CodeFormer vs ESRGAN (GFPGAN): Enhance faces
We embarked on a comparative journey between two prominent AI models, Codeformer and ESRGAN, to assess their prowess in face restoration. Using a diverse set of images, ranging from AI-generated faces to vintage photographs of iconic figures


Although both CodeFormer and ESRGAN models weren't built for the same use case, integration of GFPGAN into default ESRGAN implementation to support face enhancement has given rise to two potential workflows for enhancing AI-generated faces. You can now use both to see which one works best for your image. Let us quickly compare their architecture and approaches and look at the team behind them before we look at their outputs.
Codeformer is a groundbreaking approach to blind face restoration, developed by the ingenious team of AI researchers at S-Lab, Nanyang Technological University in Singapore. This method leverages a discrete representation space, focusing on enhancing degraded inputs by modeling the global composition of natural faces using a Transformer module. On the other hand, GFPGAN is a notable face restoration technique, conceived by the AI researchers at Tencent. While GFPGAN harnesses generative facial priors from pre-trained generators, such as StyleGAN2, for restoration, it faces challenges in preserving high fidelity in the restored faces, especially when dealing with heavily degraded inputs.
Blind Face Restoration Methods
Blind face restoration has always been a critical challenge in the domain of image processing and computer vision. Historically, the intrinsic structured nature of faces inspired many algorithms to exploit geometric priors of faces for restoration. Methods were developed to integrate facial landmarks, face parsing maps, component heatmaps, and even 3D facial structures. These methods, however, often faced limitations when working with severely degraded faces since extracting accurate prior information from such faces was near impossible. To counter these limitations, reference-based approaches emerged. In these methods, a high-quality image of the same identity as the degraded face was utilized to guide the restoration process. But the challenge was that such high-quality references were not always available, leading to alternative techniques like the DFDNet which pre-constructed dictionaries composed of high-quality facial component features.
GFPGAN and Its Limitations
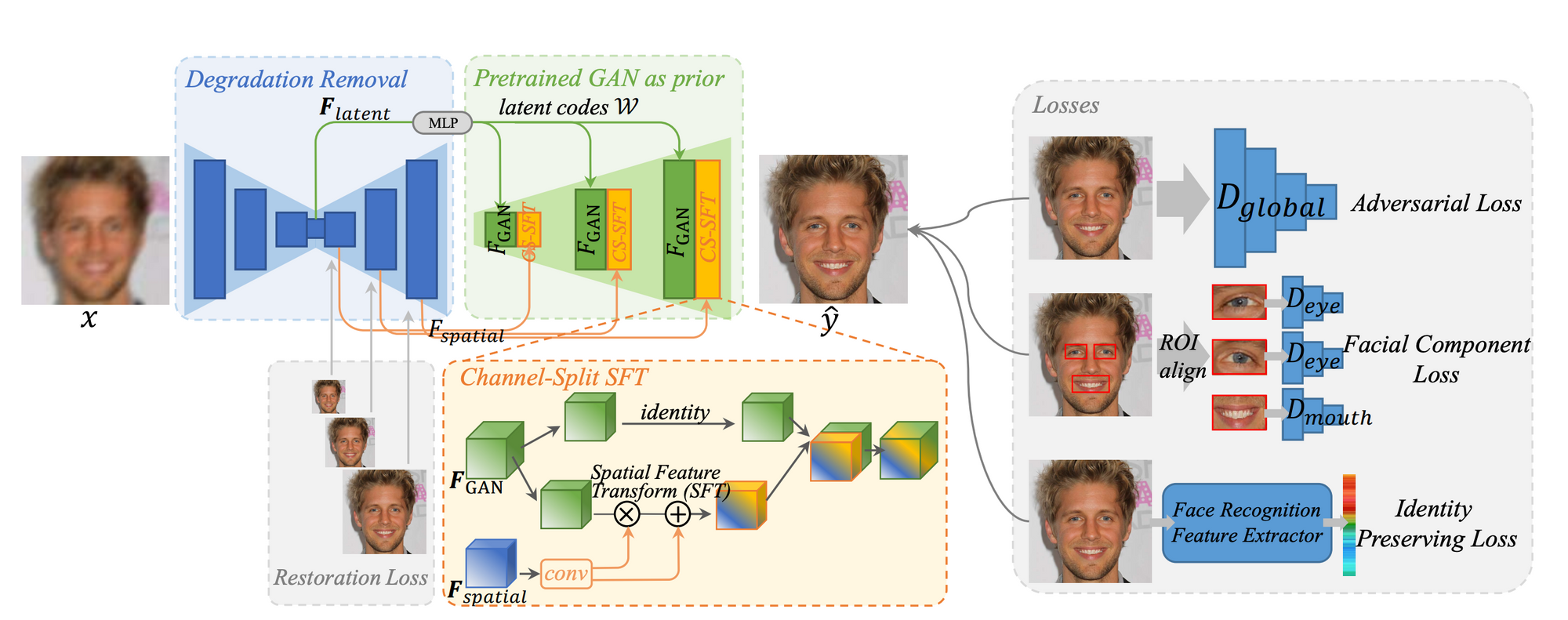
GFPGAN emerged as a significant development in the blind face restoration landscape. At its core, it taps into the generative facial priors from pre-trained generators such as StyleGAN2. These priors were widely explored via different strategies, either by iterative latent optimization for GAN inversion or by directly encoding the degraded faces. The challenge with GFPGAN, however, was preserving the high fidelity of the restored faces when these faces were projected into a vast, continuous latent space. While GFPGAN tried to address this by embedding the generative prior within encoder-decoder networks and integrating additional structural input information for guidance, they relied heavily on inputs through skip connections. This approach could inadvertently introduce artifacts into the results, especially when the original input faces were heavily corrupted.
