Best settings for Codeformer for face restoration
In the realm of image processing, blind face restoration is challenging, involving the restoration of degraded facial images without a clear reference. CodeFormer was introduced to address this complexity.


Introduction
In the realm of image processing, blind face restoration presents a significant challenge. It involves restoring facial images that have undergone degradation without access to a clear reference. Restoration processes often encounter issues related to the lack of well-defined mapping from degraded inputs to desired outputs, as well as the loss of high-quality details present in the original images. CodeFormer was introduced to tackle this complexity.
CodeFormer comprehensively captures the intricate composition and contextual information inherent in low-quality facial images.
Codeformer Architecture and how it works
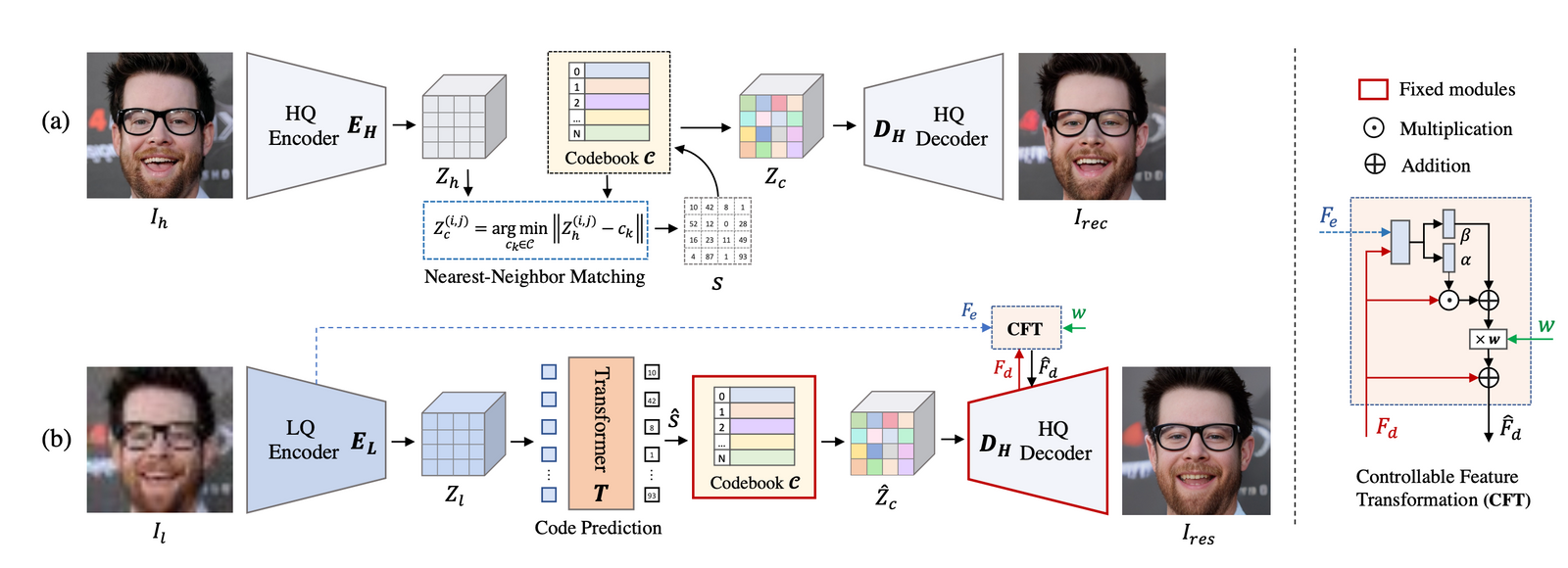
To achieve high-quality facial image restoration, the CodeFormer model first learns a discrete codebook and a decoder via self-reconstruction learning. This allows for the storage of high-quality visual parts of face images. Then, with a fixed codebook and decoder, a Transformer module is introduced for code sequence prediction, which models the global face composition of low-quality inputs. Additionally, a controllable feature transformation module is used to control the information flow. It is important to note that this connection is optional and can be disabled to avoid adverse effects when inputs are severely degraded.
Best settings for Codeformer
To fully utilize the potential of Codeformer, it is crucial to understand its present settings.
Scale
This pertains to the stage of the process where the image resolution is increased to provide greater detail and clarity to the visual representation. This final upsampling scale is a crucial step in the image restoration process, as it greatly impacts the quality and appearance of the final product. A scale value of 0.5 by default gives pretty good results however higher the scale value, the longer it takes to generate the restored image.
Fidelity
Fidelity refers to the level of quality desired in the generated image. Although the Codeformer model produces clear images, it sometimes modifies the inherent facial structure of the given input image to such an extent that the output has less resemblance. This is particularly evident when dealing with old historical images, where the face may bear little resemblance to the original.
To test the restoration process, we gave different sets of challenges to the Codeformer model. various photographs were chosen to evaluate the model's ability to perform well in different settings.

