Amazon outperforms GPT-3.5 by 16%
Amazon outperforms GPT-3.5 by 16%


Amazon's model, trained with 1 billion parameters, has surpassed the previous state-of-the-art LLM (#GPT-3.5) by 16%, achieving a remarkable accuracy rate of 91.68% compared to the GPT's rate of 75.17%.
Study: https://lnkd.in/g2Xn446256434259.5K
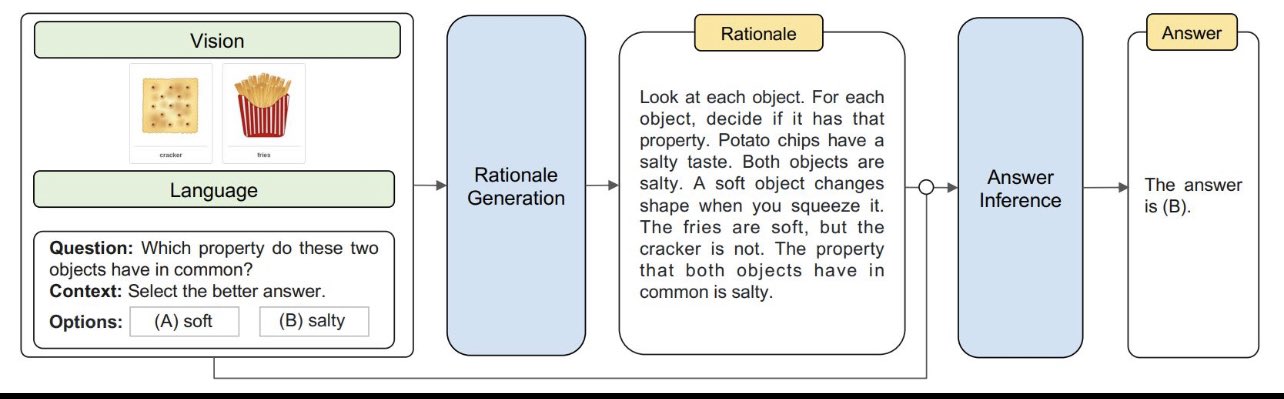
This impressive feat was achieved by generating intermediate reasoning steps for prompting demonstrations, also known as chain-of-thought (#CoT) prompting.
The model is enhanced with an additional layer that enables it to produce more insightful rationales and answers based on a broader range of knowledge. The study, code, and datasets are publicly available:
Code: https://lnkd.in/gJ7BxVJJ
Datasets: https://lnkd.in/gdp6NF9k#llm
Instructions To Get Started
 amazon-science
amazon-science
Training
# rationale generation
CUDA_VISIBLE_DEVICES=0,1 python main.py \
--model allenai/unifiedqa-t5-base \
--user_msg rationale --img_type detr \
--bs 8 --eval_bs 4 --eval_acc 10 --output_len 512 \
--final_eval --prompt_format QCM-LE
# answer inference
CUDA_VISIBLE_DEVICES=0,1 python main.py \
--model allenai/unifiedqa-t5-base \
--user_msg answer --img_type detr \
--bs 8 --eval_bs 4 --eval_acc 10 --output_len 64 \
--final_eval --prompt_format QCMG-A \
--eval_le experiments/rationale_allenai-unifiedqa-t5-base_detr_QCM-LE_lr5e-05_bs16_op512_ep20/predictions_ans_eval.json \
--test_le experiments/rationale_allenai-unifiedqa-t5-base_detr_QCM-LE_lr5e-05_bs16_op512_ep20/predictions_ans_test.json
Inference
Our trained models are available at models. To use trained models, please put the them under the models folder.
# rationale generation
CUDA_VISIBLE_DEVICES=0,1 python main.py \
--model allenai/unifiedqa-t5-base \
--user_msg rationale --img_type detr \
--bs 8 --eval_bs 4 --eval_acc 10 --output_len 512 \
--final_eval --prompt_format QCM-LE \
--evaluate_dir models/MM-CoT-UnifiedQA-base-Rationale
# answer inference
CUDA_VISIBLE_DEVICES=0,1 python main.py \
--model allenai/unifiedqa-t5-base \
--user_msg answer --img_type detr \
--bs 8 --eval_bs 4 --eval_acc 10 --output_len 64 \
--final_eval --prompt_format QCMG-A \
--eval_le models/rationale/predictions_ans_eval.json \
--test_le models/rationale/predictions_ans_test.json \
--evaluate_dir models/MM-CoT-UnifiedQA-base-Answer