Best Open Source Text-To-Video AI Models
Looking for the best open source text-to-video AI models? Explore the top models, along with their key features, pros, and cons to find the best model for your needs.


Turning text into video is no longer science fiction. Open source text-to-video models are making it possible for anyone to create videos from simple text descriptions. These AI-powered tools are changing how we make content, opening up new ways to tell stories and share ideas.
In this guide, we'll look at the top open source text-to-video models available today. We'll break down how they work, what makes each one special, and help you pick the right one for your needs. So let’s get started!
Comparing The Best Open Source Text-To-Video Models
4 Best Open Source Text-To-Video Models
1. CogVideo - Best For High-Quality Video Generation
CogVideo is a powerful text-to-video generation AI model. It's built on transformer models, which are known for handling big data and complex tasks well. This model stands out for its ability to create high-quality videos from text descriptions.
Key Features:
- Text-to-Video Synthesis: Turns written descriptions into full videos, useful for many industries.
- High-Quality Output: Creates videos with sharp images and smooth movement.
- Scalability: Can work with large amounts of data, good for big projects.
- Versatility: Makes different types of videos, from realistic to cartoon-like.
CogVideo is unique because of its size and power. It has 9.4 billion parameters, which means it can understand and create very detailed videos. It's based on CogView2, a model that's good at making images from text. CogVideo takes this a step further by adding motion to create videos.
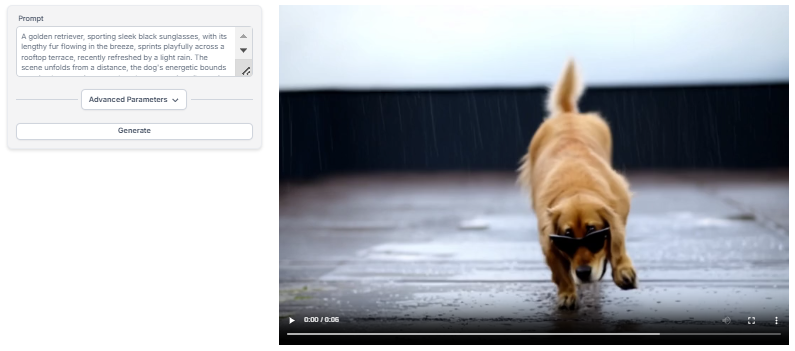
One of the coolest things about CogVideo is how it learns to make videos. It uses something called multi-frame-rate hierarchical training. This fancy term means it learns to make videos at different speeds, which helps it create more natural-looking motion.
CogVideo shines when you need to make high-quality videos for things like marketing, education, or entertainment. It's especially good for projects that need realistic or highly detailed videos. However, it does need a lot of computing power, so it might not be the best choice if you're just starting out or don't have access to powerful computers.
Best For: CogVideo is ideal for professional content creators, marketing teams, and researchers who need to produce high-quality, detailed videos from text descriptions. It's particularly suited for projects that require realistic animations or complex visual storytelling.
2. Text2Video-Zero - Best For Flexible Video Creation
Text2Video-Zero is a flexible tool that can create videos without needing to be trained on specific tasks. This makes it very adaptable and easy to use for different types of video projects.
Key Features:
- Zero-Shot Capability: Can make videos without special training for each task.
- Multiple Input Methods: Uses text, poses, or edges to guide video creation.
- Video Editing: Can change existing videos based on text instructions.
- Temporal Consistency: Makes sure the video flows smoothly from frame to frame.
What sets Text2Video-Zero apart is its ability to work with different types of input. You can give it just text, or you can add things like pose information or edge guidelines to get more control over the video. This makes it great for a wide range of projects.
The model is particularly good at following instructions. If you give it a detailed description, it tries hard to make a video that matches what you asked for. This is really helpful when you have a specific idea in mind.
Text2Video-Zero is also good at editing existing videos. You can give it a video and instructions on how to change it, and it will try to make those changes. This is useful for things like changing the style of a video or adding new elements to it.
While it's very flexible, the quality of Text2Video-Zero's output can vary depending on what you're asking it to do. It might not always give perfect results, especially for very complex or specific tasks. But for many projects, its flexibility makes it a great choice.
Best For: Text2Video-Zero is great for creative professionals, hobbyists, and small teams who need a versatile tool for various video projects. It's especially useful for those who want to experiment with different styles of video creation or need to do quick video edits based on text instructions.
3. Easy Animate - Best For Image-to-Video Animation
Easy Animate, developed by Alibaba PAI, is a tool that brings static images to life. It uses deep learning to turn still pictures into moving animations, making it a great choice for adding motion to existing images.
Key Features:
- Image-to-Video Conversion: Turns still images into animated videos.
- Customizable Settings: Lets you control things like video length and style.
- Multiple Animation Styles: Can create different types of animations.
