How to Optimize ControlNet Softedge Performance: A Comprehensive Guide
Dive into the world of ControlNet Softedge with our detailed guide. We'll walk you through the best settings and tweaks to ensure peak performance.


We will take a look at the best parameters that can be set for ControlNet SoftEdge. ControlNet Softedge helps in highlighting the essential features of the input image. At its core, ControlNet SoftEdge is used to condition the diffusion model with SoftEdges. We will proceed to take a look at the architecture of ControlNet and later dive into the best parameters that help in improving the quality of outputs.
ControlNet SoftEdge Architecture:
The ControlNet architecture employs a unique method known as "zero convolutions" to capture a broad spectrum of conditional controls. This involves initializing convolution layers with zeros.
As these layers gradually develop parameters from zero, they establish a controlled and noise-free environment during fine-tuning. This innovative approach acts as a safeguard against noise, preserving the integrity of the pre-trained model. Notably, it enables the seamless integration of spatial conditioning controls into the overall model structure.
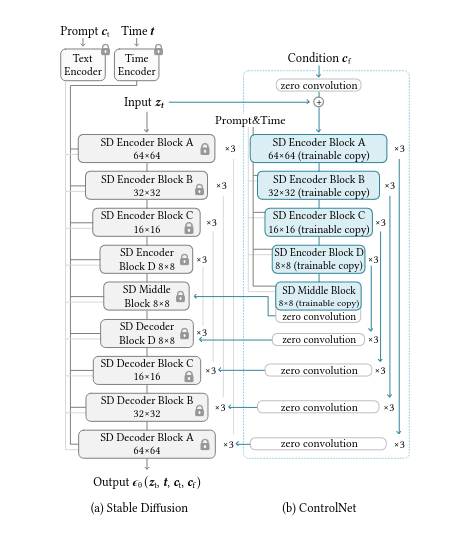
Now you might ask what does ControlNet SoftEdge which is a variant of ControlNet do? It focuses on extracting edges from images to create a sketch-like representation. It excels at extracting line drawings from diverse patterns. The selective extraction process ensures the preservation of intricate details, remaining unaffected by noise.ControlNet SoftEdge first extracts contour lines and edges from the input image and then proceeds to colorize it, generating the final image.
In essence, we have a model that provides precision and control over the finer details of the existing image.
Best settings for Controlnet SoftEdge
Steps
This parameter refers to the number of denoising steps. In the process of generating images, initiated by a random noise generated from text input, the model undergoes a repeated cycle. As the cycle progresses, each step involves the removal of some noise, resulting in a gradual improvement in image quality. Higher steps tend to generally produce high-quality images but do keep in mind that the time taken to generate images will also extend.

Prompt : Anime styled woman

The generation of high-quality images is observed when the number of steps is in the range of 50 to 70. Beyond this range, there is no significant difference in the quality of images being generated. However the image tends to undergo repeated changes, it is worth noting that the quality of the details improves in this particular range.
When the number of steps is set to range below 30, the quality is quite low and lacks depth.
Guidance Scale
These parameters play an important role in influencing the image generation process which decides the adherence to the prompt. It acts as a fundamental element in ensuring that the image generated aligns closely with the prompts specified. higher value assigned to the guidance scale strengthens the connection between the generated image and the input prompt. However, this heightened connection comes at the cost of reduced diversity and overall image quality.

Prompt : Beautiful American woman with long hair in 20's

We get to see how the details are amplified to the extent that the images rendered are extremely distorted and lack clear quality when the guidance scale value is increased beyond the range of 20.

Prompt : stylish portrait of woman in cyberpunk styled outfit with loose hair , 8k , well defined eyes , gorgeous

In this particular image, where we aim to render a woman in a cyberpunk style, the impact of low guidance scale values becomes evident. A low guidance scale results in a lack of information from the input image, manifesting as irregular and partial details, particularly noticeable in the collar. On the other hand, when values surpass 20, the outcome tends to be excessively smooth, lacking the desired depth.

Prompt : A samurai warrior , fierce looking , detailed , realistic , illustrated by ghibli studios

The optimal range for the guidance scale value in this model falls between 9 and 16. Within this range, there is a noticeable emphasis on highlighting intricate details. For individuals aiming to generate images rich in tiny details, as outlined in the prompt, it is advisable to select values within this specific range. Values below this range tend to result in excessively smooth images, while values above may lead to occasional distortions and extreme definition issues in the generated image.
Strength
This parameter refers to the degree of transformation applied to the reference image. While the guidance scale underscores the importance of adhering to the provided prompt, this parameter specifically concentrates on aligning with the characteristics of the input image. Its role is crucial in rendering an image that closely mirrors the details of the input image provided by us.

Prompt : Illustration of high-tech city, extremely defined, attention to detail, heartwarming art

The impact of the strength parameter becomes evident when observing its influence on adherence to the input image. Lower values of the strength parameter result in a lack of conformity to the input image, resulting in varied outcomes based on the model's interpretation of the input prompt. Meanwhile, higher values of this parameter lead to increased adherence to the provided input image.
The optimal range for this parameter is considered to be between 5 and 10, with 10 representing the maximum level of adherence.
Negative prompts
Negative prompts allow users to define the kind of image they would not like to see while the image is generated without providing any input. These prompts serve as a guide to the image-generation process, instructing it to exclude certain elements based on the user-provided text.
By utilizing negative prompts, users can effectively prevent the generation of specific objects, and styles, address image abnormalities, and enhance overall image quality.
Examples of commonly used negative prompts :
- Basic negative prompts: worst quality, normal quality, low quality, low res, blurry, text, watermark, logo, banner, extra digits, cropped, jpeg artifacts, signature, username, error, sketch, duplicate, ugly, monochrome, horror, geometry, mutation, disgusting.
- For Adult content: NSFW, nude, censored.
- For realistic characters: extra fingers, mutated hands, poorly drawn hands, poorly drawn faces, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, a long neck.

prompt : 4d photographic image of full body image of a cute little chibi boy realistic, vivid colors octane render artistic photography, photorealistic concept art, soft natural volumetric cinematic perfect light, UHD no background

Schedulers
Schedulers are specialized algorithms integral to the denoising process within the Stable Diffusion pipeline. These algorithms operate by iteratively applying denoising steps to the input data, incrementally introducing and removing random noise during each iteration. This iterative approach contributes to a gradual enhancement in image quality, producing visibly clearer and cleaner images.
Among the various schedulers, UniPC, and Euler a are highly recommended.
Conclusion
When it comes to enhancing your images, Segmind’s ControlNet SoftEdge model is the top choice. This model goes beyond the ordinary, putting a strong emphasis on preserving features while gently refining brush strokes. The outcome is not just visually captivating but also rich in depth and subtlety.
In this blog, we got to explore the versatile capabilities of the ControlNet SoftEdge model. It doesn't just improve image quality; it extends the visual narrative. We also got to discover insights into the optimal settings that enhance the image generation process.