When handling close-up shots, making adjustments to the fidelity value significantly influences the resulting image. Alteration to lower the fidelity values not only changes the overall visual representation of the image but also results in an overly pronounced smoothing of the skin texture. To achieve optimal outcomes, it's strongly recommended to employ a specific configuration, such as {“fidelity”:1 }, when working with close-up shots. This tailored configuration ensures improved results and better preservation of image details.
Modifications such as a significant increase in eye-opening or alterations in eye color become remarkably apparent when fidelity values are adjusted from low to high settings.

When addressing wide-shot images, using low-fidelity values often produces outcomes that are comparable to those obtained with high-fidelity values. In other words, the distinction between results achieved with low and high fidelity values is less pronounced in the context of wide-shot images.
Background
This parameter pertains to the augmentation of the background within the image. It plays a pivotal role in enhancing the visual aspects of the surroundings captured in the picture. By adjusting this parameter, various elements within the background can be emphasized, refined, or made more vivid, thereby contributing to an overall improvement in the image's depth, context, and aesthetic appeal.
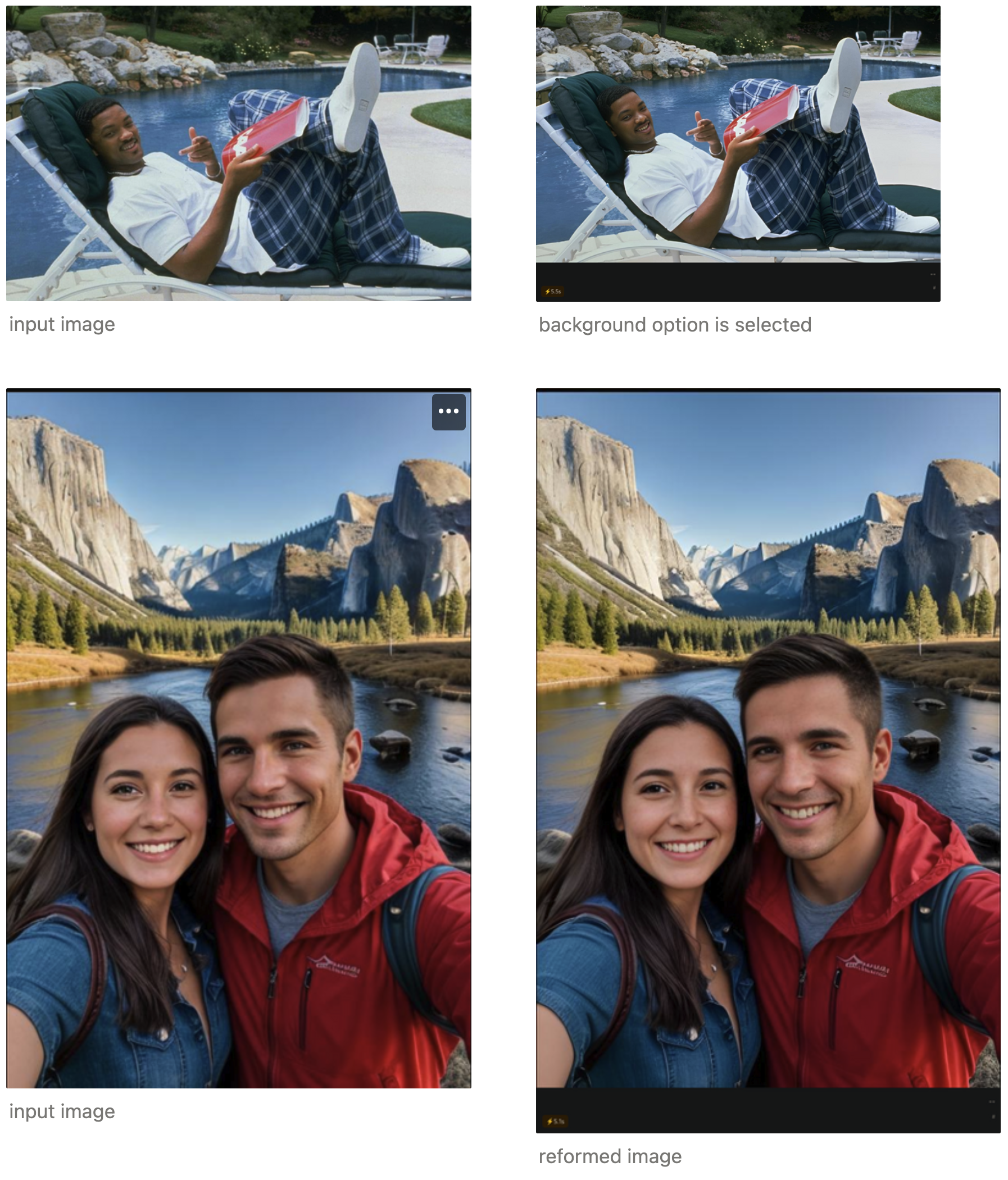
Opting for this choice is particularly advantageous when working with images that encompass a wide field of view or feature numerous subjects situated in the background.
In scenarios involving wide shots, selecting this option empowers you to extract more depth, clarity, and visual interest from the expansive backdrop, which inherently contains an extensive backdrop or multiple elements distributed across the rear portion of the composition.
Faces