Codeformer's Framework and Technical Architecture
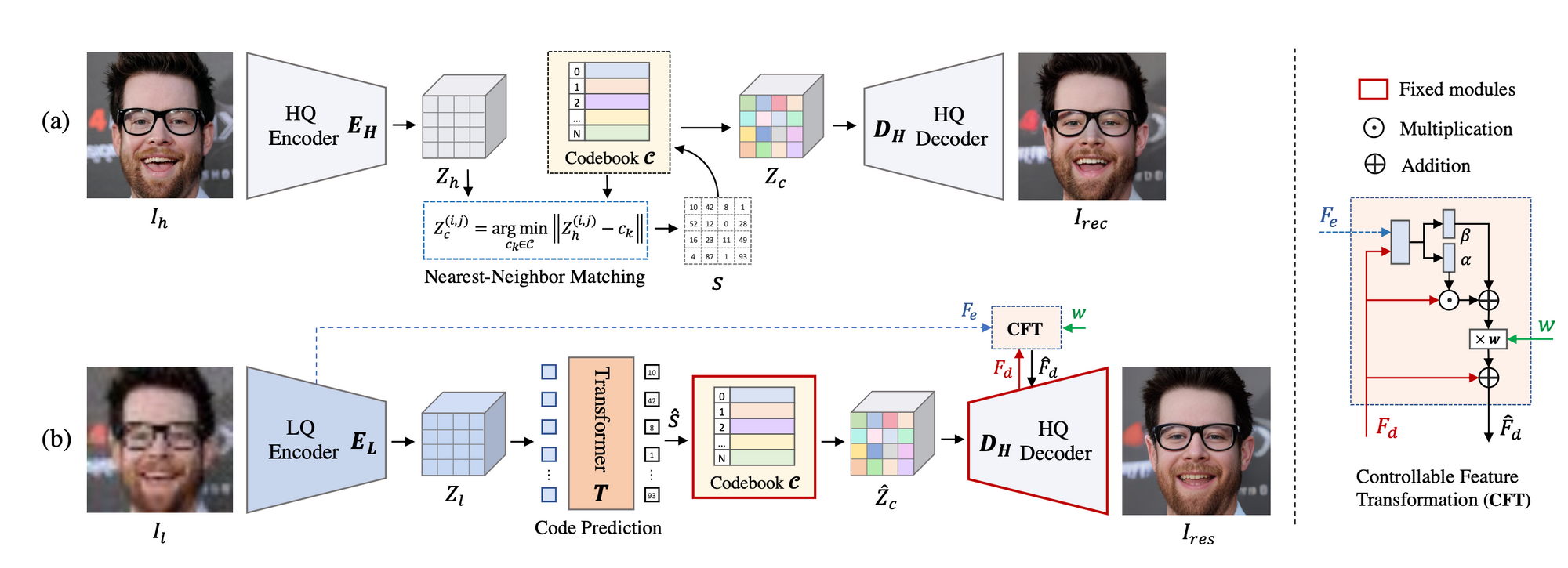
Codeformer presents a paradigm shift in the world of blind face restoration by primarily emphasizing a discrete representation space. This discrete space reduces the uncertainty generally observed in restoration mappings and adds enhanced details to degraded inputs. The initial step in Codeformer's framework is to learn a discrete codebook and a decoder, capturing high-quality facial visual parts through self-reconstruction learning. Post this, with a fixed codebook and decoder in place, a Transformer module is introduced. This module predicts the code sequence and models the global face composition of low-quality inputs. Additionally, Codeformer introduces a controllable feature transformation module, which offers a balancing act between restoration quality and fidelity, ensuring that the algorithm can adapt based on the severity of degradation in the input images.
The Theoretical Superiority of Codeformer over GFPGAN
At a theoretical level, Codeformer stands out from GFPGAN in several ways. While GFPGAN has its roots in continuous latent space, Codeformer's essence lies in its discrete representation space, which inherently reduces restoration uncertainty. This discrete approach ensures that local textures and details, which might be lost in GFPGAN's continuous approach, are better preserved. The incorporation of the Transformer module in Codeformer allows for enhanced modeling of the global composition of natural faces, remedying the local information loss and facilitating superior quality restoration. Moreover, Codeformer’s flexibility, facilitated by its controllable feature transformation module, ensures that the restoration process is adaptable. This adaptability means that when inputs are severely degraded, the adverse effects seen in methods like GFPGAN can be avoided, and there's a balance between restoration quality and fidelity.
