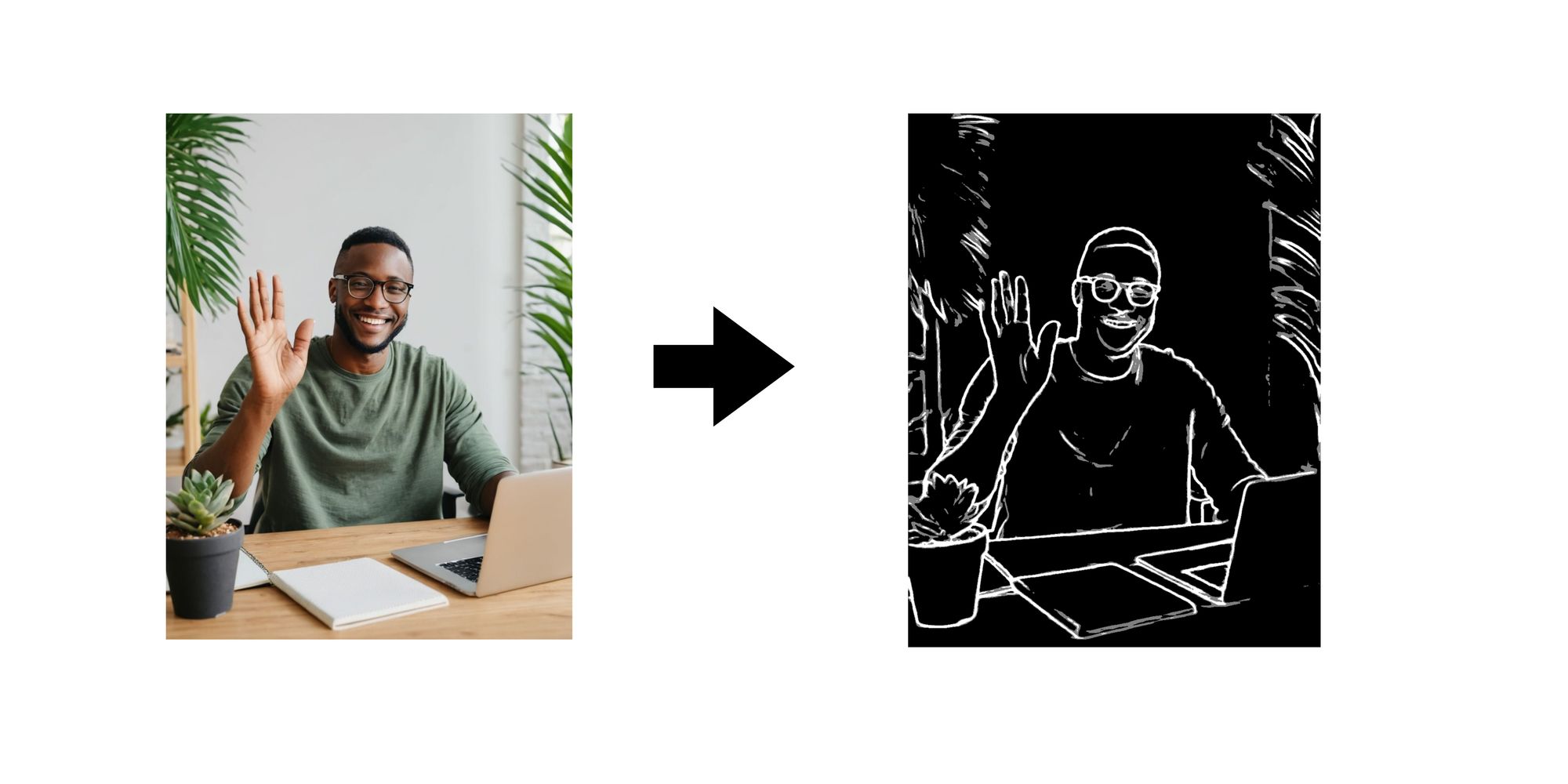
- Scribble: A rough sketch in the control image can act as a loose guide for the model to generate a more detailed scene.

