Deeplab V3 for Semantic Image Segmentation
In our quest to provide you with the state of the art networks for various tasks in computer vision , we have added Deeplab V3 and Unet-8 in the latest version of our Segmind Edge library.


Task of classifying every pixel into lables such as "sky" or "land" is known as Semantic Image Segmentation. This has enabled numerous new applications such as detecting background in an image, detecting buildings on aerial imagery, segmenting important objects for autonomous driving etc. The challenege here is to precisely detect the outline of the region of interest, and thus requires much higher localization accuracy compared to image classification and detection (bounding box) tasks.
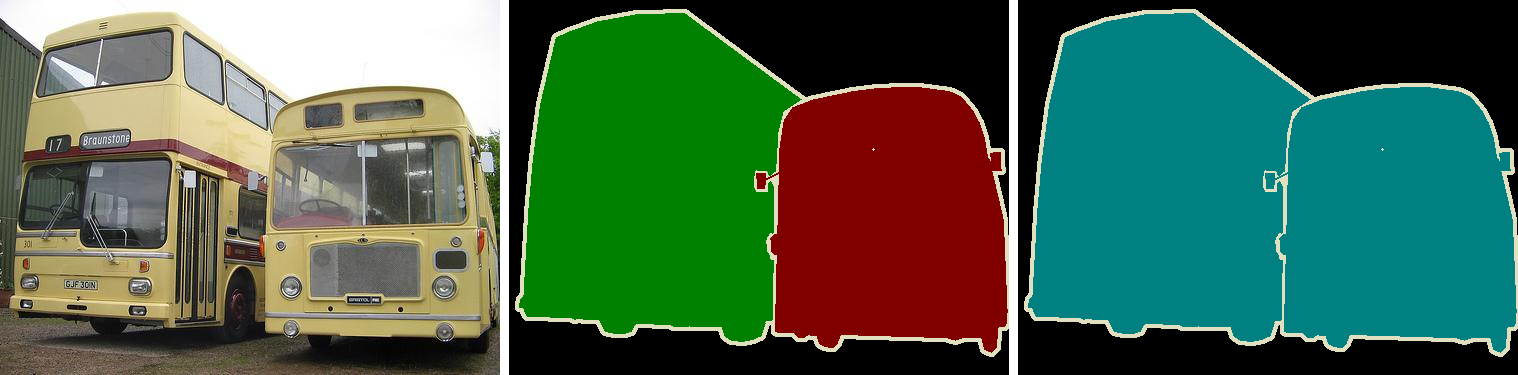
What is Deeplab V3?
Researchers Liang-Chieh Chen et al. released the paper Rethinking Atrous Convolution for Semantic Image Segmentation that employs atrous convolution to learn better at multiple image scales. Atrous spatial pyramid pooling module augmented with image-level features probes the features with filters at multiple sampling rates and effective field-of-views to achive this. Deeplab utilizes several Atrous Convolutions at multiple rates for a larger feild of view. This has significantly improved the overall accuracy compared to the pevious Deeplab versions (v1 & v2), and in princle removed the need of DenseCRF post-processing that is typically used to improve outline quality.