ESRGAN + GFPGAN: Enhancing GFPGAN with Super-Resolution
When introducing the element of super-resolution to GFPGAN, the narrative begins to shift dramatically. Super-resolution, with its power to upscale and enhance image details, has the potential to compensate for some of the inherent challenges faced by GFPGAN, potentially allowing it to match or even surpass the quality delivered by Codeformer. It's essential to evaluate this enhanced version of GFPGAN across a spectrum of image types. Comparing its performance on old photographs, which often come with unique degradation challenges, to its efficacy on AI-generated images can offer a holistic understanding of its prowess. For a tangible and more transparent assessment, we'll juxtapose a few examples side-by-side, diving deep into the qualitative differences between the outputs of these two methodologies.
Sample outputs
AI-Generated photos
We embarked on an intriguing experiment using the advanced face generator AI model, Segmind Tiny-SD (Portrait), to critically assess and compare the capabilities of ESRGAN and Codeformer in the realm of face restoration. The Segmind Tiny-SD (Portrait) stands out due to its reliance on Knowledge Distillation (KD) in its operational framework. This methodology is reminiscent of a teacher-student relationship where a robust, pre-trained model (acting as the teacher) guides a more compact model (the student) during its training phase. The dataset of choice comprised 7,000 meticulously curated portrait images. The allure of the Segmind Tiny-SD model is not just its efficient size but its promise of delivering results at lightning speed without compromising on the quality of the output. Such attributes deem it perfect for generating faces to test our subjects of interest.

In our empirical trials, we fine-tuned the settings of both models to optimize the outcome. ESRGAN was adjusted to a 2x zoom setting, a choice we made to accentuate the face enhancement capabilities rather than merely the super-resolution effects. On the other hand, Codeformer was equipped with a specific configuration, namely "scale": 1, "fidelity": 0.5, "bg": 1, and "face": 1. Analyzing the results led us to some insightful observations. Codeformer, despite producing clearer images, exhibited a propensity to modify the inherent facial structure, at times so significantly that the outcome bore scant resemblance to the original. ESRGAN, in stark contrast, managed to uphold the integrity of the facial structure. Moreover, it showcased superior efficiency by consuming just half of the GPU compute time as compared to its counterpart, Codeformer.

Drawing from our findings, it is evident that ESRGAN emerges as the more favorable choice, especially when the goal is to enhance AI-generated faces. The dual advantage of preserving the original facial structure and being more computationally efficient gives it a discernible edge. However, the journey doesn't end here. Recognizing the potential of these technologies and the nuances they bring forth, we are fueled to delve even deeper. Our future endeavors will involve experimenting with an array of settings, aiming to fine-tune the outputs and push the boundaries of what's achievable. Our commitment to this research area remains unwavering, and we eagerly look forward to sharing more evolved insights and breakthroughs as we continue our exploration.
Old Photos
Venturing beyond AI-generated faces, we decided to subject a tangible, real-world image to our comparative experiment: an old photograph of the iconic Bollywood actor, Amitabh Bachchan. This choice posed an entirely different set of challenges, given the unique characteristics and imperfections old photos tend to possess, making the task of restoration even more nuanced. We were eager to see how ESRGAN and Codeformer would fare when confronted with this test, especially considering their earlier performances on AI-synthesized images.

The results were telling. ESRGAN, true to its previous performance, not only enhanced the resolution of the photo but also brilliantly preserved the distinctive features of Amitabh Bachchan. The restored image, while clearer, retained the essence and recognizability of the legendary actor. Codeformer, however, struggled in this arena. Despite its improvement in clarity, the alterations to the facial structure were so drastic that the end result bore little resemblance to Amitabh Bachchan. The stark transformation rendered by Codeformer highlighted the challenges it faces in maintaining the integrity of original images, especially when handling vintage photographs with their unique degradations and characteristics.
Conclusion
While our experiments with Codeformer and ESRGAN have presented intriguing outcomes, it's essential to highlight the strengths of each model. Codeformer, though it had its challenges with certain images, is a formidable tool that has demonstrated exceptional performance on a multitude of old photographs. Its nuanced architecture offers immense potential for restoration tasks. On the other hand, ESRGAN's prowess in maintaining the integrity of original images, particularly in our tests, has been commendable. As we continue our exploration of these advanced models, we'll delve deeper into optimizing their settings for varied scenarios. Stay tuned as we journey further into the captivating world of AI-driven image restoration and share our discoveries and insights.
We are committed to further exploring and fine-tuning its settings to harness its full potential. Rest assured, we'll keep our readers updated on the optimal configurations for Codeformer, ensuring the best possible outcomes in various scenarios.