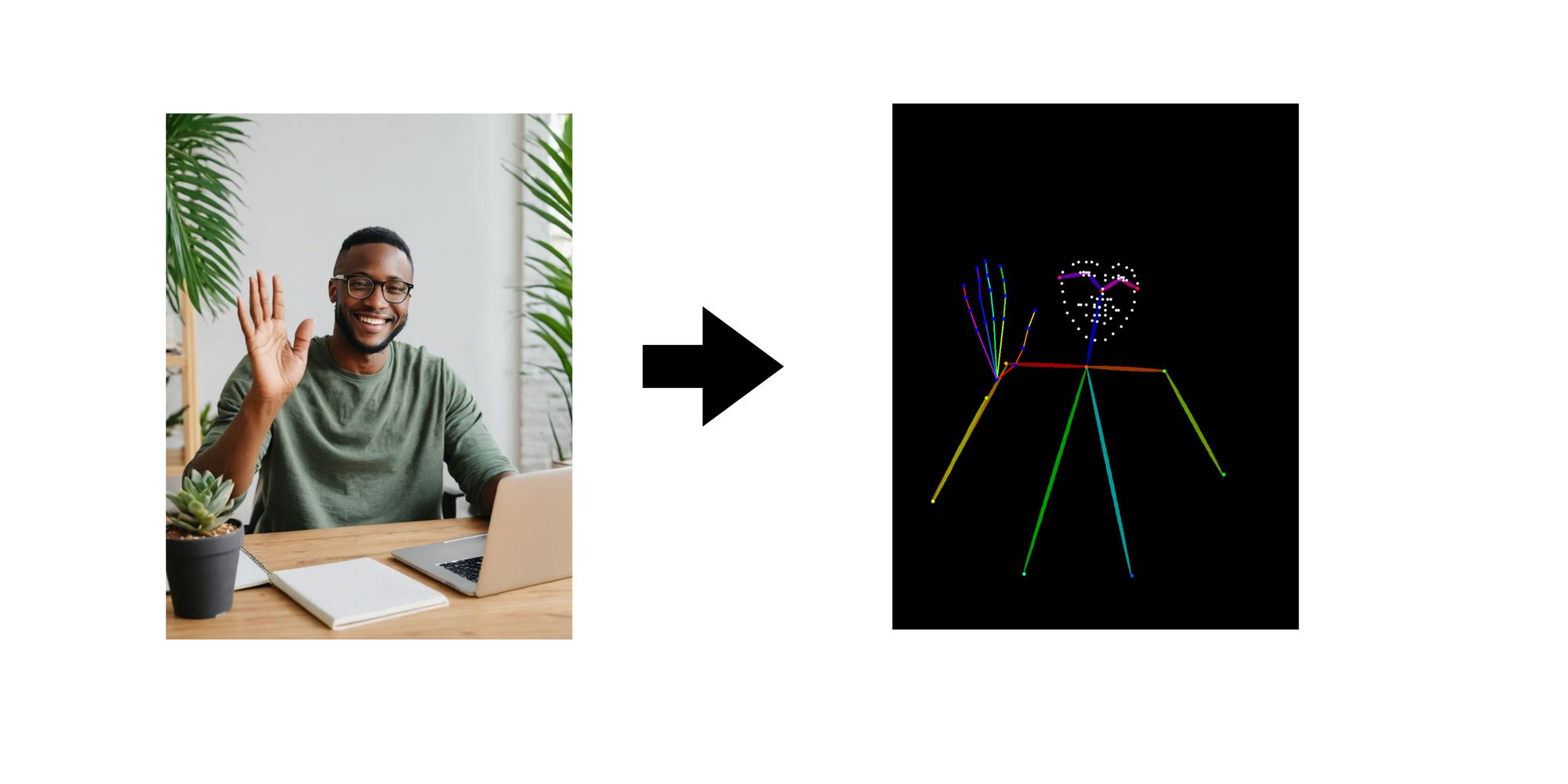
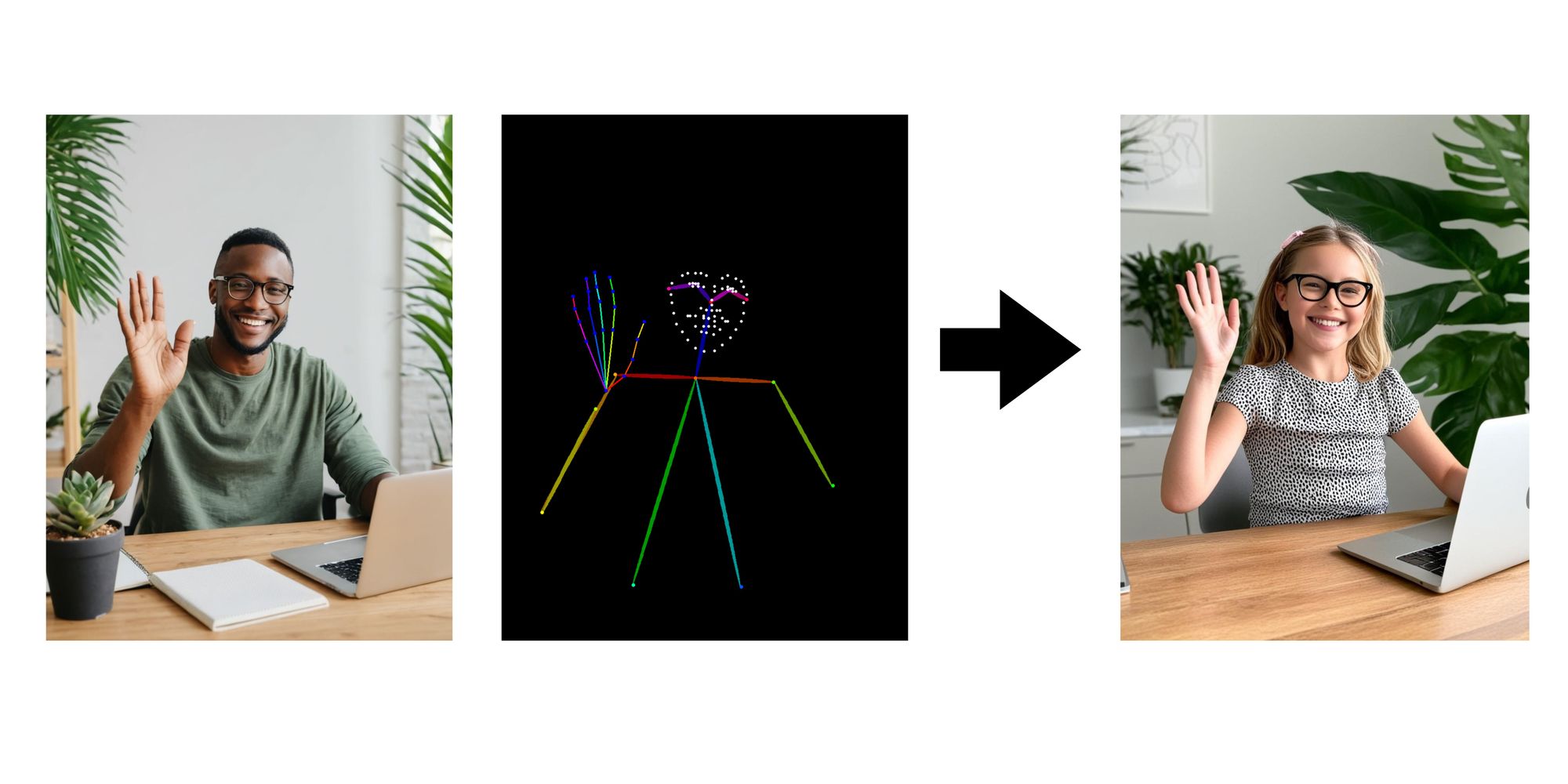
- OpenPose: A control image containing human pose stick figures can be used to direct the pose and position of people in the generated image.
SDXL ControlNet Canny
Canny edge detection is a technique used to identify edges in an image. It highlights the boundaries between different objects or regions. Using your textual prompt and the control instructions from ControlNet derived from the Canny edges, SDXL ControlNet Canny creates the final image. This image will reflect the content described in your text and incorporate the specific edge structure from the Canny control image.

SDXL ControlNet Depth
SDXL ControlNet Depth incorporates depth estimation as part of the control mechanism during text-to-image inference. ControlNet analyzes the depth control image, understanding the relative distances between objects in the scene. It then combines this understanding with your textual prompt to provide comprehensive instructions for SDXL.
It allows you to generate images by providing both a textual prompt and a control image that includes depth information. By incorporating depth information, SDXL ControlNet Depth allows for the generation of images with a much stronger sense of depth and realism. Objects appear closer or further away, creating a more three-dimensional and immersive image.

SDXL ControlNet OpenPose
SDXL ControlNet OpenPose leverages OpenPose conditioning during text-to-image inference. It allows you to generate images by providing both a textual prompt and an OpenPose-based control image.
