A Comprehensive Guide to ControlNet Scribble in Stable Diffusion: Bringing Sketches to Life
Discover the cutting-edge ControlNet Scribble, which blends simple line drawings with textual cues to redefine image generation. This comprehensive guide will unveil the intricacies and potential of integrating Stable Diffusion with ControlNet Scribble in your creative process.


In this blog, we delve into the intricacies of the ControlNet Scribble. This model represents a significant advancement in the realm of image generation by leveraging manual annotations. The ControlNet Scribble introduces an innovative approach, allowing users to actively shape the generation process by simply scribbling or marking desired modifications directly on the image. This approach effectively bridges the gap between user intent and the capabilities of artificial intelligence.
At the core of ControlNet Scribble is a sophisticated mechanism that interprets the annotations made by users as directives for the image generation process. Through the integration of these manual markings, the model comprehends and incorporates user preferences, thereby ensuring that the resulting output closely aligns with the user's envisioned outcome.
Under the hood
ControlNet, a cutting-edge neural network architecture, is built upon a pre-trained Stable Diffusion model that initially learned from extensive image databases containing billions of images. During its training process, ControlNet creates two copies from the Stable Diffusion model: the locked copy, which remains static with fixed weights, and the trainable copy, equipped with adjustable weights that undergo further training iterations. This dual-copy strategy forms the foundation for ControlNet's capacity to integrate spatial conditioning controls into large, pretrained text-to-image diffusion models.
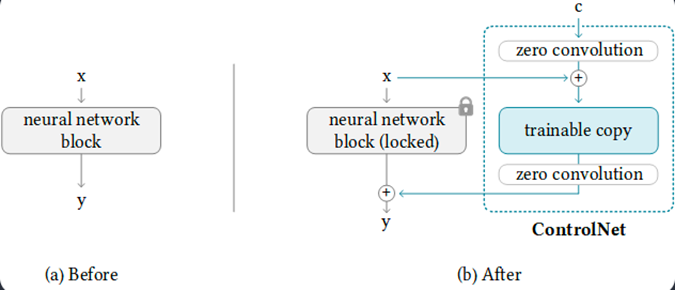
In the early training stages, both the locked and trainable copies exhibit minimal parameter differences. The trainable copy progressively learns specific conditions guided by a conditioning vector ('c'), while the locked copy maintains a consistent set of parameters. To ensure stability during training, ControlNet introduces special zero convolution layers, characterized as 1x1 convolutional units with weights and biases initialized to zero. These layers facilitate a stable training process, aiding the model in transitioning from initial zero states towards optimal configurations.
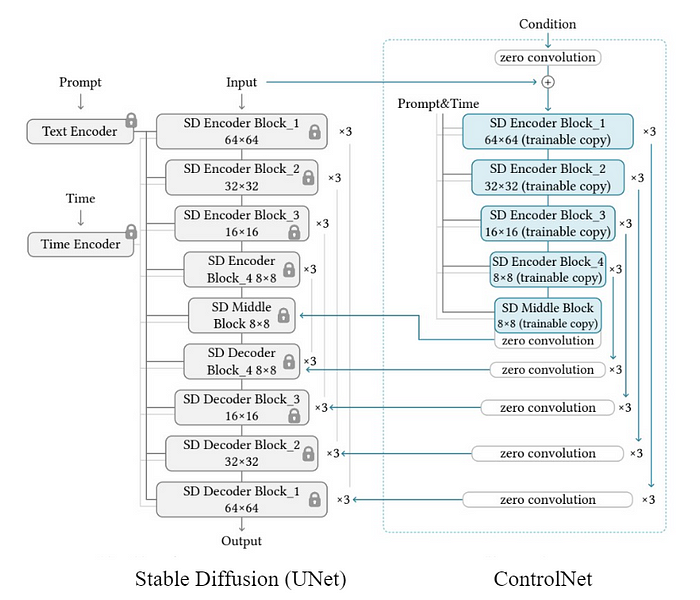
As training advances, ControlNet employs a fine-tuning process that introduces gradual modifications to the trainable copy, alongside the evolution of zero convolution layers. This strategic approach minimizes disruptions to the established characteristics inherited from the pre-trained Stable Diffusion model. The resulting architecture seamlessly manages significant image diffusion models, such as Stable Diffusion, demonstrating a nuanced understanding of task-specific input conditions through its novel technique called "zero convolutions."