- Prompt-Based Generation: Uses text descriptions to guide the animation process.
Easy Animate uses a combination of transformer models and convolutional neural networks (CNNs) to create smooth, realistic animations. It's designed to keep the movement looking natural from one frame to the next, which is important for making believable animations.
One of the coolest things about Easy Animate is how much control it gives you. You can set things like the number of frames, the frame rate, and even use a "negative prompt" to tell it what you don't want in the video. This level of customization is great for getting your animations just right.
The tool is particularly good at style transfer animations. This means you can take one image and animate it in the style of another, which is great for creative projects. It's also useful for research and development in video synthesis.
While Easy Animate is powerful, it does have some limitations. It works best with shorter video sequences, up to about 136 frames. This makes it better for creating short animations or looping gifs rather than longer videos.
Best For: Easy Animate is ideal for digital artists, social media content creators, and marketers who want to add motion to still images. It's particularly useful for creating eye-catching animations for social media posts, digital ads, or as part of larger video projects.
4. Stable Video Diffusion - Best For High-Quality Video Generation and Editing
Stable Video Diffusion (SVD) is a cutting-edge model that uses something called latent diffusion to create and edit videos. It's known for producing high-quality results and being efficient in how it processes data.
Key Features:
- AI-Driven Video Generation: Creates videos using advanced AI techniques.
- Video Upscaling: Can improve the quality of existing videos.
- Frame Rate Conversion: Changes how many frames per second a video has.
- Text-Based Video Creation: Makes new videos based on text descriptions.
SVD works by mapping video frames into what's called a latent space. This is a way of representing complex video data in a format that's easier for the AI to work with. By doing this, SVD can create very detailed and realistic videos.
One of the big advantages of SVD is its efficiency. It's designed to use computing resources wisely, which means you can get good results without needing super powerful computers. This makes it more accessible to a wider range of users.
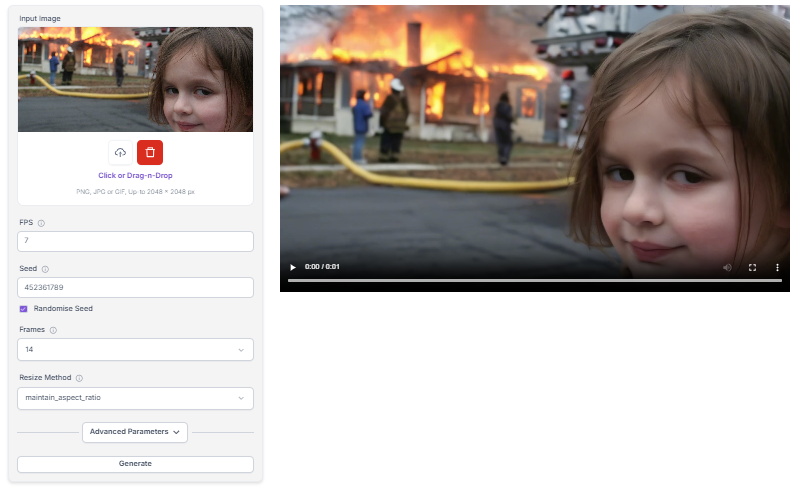
SVD is versatile in what it can do. It's not just for creating new videos from scratch. You can use it to improve the quality of existing videos, change how fast they play, or even edit videos based on text instructions. This makes it a powerful tool for video post-production work.
The model is particularly good at maintaining consistency across video frames. This means the videos it produces or edits look smooth and natural, without weird jumps or glitches between frames.
While SVD is powerful, it can still be complex to use, especially for beginners. It might take some time to learn how to get the best results from it. But for those willing to put in the effort, it offers a lot of control over video creation and editing.
Best For: Stable Video Diffusion is excellent for video professionals, content creators, and developers who need high-quality video generation and editing capabilities. It's particularly useful for projects that require detailed video manipulation, like improving old footage or creating complex visual effects.
What Are Open Source Text-To-Video Models?
