Generate, upscale, blur, and enhance with Stable Diffusion 1.5 Img2Img
Released in 2022, Stable Diffusion 1.5 Img2Img is a revolutionary deep-learning model that's redefining and driving innovation in the field of photo-realistic image generation.

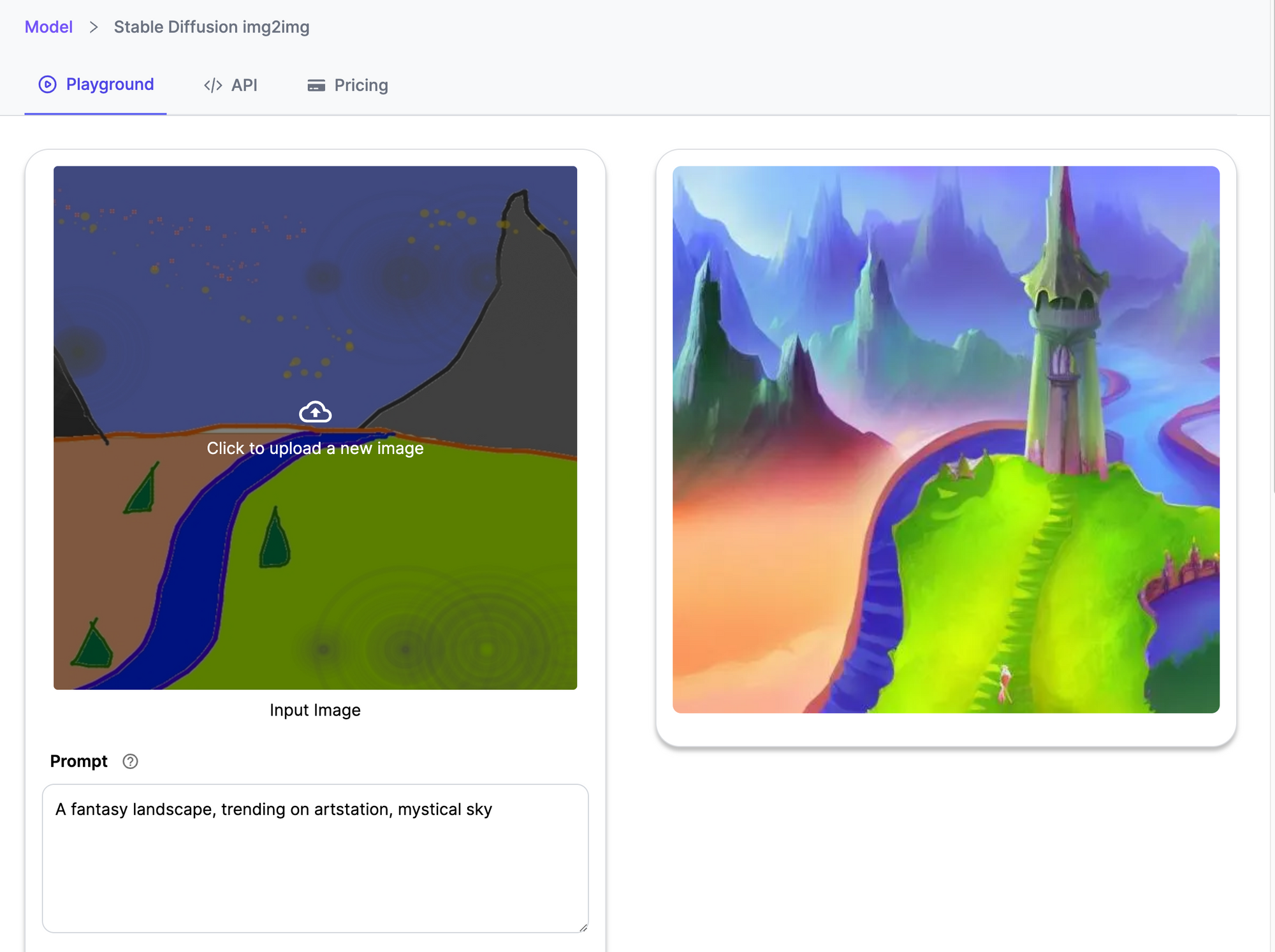
Released in 2022, Stable Diffusion 1.5 Img2Img is a revolutionary deep-learning model that's redefining and driving innovation in the field of photo-realistic image generation. The model offers a wide range of capabilities, its primary function being to generate detailed images from text descriptions, inpainting and outpainting tasks, and image-to-image translations guided by text prompts.