You provide a detailed description of the image you want to generate using natural language. The OpenPose control image highlights the specific pose you want the person or object in the generated image to have. Imagine a stick figure representing the desired pose. ControlNet takes your textual prompt and analyzes the OpenPose control image. It essentially translates both into a set of instructions for SDXL. Using its understanding of the text prompt and the instructions from ControlNet, SDXL generates the final image. This image will not only reflect the elements described in your text but also incorporate the specific pose defined by the OpenPose control image.
SDXL ControlNet Scribble
SDXL ControlNet Scribble mimics hand-drawn sketches with distinct lines, making it suitable for stylized effects on images. With ControlNet Scribble, you can directly influence the image generation process by manually annotating desired modifications using sketches.
By providing ControlNet Scribble with your sketches, you can directly impact how SDXL generates the final image. The model uses your scribbles as instructions, placing elements and shaping the overall composition based on the strokes.

SDXL ControlNet SoftEdge
SoftEdge is specifically trained to handle soft edges. Here, the focus isn't on strong outlines or dramatic styles, but rather on subtle transitions and detail preservation. Before feeding the image to ControlNet, it's preprocessed using a technique called DexiNed. This preprocessing helps emphasize details and soften sharp edges in the original image. ControlNet analyzes the DexiNed image, understanding the overall composition and the presence of soft edges. Using your textual prompt and the control instructions from SoftEdge ControlNet, SDXL generates the final image. This image will reflect the content described in your text while maintaining the softer edges and details from the DexiNed image.