To dive deep into the ControlNets, you can check out this blog
Scribble is a feature that mimics hand-drawn sketches with distinct lines, suitable for stylized effects on images. ControlNet Scribble revolutionizes image generation through manual annotations, allowing users to directly influence the process by marking desired modifications. The model interprets user annotations as directives, ensuring the generated output aligns with the user's vision.
A Hands-On Guide to Getting Started
Segmind's ControlNet Scribble model is now accessible at no cost. Head over to the platform and sign up to receive 100 free inferences every day! Let's go through the steps to get our hands on the model.
Prepare your Input Image
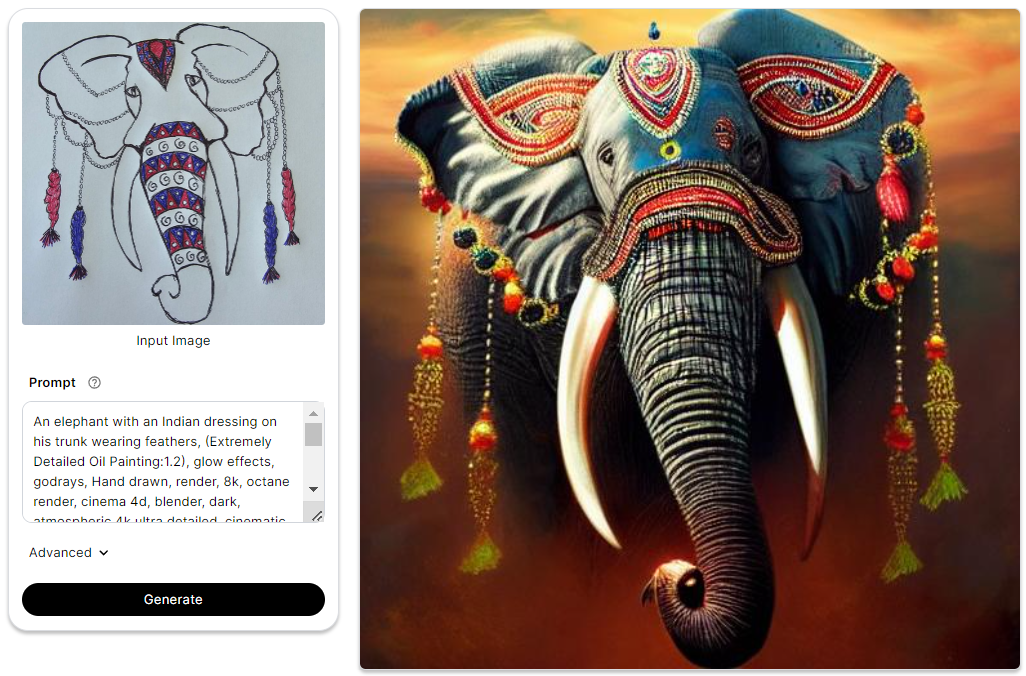
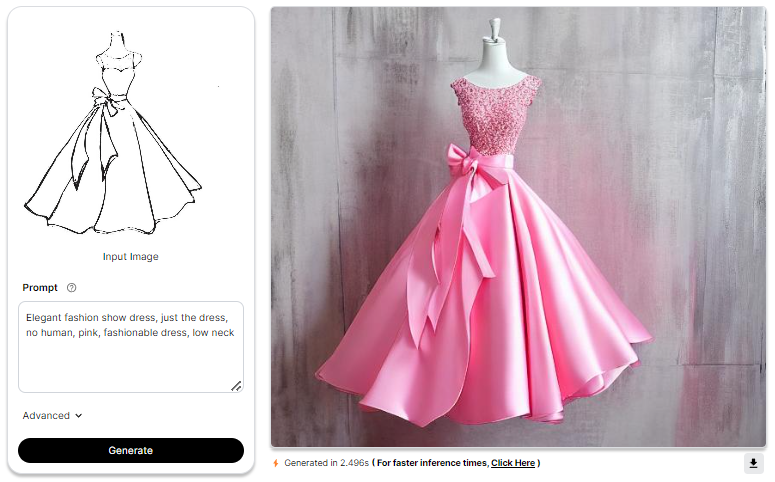
Your chosen image acts as a reference for the ControlNet Scribble model to comprehend and generate results. In this guide, we'll use a picture of a elephant sketch as our input image.
