Announcing SSD-1B: A Leap in Efficient T2I Generation
Segmind has introduced the revolutionary SSD-1B, an open-source text-to-image model, outperforming previous versions by being 50% smaller and 60% faster than SDXL.


Today, Segmind is thrilled to announce the open sourcing of our new foundational model, SSD-1B, the fastest diffusion-based text-to-image model in the market, with unprecedented image generation times for a 1024x1024 image. Developed as part of our distillation series, SSD-1B is 50% smaller and 60% faster compared to the SDXL 1.0 model. This reduction in speed and size comes with a minimal impact on image quality when compared to SDXL 1.0. Furthermore, we are excited to reveal that the SSD-1B model has been licensed for commercial use, opening avenues for businesses and developers to integrate this groundbreaking technology into their services and products.
If you are looking to use SSD-1B in production for training or inferencing, click here.

Preface
Since the introduction of Stable Diffusion 1.5 by StabilityAI, the ML community has eagerly embraced the open-source model. In August, we introduced the 'Segmind Distilled Stable Diffusion' series with the compact SD-Small and SD-Tiny models. We open-sourced the weights and code for distillation training, and the models were inspired by groundbreaking research presented in the paper "On Architectural Compression of Text-to-Image Diffusion Models". These models had 35% and 55% fewer parameters than the base model, respectively, while maintaining comparable image fidelity.