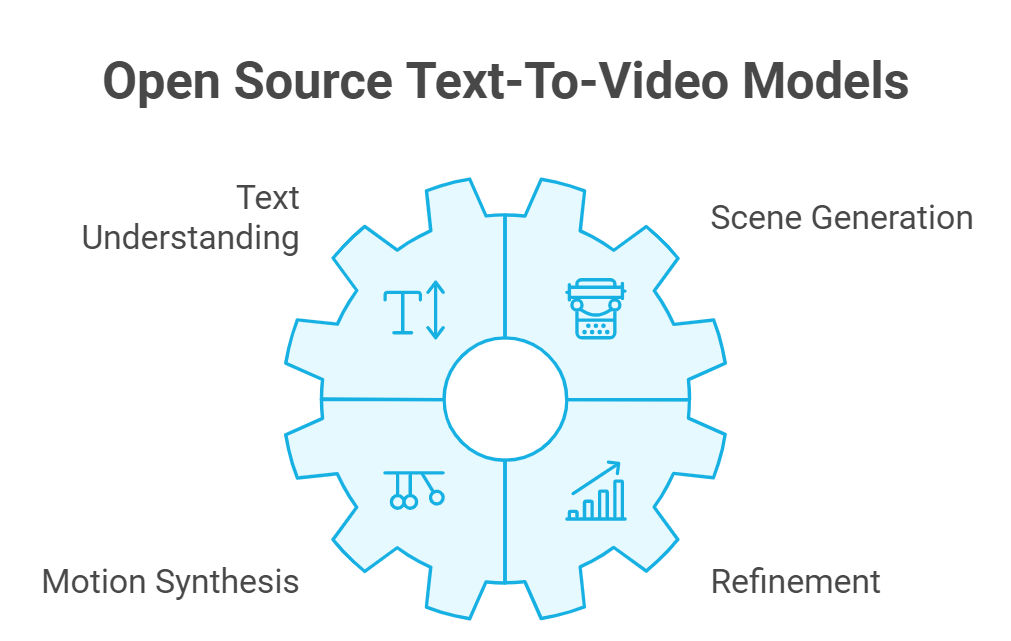
Open source text-to-video models are AI tools that turn written descriptions into video content. They use deep learning techniques to understand text and create matching visual scenes. These models learn from large datasets of text-video pairs to grasp the connection between words and visual elements.
The process typically involves several steps:
- Text Understanding: The model analyzes the input text to understand the content, style, and action described.
- Scene Generation: It creates a series of images or frames based on the text.
- Motion Synthesis: The model adds movement to connect the frames, creating fluid video content.
- Refinement: Final touches are added to improve quality and coherence.
These models use various AI techniques, including transformers, generative adversarial networks, and diffusion models. Each approach has its strengths, leading to different capabilities in video quality, style, and faithfulness to the text input.
Why Use Open Source Text-To-Video Models?
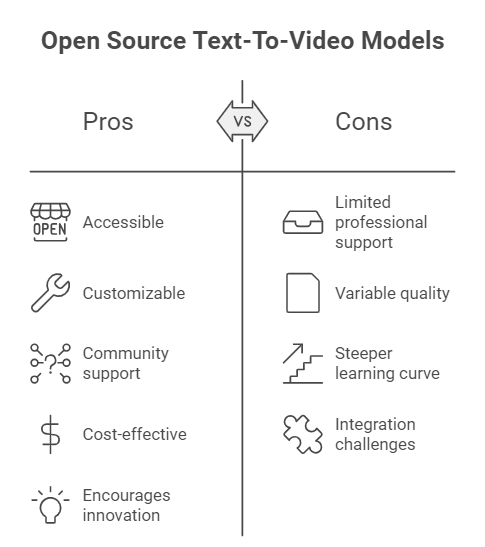
Open source text-to-video models offer several benefits:
- Accessibility: Anyone can use and modify these tools, making advanced video creation more accessible.
- Customization: Users can adapt the models to fit specific needs or integrate them into larger projects.
- Community Support: Open source projects often have active communities for support and improvement.
- Cost-Effective: Many of these tools are free to use, reducing the cost of video production.
- Innovation: Open source models encourage experimentation and advancement in AI video technology.
These models can save time and resources in video production, especially for tasks like creating educational content, marketing materials, or visual storytelling. They're also valuable for researchers and developers in the AI and multimedia space.
How To Choose The Right Open Source Text-To-Video Model?
Picking the right text-to-video model depends on your specific needs. Here's what to consider:
- Output Quality: Look at sample videos to assess the visual quality and realism.
- Ease of Use: Consider your technical skills. Some models are more user-friendly than others.
- Customization Options: Check if the model allows fine-tuning or style adjustments.
- Hardware Requirements: Ensure your computer can handle the model's processing needs.
- Specific Features: Look for capabilities that match your project, like style transfer or video editing.
- Community and Support: Active communities can provide help and resources.
- Integration: If you're a developer, consider how easily the model integrates with your existing tools.
Test different models with similar inputs to compare results. Start with simpler tasks and gradually try more complex ones to understand each model's strengths and limitations.
Final Thoughts
Open source text-to-video models are powerful tools that are changing how we create visual content. From CogVideo's high-quality output to Text2Video-Zero's flexibility, each model offers unique strengths. Easy Animate makes bringing still images to life simple, while Stable Video Diffusion provides advanced editing capabilities.
As you explore these tools, remember that the best choice depends on your specific needs and skills. Whether you're a content creator, developer, or just curious about AI, these models offer exciting possibilities for turning text into engaging videos.
Want to explore more about AI-powered content creation? Explore Segmind's PixelFlow platform! With it you can create custom workflows using a wide range of AI models, offering more control and customization with an easy-to-use interface.