Building the prompt
Creating an effective prompt is crucial. Craft a clear and detailed instruction specifying the modifications or creative preferences you desire in the generated output. Experiment with different prompts to explore the model's capabilities and achieve personalized results. Leverage the user-friendly platform interface to input your prompt and interact seamlessly with the ControlNet Scribble model for a creative image generation experience.
Let's have a look at the results produced :
Adjusting the Advanced Settings
Let's explore advanced settings to enhance your experience, guiding you through the details for optimal results.
1. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.
Opting for more denoising steps also comes at the cost of slower and more expensive inference. While a larger number of denoising steps improves output quality, it's crucial to find a balance that meets specific needs.

2. Guidance Scale
The CFG scale, also known as the classifier-free guidance scale, is a setting that manages how closely the image creation process follows the provided text prompt. If you increase the value, the image will adhere more closely to the given text input.

3. Negative Prompt
A negative prompt is like telling the AI what not to include in the picture it generates. It helps avoid weird or strange images and makes the output better by specifying things like "blurry" or "pixelated".

4. Seed
The seed is like a kickstart for the random number generator, which sets up how the model begins its training or creating process. Picking a particular seed makes sure that every time you run it, the model starts in the same way, giving you results that are consistent and easy to predict.
5. Scheduler
Working closely with the UNet segment, schedulers manage both the rate of advancement and intensity of noise throughout the diffusion process. It introduce escalating random noise to the data before subsequently reducing it, resulting in improved image clarity over time. Controlling the pace of alteration and managing noise levels directly influence the ultimate aesthetic qualities displayed by the generated images.
To delve deeper into the intricacies of Schedulers, you can check out this blog
Code Unleashed
Segmind offers serverless API to leverage its models. Obtain your unique API key from the Segmind console for integration into various workflows using languages such as Bash, Python, and JavaScript. To explore the docs, head over to ControlNet Scribble API.
First, let's define the libraries that will assist us in interacting with the API and processing the images.
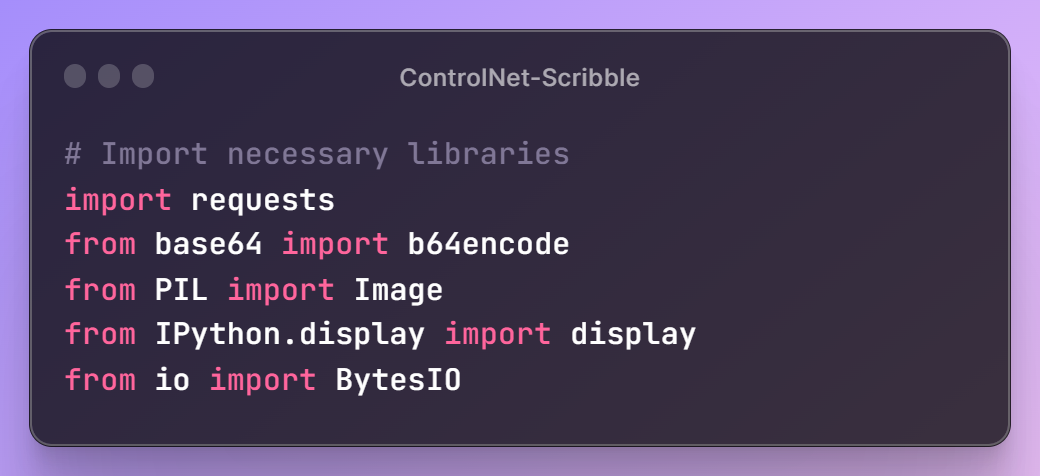
Next, we'll set up our ControlNet Scribble URL and API key, granting access to Segmind's models. Additionally, we'll define a utility function, toB64, to read image files and convert them into the appropriate format for building the request payload.