With the introduction of SDXL 1.0 in July, we saw the community moving to the new architecture due to it's superior image quality and better prompt coherence. In our effort to make generative AI models faster and more affordable, we began working on a distilled version of SDXL 1.0. We were successful in distilling the SDXL 1.0 to half it's size. Read on to learn more about our SSD-1B model.
Key Features
Designed for Speed
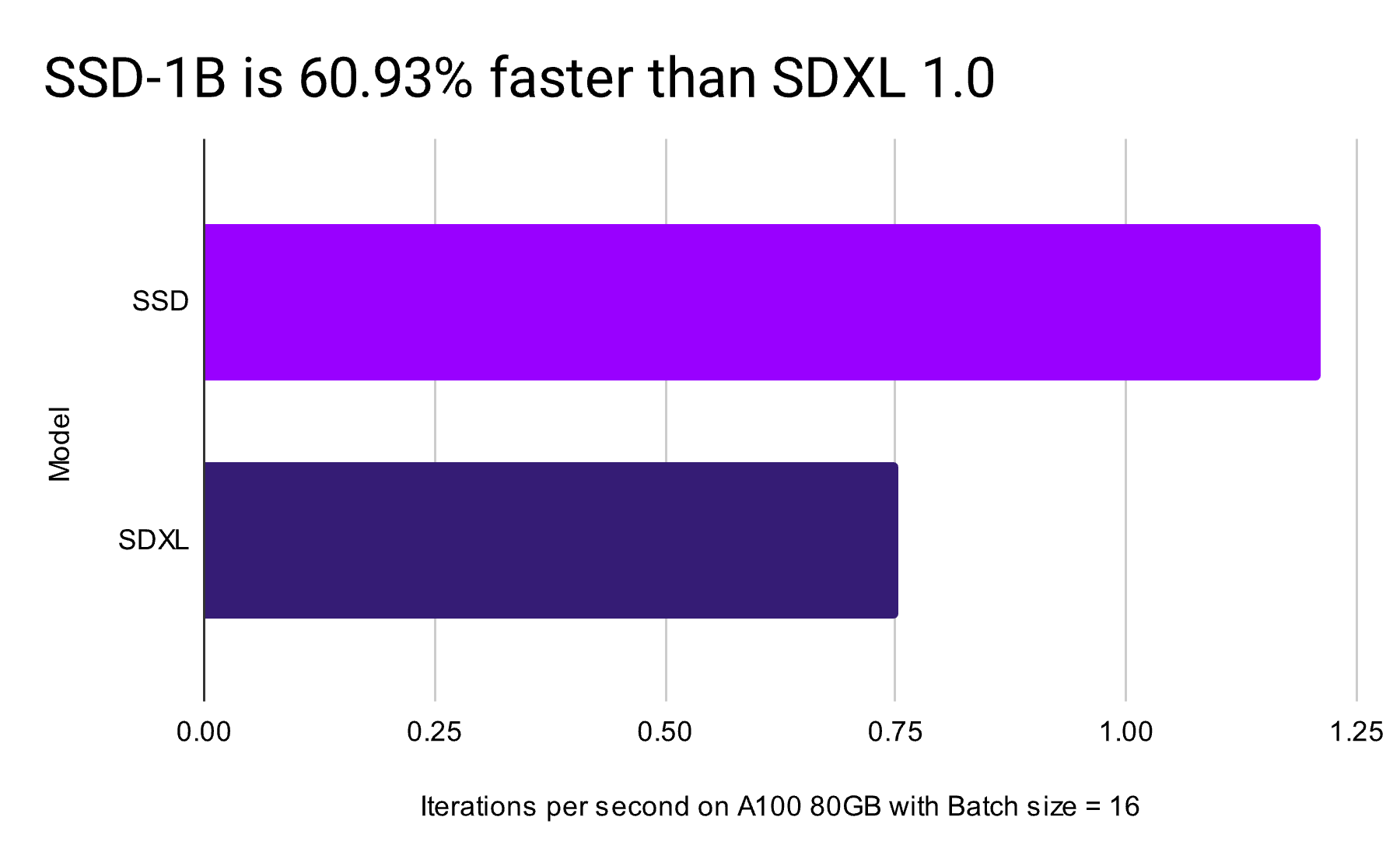
This model has been meticulously engineered with a strong focus on speed and efficiency. It delivers a remarkable 60% speed up in inference and fine-tuning, rendering it an ideal choice for real-time applications and situations where swift image generation is a critical requirement. Using the Nvidia TRT optimizer, the model provides even greater performance gains, operating at 72% higher inference speed compared to the SDXL base model.
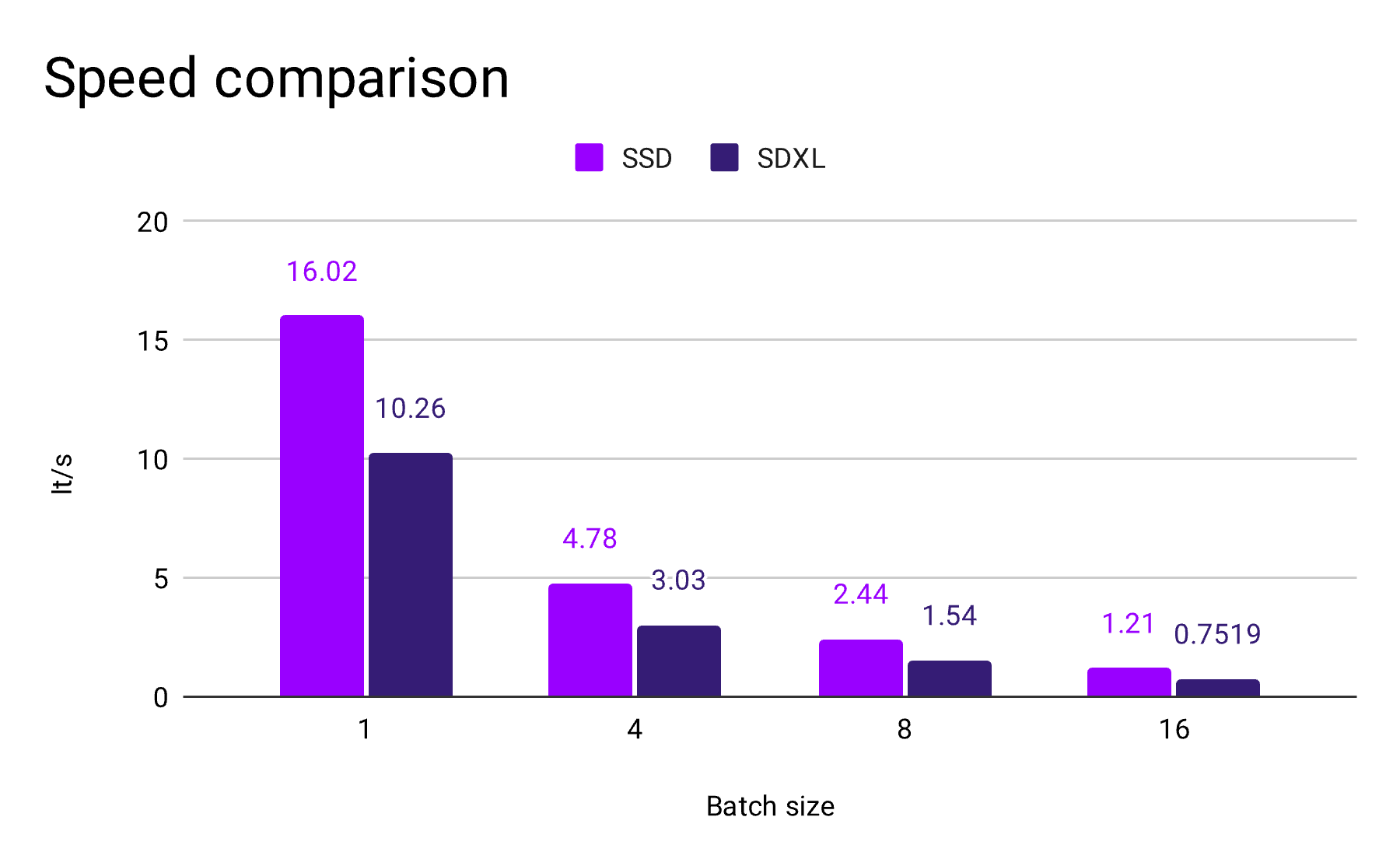
A comparative analysis of iterations per second (It/s) on Nvidia A100 (80GB) across various batch sizes highlights the SSD-1B's superior efficiency. At a single-unit batch size, the SSD-1B model boasts a remarkable 16.02 It/s, a staggering 56% speed increase compared to the SDXL's 10.26 It/s. This trend of enhanced performance is consistent across larger batch sizes – at four units, the SSD operates at 4.78 It/s, eclipsing the SDXL's 3.03 It/s. Even as batch sizes expand to eight and sixteen, the SSD model sustains it's lead with 2.44 and 1.21 It/s, respectively, demonstrating not only resilience to increased workload but also a consistent performance threshold. In contrast, the SDXL's throughput diminishes to 1.54 and 0.7519 It/s under the same conditions.
Enhanced Compactness
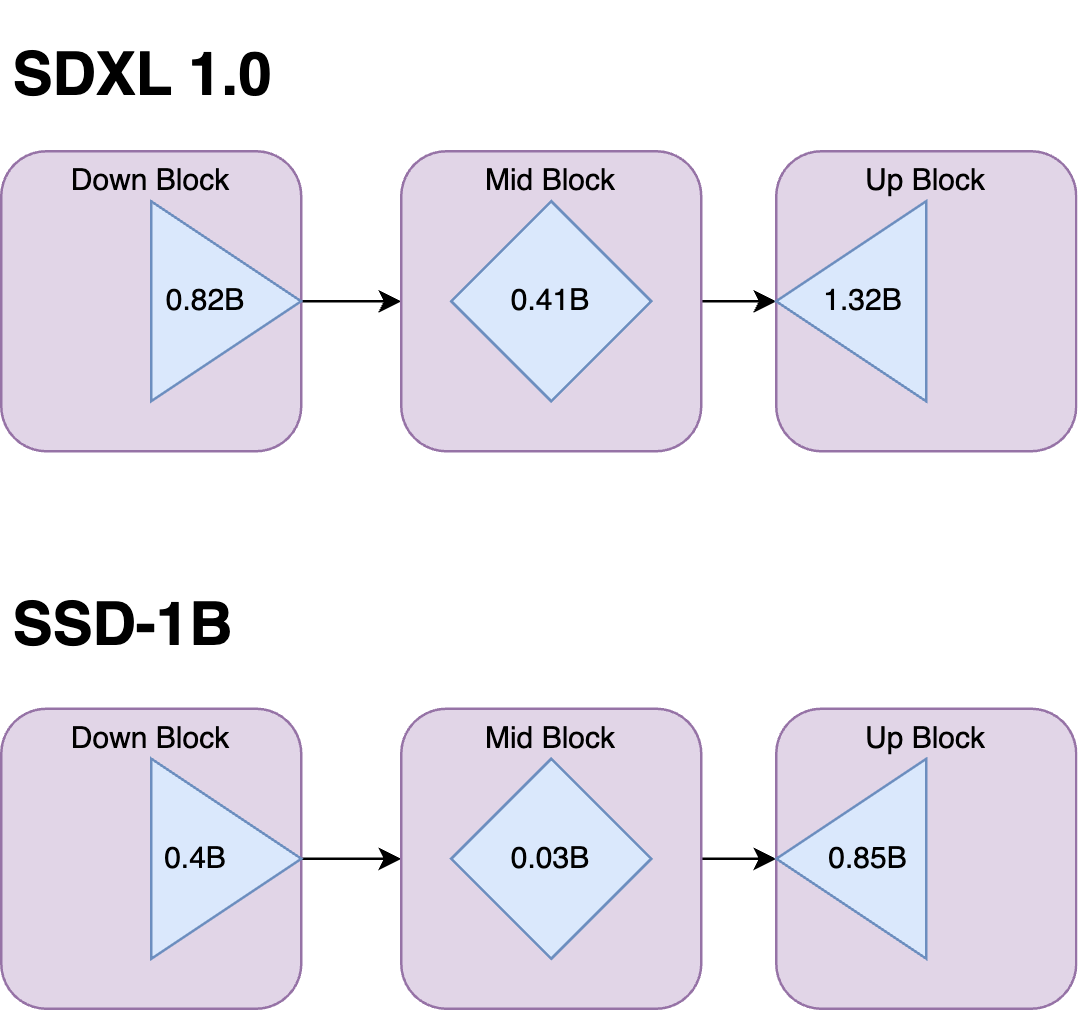
