How LoRA makes Stable Diffusion smarter
LoRA, or Low-Rank Adaptation, is a novel method to train large language models more efficiently. Learn more about Lora, its applications and the future of this technique.


Well, things are moving really fast in the generative AI space. However, the same cannot be said for the training and inference speeds of these generative AI models. Despite a multitude of novel use cases and applications – primarily driven by a number of open-source models – transitioning these models to real tasks at scale is being slowed down due to costs and time associated with running these models in production environments.
There is a concerted effort to make the training and inference of these models faster, enabling their application across a wide range of industries. On one hand, hardware companies are striving to create more powerful computing machines, tailored specifically for operating these models. On the other hand, innovative techniques are being explored to minimize the computing power required, by rethinking how we train and deploy these models.
Enter Low-Rank Adaptation (LoRA), a groundbreaking method designed to mitigate these challenges. LoRA takes a unique approach to the adaptation of large-scale pre-trained language models. It functions by freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the transformer architecture. This innovative technique significantly reduces the number of trainable parameters, leading to improved efficiency in both the training and inference phases. With LoRA, the integration of AI models into real-world tasks can be executed at scale, offering promising solutions to existing bottlenecks in the deployment of generative AI models.
How does LoRA work?
LoRA, or Low-Rank Adaptation, is a novel method to train large language models more efficiently. Instead of retraining all parameters of a model, LoRA introduces trainable rank decomposition matrices into each layer of a model's architecture, while keeping the pre-trained model weights frozen. This greatly reduces the number of trainable parameters for downstream tasks, leading to a substantial decrease in GPU memory requirements and overall cost, without sacrificing model performance.
To simplify things, let's imagine these models as a big, complex Lego castle. Now, suppose you want to change something about this castle - say you want to add a new tower. Normally, you would have to carefully take apart and rebuild large parts of the castle, which could take a long time and be quite difficult.
Now, imagine if you could just remove a few Lego bricks and stick a few new Lego bricks here and there to make your changes. You wouldn't have to touch the rest of the castle at all. This would be much easier and quicker, right?
This is what LoRA (Low-Rank Adaptation) does for big models. Instead of having to learn (or "rebuild") everything, it only learns a few key parts (or "adds a few Lego bricks") to adapt the model to a new task. This makes the whole process a lot quicker and more efficient, just like adding a few bricks to your Lego castle is easier than rebuilding the whole thing.
In a technical sense, the method adds pairs of rank-decomposition weight matrices known as update matrices, to the existing model weights and only trains these new matrices. As a result, the model avoids catastrophic forgetting due to the frozen pre-trained weights and the trained LoRA weights are easily portable. Typically, these LoRA matrices are added to the attention layers of the model. LoRA has been proven effective and efficient for different models, and its memory efficiency allows fine-tuning to be done on readily available consumer GPUs.
Integration of LoRA into Stable Diffusion Models