This parameter encompasses the optimization of facial features within the image. Its primary focus lies in enhancing the visual aspects of the faces captured in the picture. By adjusting this parameter, various attributes of the faces, such as skin tones, expressions, and facial details, can be refined, accentuated, or improved to achieve more visually appealing and realistic results.
The ability to adjust this parameter provides the flexibility to cater to different requirements and artistic preferences. For example, you can enhance facial features to create portraits with a polished and flawless appearance or adjust them to retain a more natural and authentic look.
Investigating how the model responds to genuine versus AI-generated input images.

When confronted with AI-generated images, the CodeFormer model demonstrates exceptional proficiency, surpassing expectations and yielding outcomes of remarkable superiority. Its performance consistently yields results characterized by elevated texture quality and enhanced minutiae in detail. In doing so, the model consistently achieves a level of precision and fidelity that significantly outperforms alternatives, generating images that boast refined textures and exceptionally intricate details.

Yet, when confronted with real images, the model requires elevated fidelity values (greater than 0.6) and the activation of the face parameter (set to True) to produce satisfactory results. In this context, its performance is notably subpar and contributes to excessive skin smoothing, a phenomenon mentioned earlier in the article.
Consequently, when dealing with genuine images, precise parameter configuration emerges as a pivotal factor in mitigating the model's limitations and enhancing its output quality.
In summary, the CodeFormer model stands as a remarkable testament to the advancements achieved in the fields of blind face restoration and facial enhancement. When evaluating its application, the preference leans significantly toward using this model for AI-generated faces, as opposed to actual photographs.
The preference for AI-generated images is substantiated by the model's demonstrated excellence in generating enhanced and finely detailed visual content.