SSD-1B is 50 percent more compact compared to SDXL, making it easier to deploy and utilize in various systems and platforms without sacrificing performance. It is a 1.3 B parameter model where several layers have been removed from the base SDXL model.
To reduce the size of the model, we primarily removed the transformer blocks inside the Attention Layers, we did not observe any significant loss in quality due to this removal. We also removed the Attention and a Resnet layer inside the mid-block since it has been shown to not have much impact on quality. We progressively distilled the Unet block by making it shorter in each stage and then training it. In total, we removed 40 transformer blocks and 1 Resnet block.
When the ML models were idle, yet loaded onto the GPU, the VRAM consumption stood at 7,810 MB for SDXL and 5,338 MB for the SSD model. When the models were performing inference tasks the VRAM consumption for the SDXL model rose to 15,214 MB, whereas the SSD models required 12,780 MB. It's worth noting that simply in the context of VRAM utilization, using the SSD algorithm could save you up to 2,434 MB during inference when compared to SDXL models.
Training
This model employs a knowledge distillation strategy, where it leverages the teachings of several expert models in succession, including SDXL 1.0, ZavyChromaXL, and JuggernautXL, to combine their strengths and produce impressive images. This model training also included data from a variety of datasets, including GRIT and Midjourney scrape data. A total of around 15 million data points (image-prompt pairs) were used during the training process. This diverse training data equips SSD-1B with enhanced capabilities to generate a wide spectrum of visual content based on textual prompts.