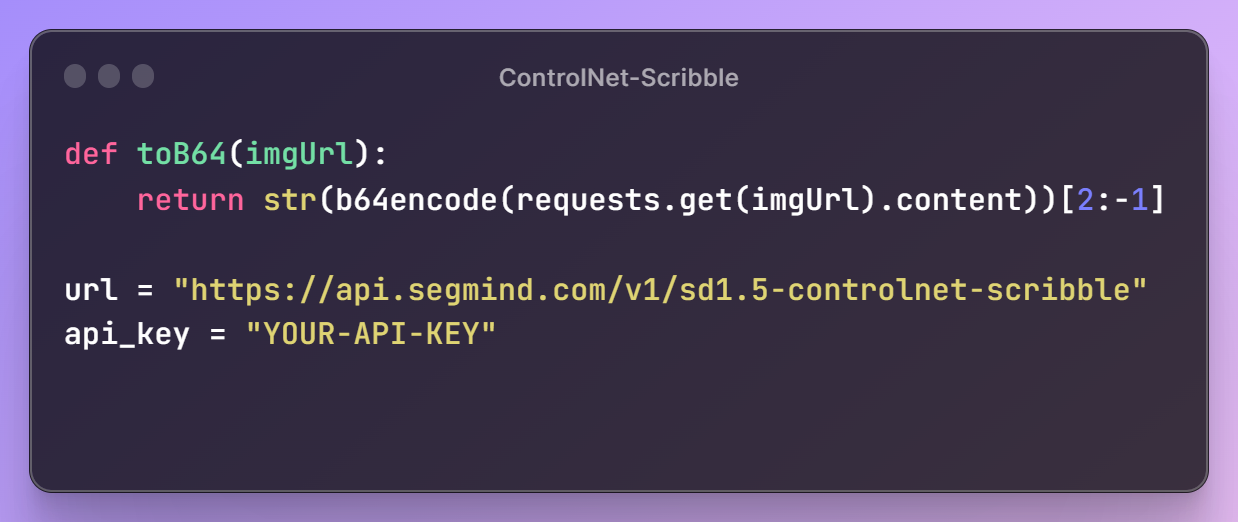
With these initial steps in place, it's time to create a prompt for our image, specify the desired parameter configurations, and assemble the request payload for the API.
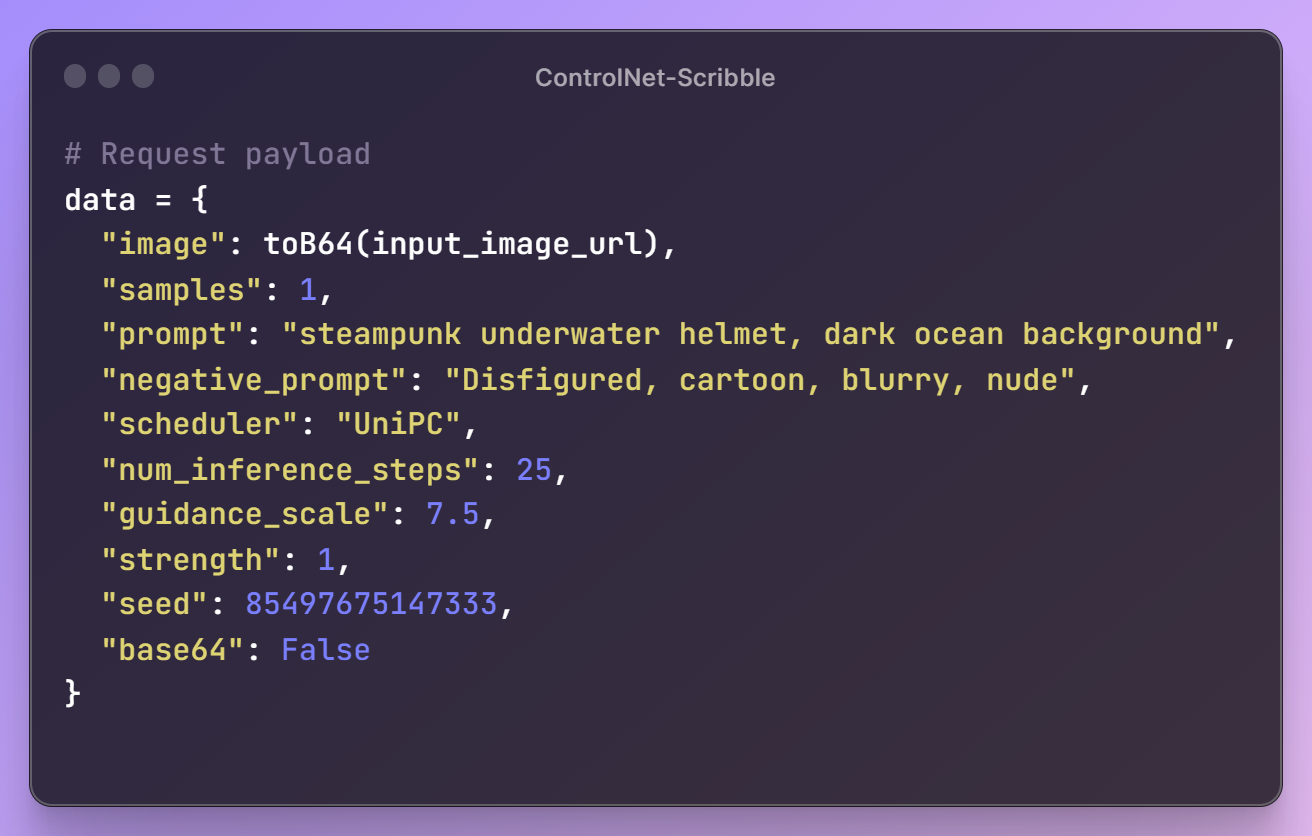
Once the request payload is ready, we'll send a request