Stable Diffusion 1.5 Img2Img: Under the Hood
The model's capabilities extend beyond simple image generation to image upscaling, enhancing resolution, compression, and generating finer details. Built on a sophisticated architecture that fuses an auto-encoder with a diffusion model trained in the auto-encoder's latent space, the process begins once the encoder starts transforming input images into latent representations, with a relative downsampling factor of 8.
The ViT-L/14 text-encoder is responsible for encoding text prompts, and the non-pooled output of the text encoder into the latent diffusion model's UNet backbone via cross-attention. The model's loss function is a reconstruction objective between the noise added to the latent space and the UNet's prediction.
The strength value parameter also plays a crucial role here, as it determines the amount of noise added to the generated image. Higher values result in greater variation, however, in some cases may impact semantic consistency with the text prompt.
To learn more about how the model works, check out the official Stable Diffusion blog.
Applications and Advantages of Stable Diffusion 1.5 Img2Img
Stable Diffusion 1.5 Img2Img offers powerful options for resolution enhancement and adding finer details or noise to images. Its unique approach of combining text prompts and images with a strength value lets users create unique, rich, and visually appealing images that contextually blend a text prompt with the true essence of the original image. Additionally, its potential for image upscaling and compression widens the scope for image manipulation.
From enhancing visual content to facilitating research and data analysis, Stable Diffusion 1.5 Img2Img caters to diverse industry needs:
- Image-to-Image Translations: The model's ability to generate new images based on a text prompt and an existing image opens up endless possibilities for creative projects and artistic endeavors.
- Data Anonymization: Protect sensitive information by adding noise to original images. The model alters and anonymizes visual features of image data without compromising data analysis and modeling.
- Data Augmentation: Machine learning tasks often involve the use of large image databases. Stable Diffusion 1.5 Img2Img facilitates data augmentation by altering and enhancing image data to provide rich and diverse datasets for training and research purposes.
- Image Upscaling: Increase the resolution of images without sacrificing quality. Stable Diffusion Img2Img provides high-end image upscaling capabilities, breathing new life and finer details into low-resolution images.
- Image Compression: Data storage and transmission rely heavily on efficient image compression. While optimization is still underway to better preserve small text and faces, the model performs impressively as an image compression tool.
Get Started with Stable Diffusion 1.5 Img2Img
Running the Stable Diffusion 1.5 Img2Img model locally with the necessary dependencies can be computationally exhaustive and time-consuming. That’s why we have created free-to-use AI models like ControlNet Canny and 30 others. To get started for free, follow the steps below.
- Create your free account on Segmind.com
- Once you’ve signed in, click on the ‘Models’ tab and select ‘Stable Diffusion 1.5 Img2Img'
- Upload the image you wish to manipulate
- Enter your text prompt detailing the required output
- Click ‘Generate’
- Witness the magic of Stable Diffusion 1.5 Img2Img in action!
Stable Diffusion 1.5 Img2Img License
The Stable Diffusion 1.5 Img2Img model is licensed under the Creative ML OpenRAIL-M license, a form of the Responsible AI License (RAIL). Under this license, while users retain the rights to their generated output images and are free to use them commercially, the license prohibits certain use cases, including crime, libel, harassment, doxing, exploiting minors, giving medical advice, creating legal obligations automatically, producing legal evidence, and discriminating against or harming individuals or groups based on social behavior, personal characteristics, or legally protected categories.