Here are the following parameters used to train the model.
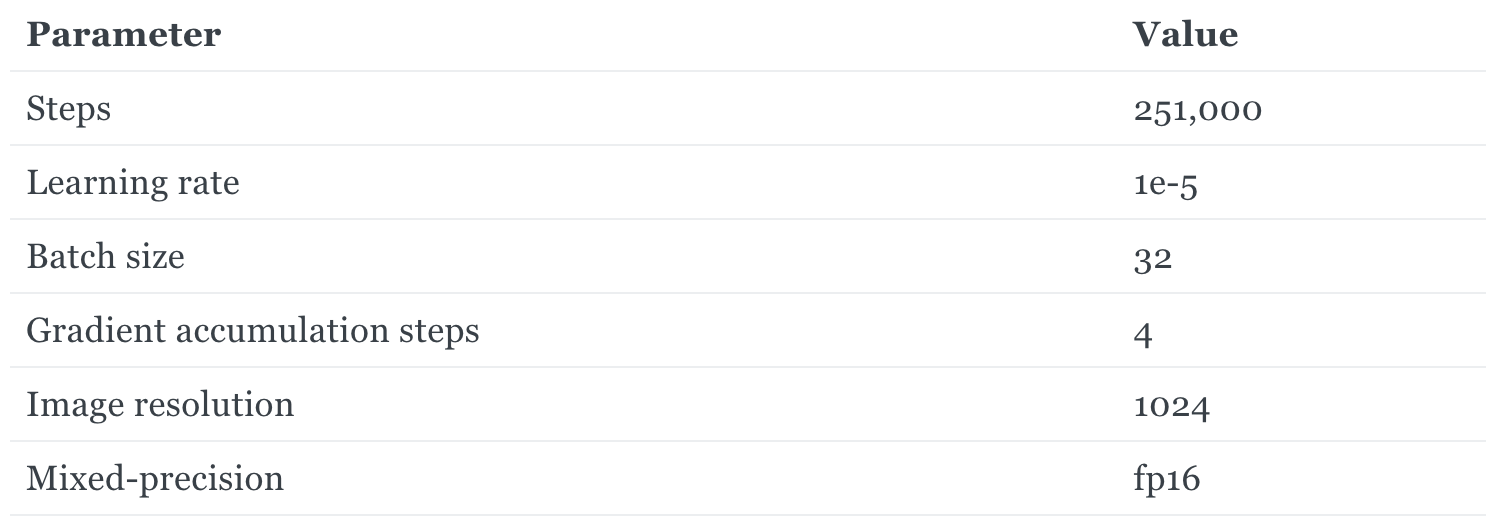
The model was trained on approximately 200 hours of 4x A100 80GB GPU hours.
Customize SSD-1B with Segmind Training
SSD-1B comes with strong generation abilities out of the box, but for the best performance on your specific task, we recommend fine-tuning the model on your private data. This process can be done in hours for as little as a few hundred dollars.
Fine-tune code
The Segmind Stable Diffusion Model can also be used directly with the HuggingFace Diffusers library training scripts for further training, including: Fine-Tune, LoRA, and Dreambooth LoRA.
To make training SSD-1B models as easy as possible, we’ve open-sourced our code for fine-tuning and LoRA training. Lora trains only about 1% of parameters whereas fine-tuning will train all the parameters.
Use SSD-1B with Segmind APIs
The fastest way to get started with this is through are serverless API. Sign up today and take advantage of the free credits. Beyond the free limits, these API endpoints are priced per image generation and are significantly cheaper compared to many Stable Diffusion APIs. Our serverless APIs are a great option for quickly prototyping AI-powered features.
If you want to start using SSD-1B in production, there are several ways to customize and deploy it using the Segmind Platform.
- Segmind Training: Customize SSD-1B using your private data via fine-tuning, domain-specific pre-training, or training from scratch. You always own the final model weights, and your data is never stored on our platform. Pricing is per GPU minute. Contact us for more information.
