Flux.1 Fine Tuning: Best Practices & Settings
Learn how to effectively fine-tune your Flux.1 model for exceptional image generation. Discover essential tips for preparing training data, optimizing the fine-tuning process, and testing your model's performance on Segmind.


This guide outlines the key steps for successfully fine-tuning Flux.1 model. It covers the importance of high-quality training data, best practices for testing and generating images using your fine-tuned model. By following these recommendations, you can ensure your Flux.1 model performs at its best and delivers the desired outputs.

Training Data for Fine-tuning
Garbage in, garbage out is a well-known adage in the machine learning world, and it's particularly relevant when fine-tuning flux.1. The quality of your training data significantly impacts the performance of your fine-tuned model. Poor-quality images can limit the model's ability to learn and generate accurate results.

Here are some key considerations for ensuring your training data is of high quality:
- Image Format: All training images should have a square format with a resolution of at least 1024x1024 pixels. Images with non-square aspect ratios must be pre-processed and resized to 1:1 using tools like birme.net for consistency in training data.
- Image Quality: Training images must be free from blur and exhibit a high degree of sharpness. If necessary, use upscalers to enhance the resolution and detail of images before training.
- Subject Isolation: Ideally, each image should focus on a single subject with minimal background elements. This allows the model to concentrate on the specific object or concept of interest.
- Data Diversity: The training data set should encompass a diverse range of images representing the subject from various viewpoints, lighting conditions, and potentially backgrounds. This diversity is crucial for model generalization and accurate subject generation during inference.
- Number of Images in training data: The primary focus should be on high-quality images over sheer quantity. A smaller set of well-curated images (10-15) can yield superior results compared to a larger collection of lower quality images. If you have images of poor quality either fix them or even better replace them with betters ones.
- Captions: Captions are text descriptions associated with each image in the training set. These descriptions provide additional context for the model, aiding in subject identification and generation during prompting. While captioning is valuable for improving model performance, it can be time-consuming. Segmind offers an auto-captioning feature to streamline this process.