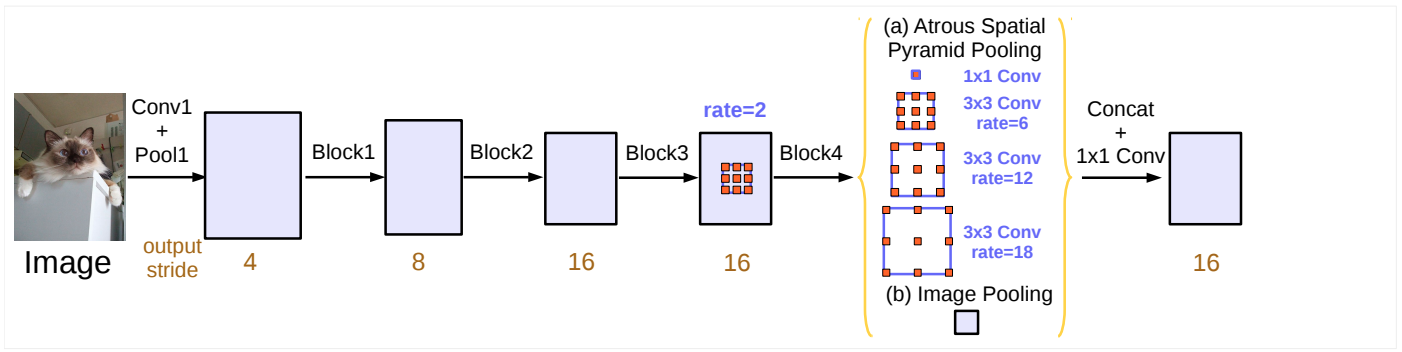
Atrous Spatial Pyramid Pooling (ASPP) is used as the context module for context extraction at multiple scales. In a context module, there are extra modules laid out in cascade to encode long range context. Here, these extra modules are described as below :
- branch-1: one 1×1 convolution with 256 filters and batch normalization
- branch-2, branch-3, branch-4: three 3×3 convolutions with rates = (6, 12, 18) when output stride = 16. Rates are doubled when output stride = 8, i.e (12, 24, 36). with 256 filters and batch normalization
- branch-5 : feature map is global average pooled, then fed to a 1x1 convolution with 256 filters and batch normalization. This is then resized with bilinear upsampling to fit desired resolution, so that it can be concatenated with the above branches. This branch is necessary because for higher atrous rates (closer to dimension of feature map) effective kernel weights decreases.
The resulting features from all the 5 branches as stated above are then concatenated and pass through another 1×1 convolution (also with 256 filters and batch normalization) before the final 1×1 convolution with filter_size = number of classes, which generates the final logits. This is the context module.
Dilated a.k.a. Atrous convolutions along with deep CNNs have achived significant improvement in accuracy. Choosing the dilation rate for on multi-grid ASPP (branch 2, 3 & 4) is not very intutive. For example, for a feature map of 65x65, if the atrous rate is also set to 65, then a 3x3 kernel, instead of capturing the whole image context, degenerates to a simple 1x1 kernel since only the center weight is effective.
Constant atrous rate is not recommended.
Hyperparameters
Output Strides
Output stride is the ratio of input image spatial resolution to final output resolution. For example, If image input resolution is 512x512 and feature map resolution is 16x16, then output stride is (32,32). The official paper suggests 16 as the optimal output stride value.
Atrous rates
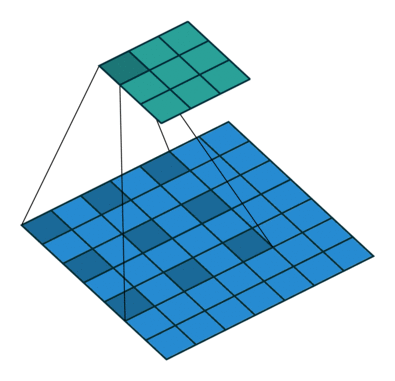
In Atrous convolution, holes (filter values with weight values 0) are inserted in between kernels to "inflate", which is then used for convolution operation. For say, atrous rate = 2, one black pixel is introduced between two consecutive filter values.
Formula for effective kernel dimension:
$$\hat{k} = k+(k-1)(r-1)$$
where,
- k is original kernel dimension
- r is atrous rate/dilation rate
When atrous rate = 1, it corresponds to traditional convolution.
Hence, the new output resolution is given by:
$$H = floor(h+2p-\hat{k}/s)+1$$
where,
- p is padding value
- k hat is the effective kernel value, calculated using the formula mentioned above
- s is stride
To get started with Deeplab V3, refer to the Segmind Edge documentation.
If anyone of your peers need to use Deeplab V3 in their research labs, startups, and/or companies do get in touch with us for an early access to the products we are building at contact@segmind.com.