Introducing Segmind Vega: Compact model for Real-time Text-To-Image
Segmind has introduced two new open-source text-to-image models, Segmind-VegaRT (Real Time) and Segmind-Vega, the fastest and smallest, open source models for image generation at the highest resolution.


Today, we are releasing our Vega series of models; Segmind-Vega and VegaRT. Segmind VegaRT (Real-Time) is the world’s fastest image generation model, achieving an unprecedented 0.1s per image generated at 1024x1024 resolution. The Vega and VegaRT models are our attempt to make compact and more efficient models and are smaller in size than Stable Diffusion 1.5. The best part, these models can be used commercially.
The Segmind Vega Model is a distilled version of the Stable Diffusion XL (SDXL), offering a remarkable 70% reduction in size and an impressive 100% speedup while retaining high-quality text-to-image generation capabilities.
Segmind VegaRT is a distilled LCM-LoRA adapter for the Vega model, that allowed us to reduce the number of inference steps required to generate a good quality image to somewhere between 2 - 8 steps, helping us generate an image in under 0.1s on a Nvidia A100. Latent Consistency Model (LCM) LoRA was proposed in LCM-LoRA: A universal Stable-Diffusion Acceleration Module by Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu et al.



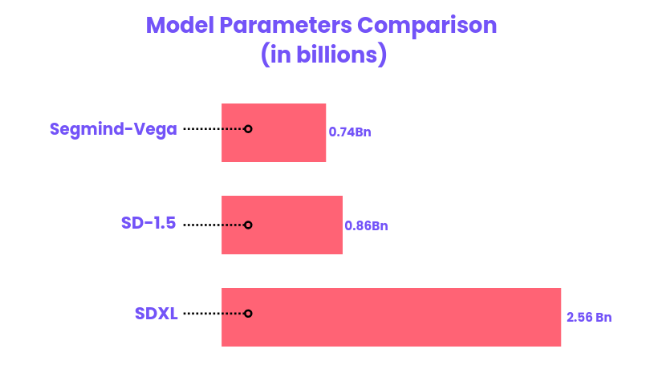
Parameters (UNet) Comparison
Segmind Vega marks a significant milestone in the realm of text-to-image models, setting new standards for efficiency and speed. Engineered with a compact yet powerful design, it boasts only 745 million parameters. This streamlined architecture not only makes it the smallest in its class but also ensures lightning-fast performance, surpassing the capabilities of its predecessors. You can read more about the model architecture below.
Vega represents a breakthrough in model optimization. Its compact size, compared to the 859 million parameters of the SD 1.5 and the hefty 2.6 billion parameters of SDXL, maintains a commendable balance between size and performance. Vega's ability to deliver high-quality images rapidly makes it a game-changer in the field, offering an unparalleled blend of speed, efficiency, and precision.
Latency Comparison
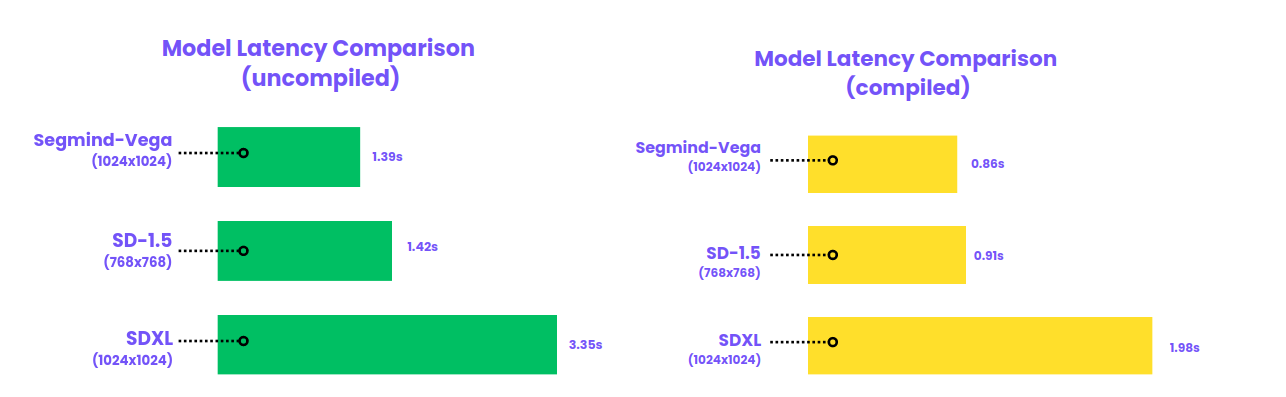
The latency comparison chart provided illustrates a clear distinction in performance among the SDXL, SD1.5, and Segmind Vega models, tested on Nvidia A100 80GB GPUs. In the realm of uncompiled model latency, Vega demonstrates a notable lead with a latency of just 1.39 seconds for generating 1024x1024 resolution images. This contrasts sharply with SDXL, which shows a latency of 3.35 seconds at the same resolution, and SD1.5, which has a latency of 1.42 seconds but for a smaller image resolution of 768x768.
When it comes to compiled model latency, the efficiency of Segmind Vega becomes even more pronounced. Vega's compiled latency is recorded at a mere 0.86 seconds, significantly faster than both the SD1.5 and SDXL models, which clock in at 0.91 seconds and 1.98 seconds, respectively. The fact that Vega maintains this performance advantage while generating images at a higher resolution than SD1.5 underscores its optimized performance capabilities, making it a formidable choice for applications where speed is of the essence.
Model Architecture
Segmind Vega is a symmetrical, distilled version of the SDXL model; it is over 70% smaller and 100% faster. The Down Block contains 247 million parameters, the Mid Block has 31 million, and the Up Block has 460 million. Apart from the size difference, the architecture is virtually identical to that of SDXL, ensuring compatibility with existing interfaces requiring no or minimal adjustments. Although smaller than the SD1.5 Model, Vega supports higher-resolution generation due to the SDXL architecture, making it an ideal replacement for SD1.5. More details of the architecture will be released in subsequent blogs and a technical paper.