The stable diffusion model has been widely utilized for fine-tuning and generating high-fidelity images for a range of use cases. However, the process can be slow, and achieving a balance between the number of steps and the quality of results is challenging. Moreover, the fully fine-tuned model can be large, leading some to use textual inversion, which only creates a small word embedding and compromises image quality. In this context, Low-Rank Adaptation (LoRA) presents an attractive alternative.
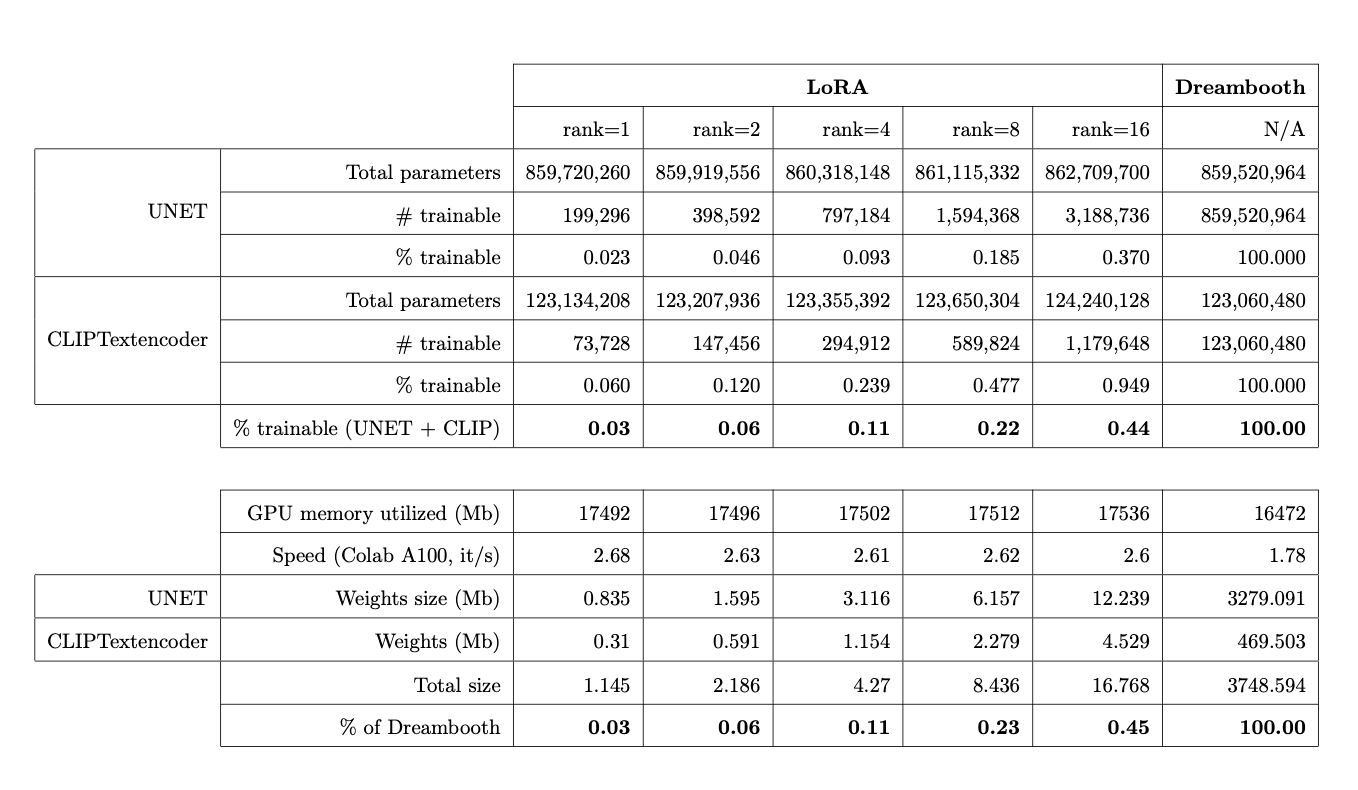
LoRA method focuses on fine-tuning the "residual" of the model rather than the entire model, leveraging the decomposition of the residual into low-rank matrices. Not all parameters need tuning, often, only the cross-attention layer of the transformer model requires it. This layer, where the prompt and the image meet, seems to have a huge impact on the image quality. Thanks to the LoRA technique, the number of trainable parameters is reduced, which means that the GPU requirements are also less. As a result, you get a lower-size model that is quicker to train.
This allows anyone with consumer graphic cards to train their own models. There are thousands of LoRA models already available on Hugginface and other model repository platforms. You can also combine different LoRA styles which can be useful when you want to merge different styles or apply a specific style to a particular character.
Future of LoRA
LoRA has opened up a huge set of possibilities, especially for Stable Diffusion use cases. Thousands of model creators are now able to train custom models for their choice of style and use case. An improved technique, Generalised Low-Rank Adaptation (GLoRA) represents an advanced approach to universal, parameter-efficient fine-tuning tasks. Expanding upon the foundation laid by Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module that optimizes pre-trained model weights and adjusts intermediate activations. This offers increased flexibility and capability across a variety of tasks and datasets. GLoRA further facilitates efficient parameter adaptation by using a scalable, modular, layer-wise structure search that learns individual adapters for each layer. Originating from a unified mathematical formulation, GLoRA is adept at adjusting to new tasks through additional dimensions on weights and activations.
The improvements and benefits that GLoRA offers are significant. Compared to previous methods, GLoRA has been found to outperform in natural, specialized, and structured benchmarks, achieving superior accuracy with fewer parameters and computations on various datasets. This method presents a practical solution for navigating the complexity of integrating all adjustable dimensions and possibilities when tuning a pre-trained network. Moreover, GLoRA's structural re-parameterization design ensures that it incurs no extra inference cost, making it a particularly suitable choice for resource-limited applications. Furthermore, GLoRA's flexible, parameter-efficient fine-tuning scheme accommodates the unique characteristics of diverse downstream datasets, improving adaptability and performance in various data-driven tasks.
In conclusion, Low-Rank Adaptation (LoRA) techniques and their generalized versions, such as GLoRA, are revolutionizing the way we use large-scale pre-trained models. These techniques bring about a substantial reduction in the number of trainable parameters, thereby simplifying the process of model fine-tuning. By introducing adaptable layers to optimize pre-trained weights and adjust intermediate activations, these methods significantly enhance the models' adaptability to diverse tasks and datasets. The structural re-parameterization design of GLoRA, in particular, ensures no additional inference costs, making these techniques more resource-efficient. Hence, LoRA and its derivatives are not only democratizing the use of advanced AI models by making them more accessible and efficient, but they are also paving the way for improved performance across a broad range of data-driven applications.
If you'd like to experience the power of Stable Diffusion firsthand, give our free models a spin and experience the magic yourself.