SSD-1B Img2Img: Diving Deep into the Model
A comprehensive guide to maximizing the potential of the SSD-1B Img2Img model in image generation.


The Segmind Stable Diffusion 1B (SSD-1B) Img2Img model based on SSD-1B, represents a cutting-edge advancement in the domain of image-to-image transformation. This AI model harnesses sophisticated machine learning techniques to revolutionize the way we interact with visual content.
In practical terms, Img2Img takes an original image and undergoes a transformative process using Stable Diffusion. This capability opens up exciting possibilities, making it ideal for tasks such as remixing existing photos or adjusting them to align with one's creative vision. Primarily designed to cater to the needs of creatives, marketers, and software developers, SSD-1B Img2Img stands out as a pivotal tool for those seeking innovation in visual content creation.
Under the hood
- Input Preparation: Stable Diffusion processes an input image with added noise, treating the noise-laden image as if it represents an obscured original artwork.
- Text Prompt Guidance: The model uses a provided text prompt as "hints" to recover the intended image, gradually removing noise over multiple steps (e.g., 50).
- Img2Img Technique: In img2img, a real image is concealed beneath noise, prompting Stable Diffusion to "recover" an output closer to the provided image.
- Image/Noise Strength Parameter: A parameter (0.0-1.0) controls how closely the output resembles the input by determining the percentage of noise steps added to the image during processing.
Just upload an input image, craft an amazing prompt and explore the advanced settings: HIT THE GENERATE BUTTON and see the magic!!
Understanding the Advanced Settings
Throughout this article, we'll be using the following input image to explore and test different settings.

1. Negative Prompt
A negative prompt is a parameter that tells an AI model what not to include in the generated image. Negative prompts can help prevent the generation of strange images. They can also improve the image output by specifying abstract concepts such as “blurry” and “pixelated”
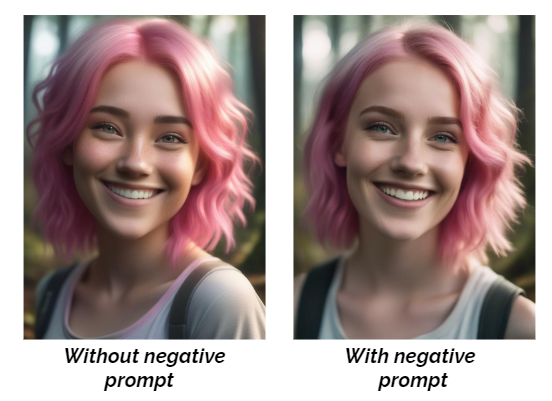
Given Prompt: young woman, pink hair, casual clothing, whimsical expression, fantasy forest setting, soft magical lighting, full body, DSLR, 8K, 4K, ultra realistic, ethereal skin texture
2. Inference Steps
It indicates the number of denoising steps, where the model iteratively refines an image generated from random noise derived from a text input. With each step, the model removes some noise, leading to a progressive enhancement in the quality of the generated image. A greater number of steps correlates with the production of higher-quality images.

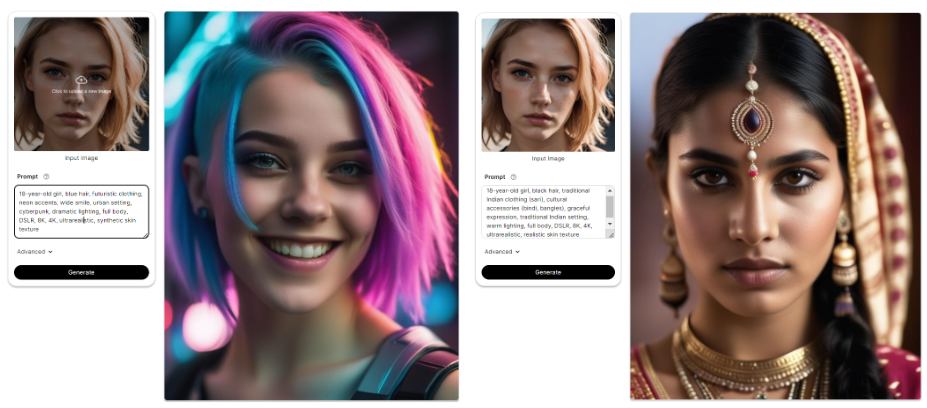
Given Prompt: 18-year-old girl, blue hair, futuristic clothing, neon accents, confident expression, urban setting, cyberpunk, dramatic lighting, full body, DSLR, 8K, 4K, ultra realistic, synthetic skin texture
3. Strength Scale
The CFG scale (classifier-free guidance scale) or guidance scale is a parameter that controls how much the image generation process follows the text prompt. The higher the value, the more the image sticks to a given text input.

Given Prompt: 18-year-old girl, black hair, traditional Indian clothing (sari), cultural accessories (bindi, bangles), graceful expression, traditional Indian setting, warm lighting, full body, DSLR, 8K, 4K, ultra realistic, realistic skin texture
4. Seed
The seed is a starting point for the random number generator, influencing the initialization of model parameters during training or generation. Setting a specific seed ensures reproducibility, as it initializes the model in the same way for each run, leading to consistent and predictable results.
Interacting with model via API
You also have the option to utilize the SSD-1B Img2Img through an API. This flexibility allows you to seamlessly integrate it into your workflow using languages like Bash, Python, and JavaScript. You can see the sample code at Segmind Img2Img
Some More Examples



Summary
SSD-1B Img2Img is an innovative image-to-image transformation model, designed for creatives and developers seeking cutting-edge visual content creation. Underlying its functionality is Stable Diffusion, which processes images with added noise and refines them using text prompts. Advanced settings such as negative prompts, inference steps, strength scale, and seed offer users a versatile toolkit for customized image generation.
The model's API further enhances flexibility, allowing seamless integration into workflows using popular programming languages. By exploring provided examples and colab code, users can harness the power of SSD-1B Img2Img to transform images with precision and creativity.