Limitations
This model is the first base model showing real-time capabilities at higher image resolutions, but has its own limitations;
- The model is good at close-up portrait images of humans but tends to do poorly on full-body images. Full body images may show deformed limbs and faces.
- This model is an LCM-LoRA model, so negative prompt and guidance scale parameters would not be applicable.
- Since it is a small model with a low parameter count, the variability of the images tends to be low and hence may be best used for specific use cases when fine-tuned.
We will be releasing more fine-tuned versions of this model to improve upon these specified limitations.
License
The Segmind Vega and VegaRT models are licensed under the Apache 2.0 license. This decision reflects our commitment to open-source development, and by making these models freely available, we hope to encourage others to build upon our work and contribute to their development. We encourage everyone, including our valued competitors, to explore these models and contribute to their evolution for the benefit of the entire AI community.
Use Segmind Vega Models with Segmind APIs
The fastest way to get started with these models is through our serverless APIs. Sign up today to take advantage of the free 100 credits per day to try the models for free. Beyond the free limits, these API endpoints are priced per image generation and are significantly cheaper compared to many stable diffusion APIs. Our serverless APIs are a great option for quickly prototyping AI-powered features.
If you want to start using Segmind Vega and VegaRT in production, there are several ways to customize and deploy it using the Segmind Platform.
- Segmind Training: Customize Segmind Vega and VegaRT using your private data via fine-tuning, domain-specific pre-training, or training from scratch. You always own the final model weights, and your data is never stored on our platform. Pricing is per GPU minute. Contact us for more information.
- Segmind Inference: Use our hosted serverless API endpoints for Segmind Vega and Segmind VegaRT .
We are so excited to see what our community and customers build next with our new models. Experience the real-time generations here.