- Segmind Inference: Use our hosted serverless API endpoints for SSD-1B.
We are so excited to see what our community and customers build next with SSD-1B.
Image Showcase
SSD-1B's image outputs frequently match or even exceed those of the base SDXL in quality. Like SDXL, SSD-1B effortlessly generates images in various styles. Below is a showcase of sample images representing different styles.
Photorealist Style



Lowpoly Style



Isometric Style



Origami Style



Sticker Style



Anime Style



Craft Clay Style



Line Art Style



Water Color Style



Neon Punk Style



Limitations & Bias
The SSD-1B Model has some challenges in embodying absolute photo-realism, especially in human depictions. While it grapples with incorporating clear text and maintaining the fidelity of complex compositions due to it's auto-encoding approach, these hurdles pave the way for future enhancements. Importantly, the model's exposure to a diverse dataset, though not a panacea for ingrained societal and digital biases, represents a foundational step towards more equitable technology. Users are encouraged to interact with this pioneering tool with an understanding of it's current limitations, fostering an environment of conscious engagement and anticipation for it's continued evolution.
Acknowledgment
Special thanks to the HuggingFace team 🤗 especially Sayak, Patrick and Poli for their collaboration and guidance on this work. Shout out to Yatharth Gupta and Vishnu Jaddipal for driving this project over the past few months.