to the API endpoint to retrieve our generated image. To meet our workflow requirements, we'll also resize the image for seamless integration into our next steps.
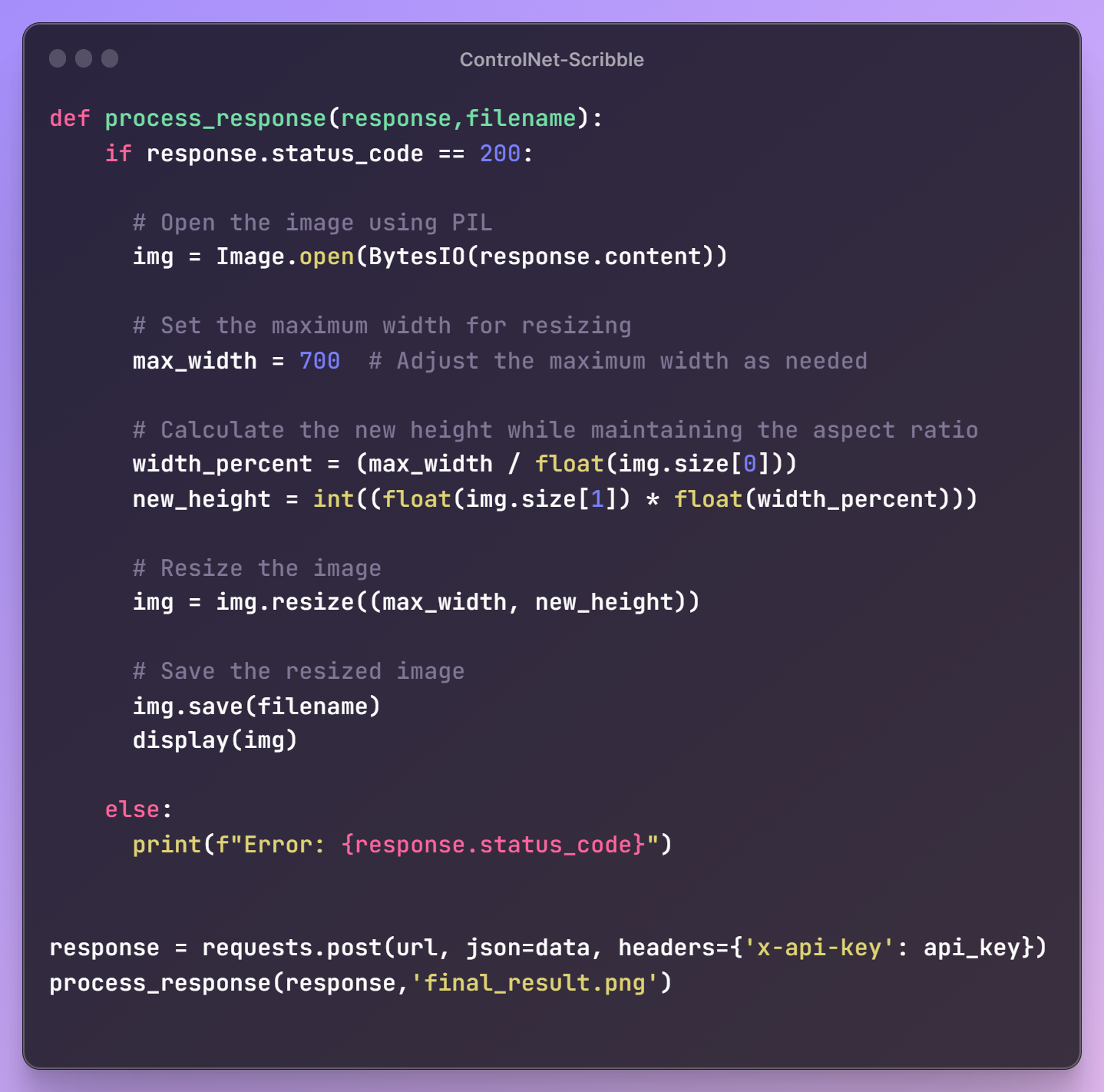
Here's the final result! This module can be effortlessly integrated into your workflows in any language.