Training Your Flux.1 Model
By following these guidelines, you can optimize your Flux.1 fine-tuning process on Segmind and achieve better results.
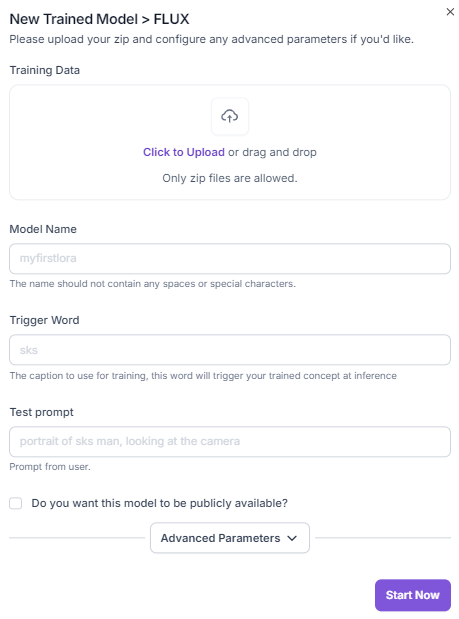
- Ensure that your training images are organized into a ZIP file. This is the preferred format for efficient data transfer and processing.
- Always keep the auto captions feature enabled. This helps Flux better understand the content of your images and provides valuable context for subsequent generations.
- A trigger word serves as a command to initiate the fine-tuning process. Choose a word that is unique and easily recognizable.
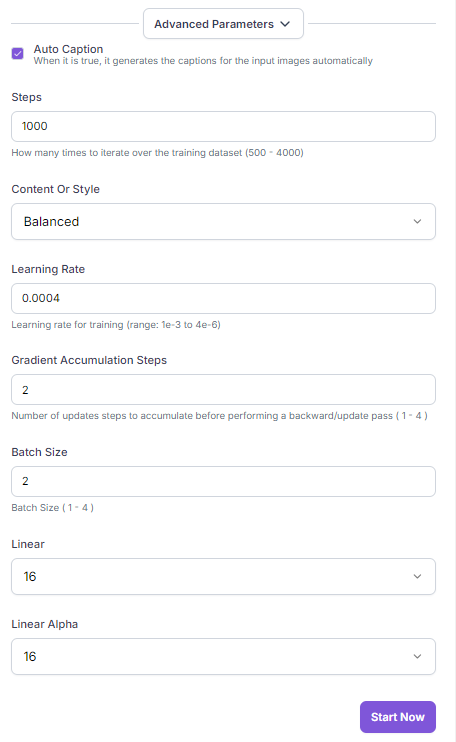
- Begin your fine-tuning with the default parameters like training steps, learning rate, batch size and so on. These settings are carefully chosen to provide a good starting point for most use cases. If you're not satisfied with the initial results, you may want to experiment with adjusting the training steps. Increasing the number of training steps can often lead to improved model performance. However, be mindful that this may also increase training time.
Testing Your Fine-tuned Model
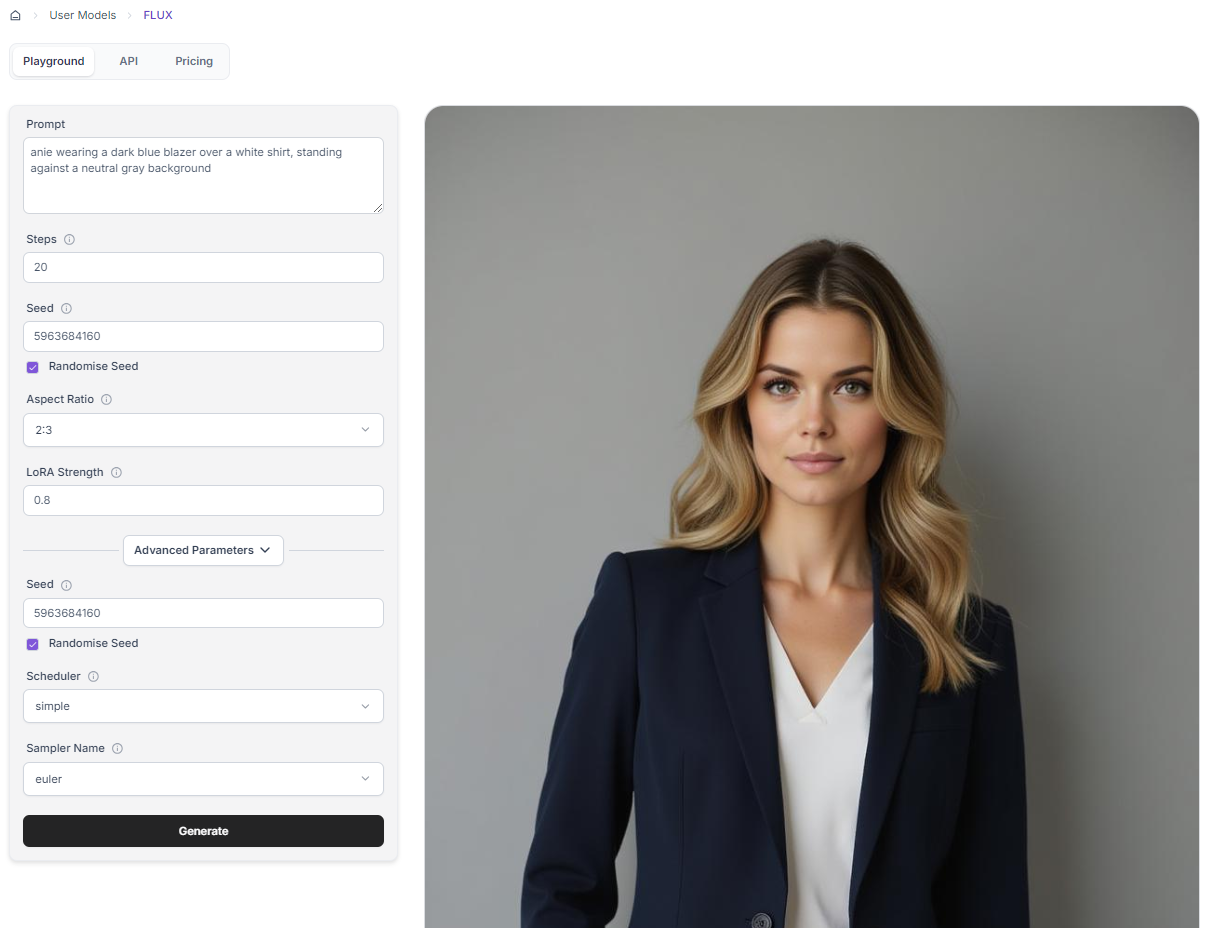
Once your fine-tuned Flux model is deployed on Segmind and ready for use, you can leverage the model playground to generate images based on your prompts. To ensure optimal results, follow these guidelines:
1. Include the Trigger Word in your text prompt
Always include the trigger word you specified during the fine-tuning process in your prompts. This activates the fine-tuned model and ensures accurate image generation based on the learned concepts.
Example: If the trigger word is "mychar", Prompt: "mychar as a superhero, digital art".
2. Recommended Settings:
- Steps: Experiment with different step values, but we found that 25 to 30 steps is the optimal balance between quality and generation speed.
- Lora Strength: Start with a Lora scale between 1 and 1.3. Higher values can increase the impact of the fine-tuning, but be cautious as it may introduce artifacts.
- Scheduler: The Simple scheduler is often a good starting point. Other schedulers like Karras or DPM2 can also be explored.
- Sampler: Euler is a popular sampler known for its balance of quality and speed. Consider trying other samplers like DPM2 or LMS if you encounter issues.
In closing, by following the guidelines outlined in this guide, you can effectively fine-tune your Flux.1 model to achieve exceptional results in image generation. Remember, the quality of your training data and the careful selection of fine-tuning parameters are crucial for optimizing model performance.