Some More Examples
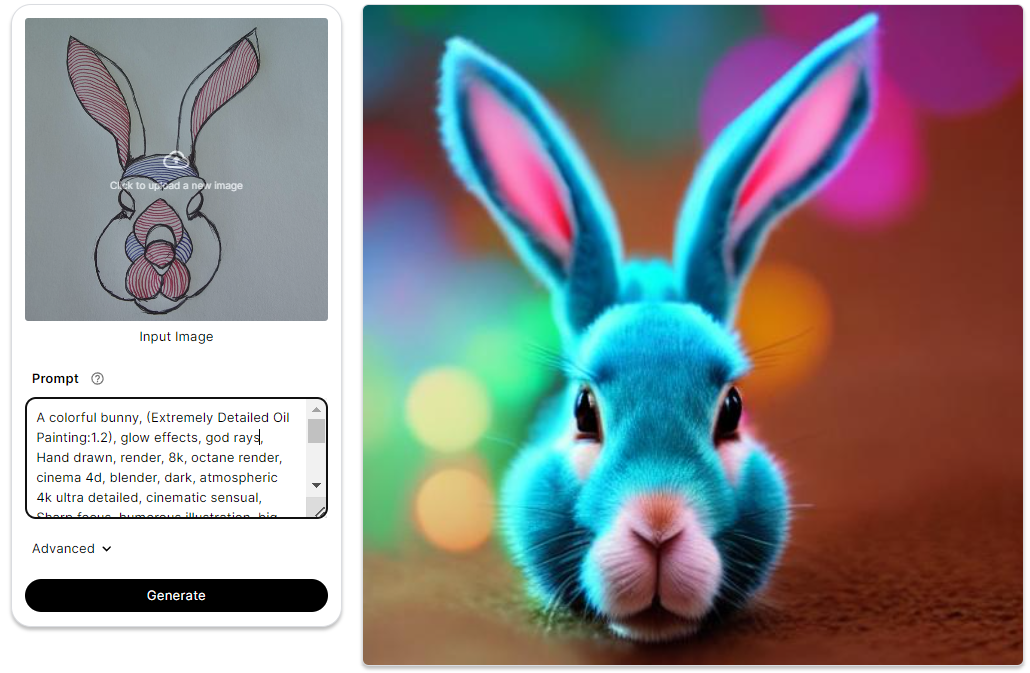
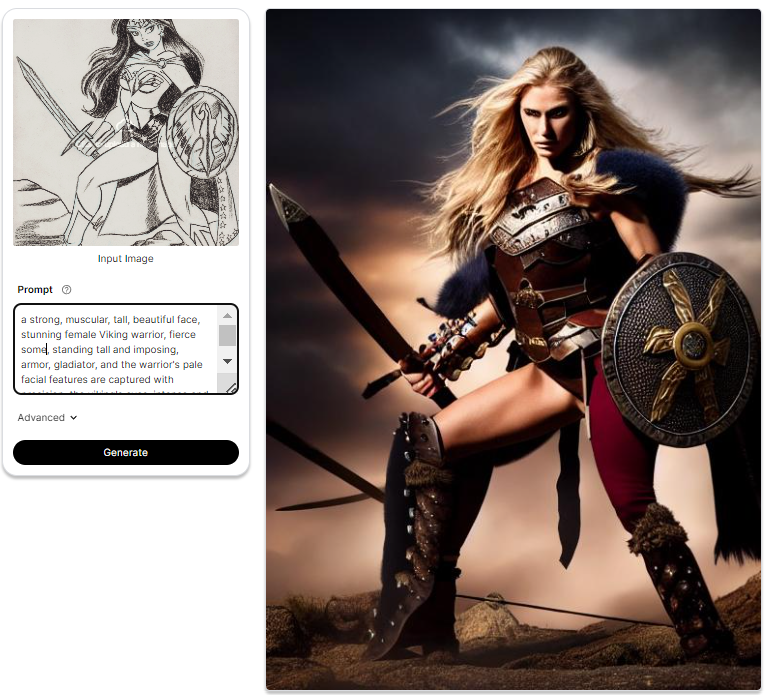
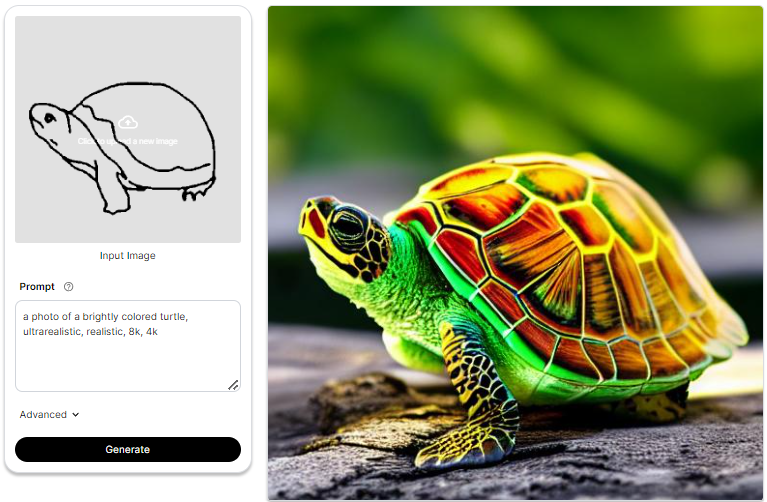
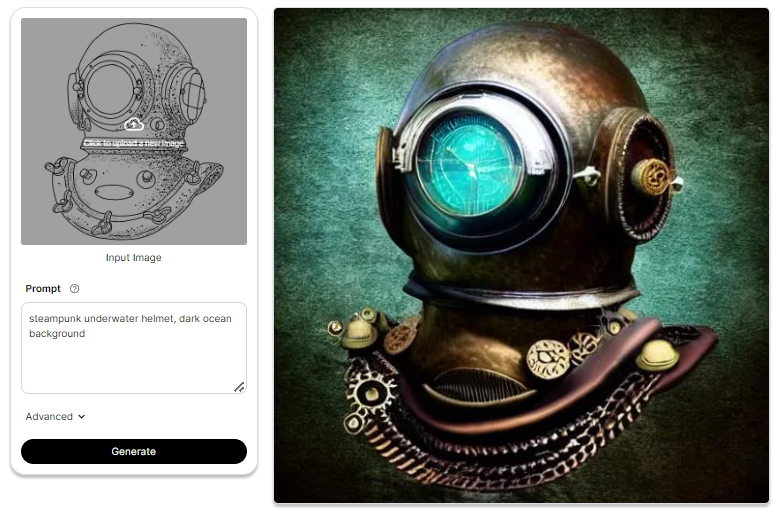
Summary
This blog explores the ControlNet Scribble model, highlighting its innovation in image generation through manual annotations. The architecture, built on a pre-trained Stable Diffusion model, employs a dual-copy strategy and zero convolution layers for stability. The hands-on guide emphasizes user involvement, detailing advanced settings for optimal results, and concludes with a demonstration of seamless integration using Segmind's serverless API.
Ready to experience this model's magic firsthand? Segmind's platform invites you to explore its capabilities directly. Experiment with different parameters and witness how they influence your creations. For those who prefer a structured workflow, a Colab file is available, providing a guided path to unleash your creativity.